标签:loss cat ace storage self efficient ppi earlier generated
转自:https://zeebe.io/what-is-zeebe/
Zeebe is a workflow engine for microservices orchestration.
This write-up will help you understand exactly what Zeebe is and how it might be relevant to you. We’ll start with a short introduction of Zeebe and the problem it solves, and then we’ll go into a lot more detail.
We’ll use the word “workflow” throughout the write-up, and depending on your background, you might not be familiar with the word in the context of microservices. When we say “workflow”, all we mean is “a sequence of tasks that allows us to achieve some goal.” “Workflow” could be used synonymously with “business process” or “process.”
In workflows orchestrated by Zeebe, each task is usually carried out by a different microservice.
A company’s end-to-end workflows almost always span more than one microservice. In an e-commerce company, for example, a “customer order” workflow might involve a payments microservice, an inventory microservice, a shipping microservice, and more.

These cross-microservice workflows are a company’s core revenue drivers, yet they’re rarely modeled and monitored; often, the flow of events through different microservices is expressed only implicitly in code.
If that’s the case, how can we ensure visibility of workflows and provide status and error monitoring? How do we guarantee that overall flows always complete, even if single microservices fail? Or how do we at least recognize that a flow is stuck so we can go in and fix it?
Zeebe is an open-source workflow engine for microservices orchestration that provides:
Zeebe was designed to solve the microservices orchestration problem at very large scale, and to achieve this, it provides:
You can learn more about these technical concepts in the documentation.
If that’s all you needed to see, and you think that Zeebe might be a good fit for you, we encourage you to give it a try. It’s available for download right now, and much of Zeebe is open source under the Apache 2.0 license. The quickstart is a great way to get hands-on without writing a line of code.
If you have questions, please reach out to the Zeebe community. You can post a question on the Zeebe forum or engage with Zeebe developers in our Slack channel. We’d love to hear from you.
And please note that Zeebe is currently a developer preview, meaning that it’s not yet ready for production and is under heavy development. You can see the roadmap here.
If you’d like to learn more about Zeebe, you can continue reading. In the rest of this post, we’ll cover 3 topics in more detail:
Microservices architectures have become increasingly popular in recent years, and for good reason. Focused, cross-functional teams can deliver value quickly and independently while working with a technology stack of their choice.
But the very principles that make microservices architectures so appealing–loose coupling, independent deployment cycles–also entail significant challenges.
A core tenet of the microservices architecture is that each microservice is responsible for only one business capability. We’ll refer again to the e-commerce example from the introduction, where one microservice is responsible for payment processing, another is responsible for inventory, another is responsible for shipping, and so on:

Each microservice exists to contribute to a broader workflow: getting a shopper what they want as quickly and efficiently as possible. And the company succeeds only when the end-to-end workflow is successful, so ensuring workflow quality is critical.
In a microservices architecture, where each microservice is responsible only for a carefully-scoped business capability, who’s responsible for the end-to-end workflow?
By default, no one. In fact, the end-to-end workflow might not even be formally documented within the company, with the flow of events from microservice to microservice expressed only implicitly in code.
Many microservices architectures rely on a pure choreography pattern for communication, where microservices collaborate by publishing events to and consuming events from a messaging platform without a central controller (a model also known as publish-subscribe, or pub-sub). And choreography does indeed provide developers of microservices with a degree of flexibility.
In its typical implementation, however, choreography does not provide:
Note: when we say “workflow instance”, we mean “a single occurrence of our workflow”. In the e-commerce example, a single workflow instance would be a single customer order.
Microservices architectures, therefore, are at risk of producing good software (at a microservice-level) but bad business outcomes. After all, it’s the success of the workflow that ultimately makes or breaks a business.
How can development teams reap the benefits of microservices architectures while ensuring robust end-to-end workflows?
That’s where Zeebe comes in.
Zeebe is a workflow engine. In case you’re new to workflow engines, here’s a general definition courtesy of Wikipedia:
A workflow engine is a system that manages business processes. It monitors the state of activities in a workflow and determines which new activity to transition to according to defined processes.
The label “workflow engine” has a legacy association with slow, low-throughput use cases such as human task management.
Zeebe, on the other hand, provides high throughput, low latency, and horizontal scalability. To explain why, let’s introduce a few of Zeebe’s key architectural concepts.
First, Zeebe does not require a central database component and instead leverages event sourcing, meaning that all changes to a workflow’s state are captured as events and stored in an append-only log. In Zeebe, this log is called a “topic”. Topics are written directly to the filesystem on the server where Zeebe is running, and the current state of a workflow can be derived from the events stored in a topic.
Topics can easily be distributed across nodes in a cluster (partitioning) for scalability, and partitions will typically be stored on more than one node (replication) for fault tolerance.
Zeebe uses a client / server model. The server (broker) is a remote engine that runs as its own program on a Java Virtual Machine. The broker is responsible for storing topics related to workflows, distributing work items to clients when appropriate, and exposing a workflow event stream to Zeebe clients via pub-sub. Zeebe clients can be embedded in an application in order to connect to the broker.
If you’ve worked with Apache Kafka, Apache Pulsar, or a similar messaging system, this architecture is probably familiar to you. If you’d like to learn more about Zeebe’s core concepts, please take a look at the documentation.
Now let’s talk about how Zeebe solves the end-to-end workflow problem in more practical terms. Zeebe enables users to:
In the following sections, we’ll discuss how to use Zeebe in a general sense and without code samples. In the future, we might share “blueprints” to demonstrate how exactly you can build these solutions yourself if the community would find it helpful.
Workflow-aware event monitoring is Zeebe’s answer to the visibility problem we defined above.
To recap:
Zeebe can work alongside the components you already use in your event-driven architecture without requiring you to replace or remove any existing systems to provide workflow visibility.
Here’s a simple diagram showing how Zeebe can be used for visibility into workflows that span microservices:
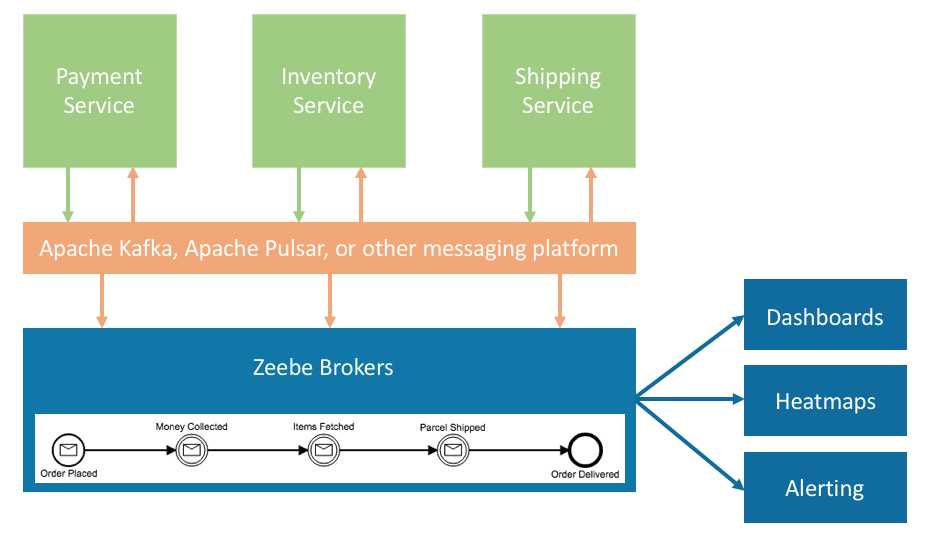
In this example, Zeebe subscribes to events that are published to your messaging platform and correlates them to your predefined workflow, which has been modeled visually in BPMN 2.0 and deployed to Zeebe brokers (to learn more about workflows in Zeebe, see the docs).
The workflow-relevant events processed by Zeebe can be used to power dashboards, to build heat maps uncovering problem areas in a workflow, and to build alerting tools when a workflow instance has a problem and needs attention.
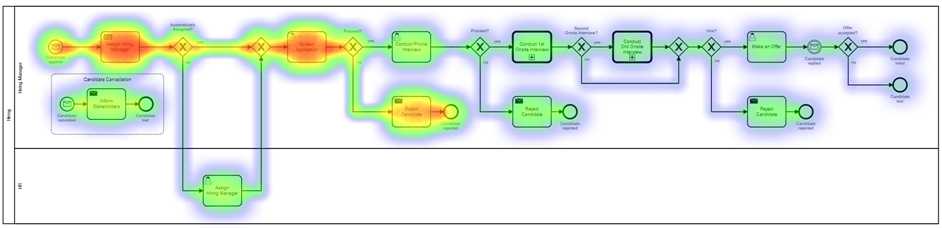
In this implementation, Zeebe goes beyond the scope of monitoring the health of an individual microservice and gives visibility into:
In this example, Zeebe operates purely as a “listener” and does not directly interact the microservices that participate in a workflow. Let’s talk about how to to extend this “visibility” solution to take advantage of Zeebe’s orchestration capabilities.
Microservices orchestration is Zeebe’s answer to the failure handling and retries problem we discussed earlier in this write-up.
In the microservices community, microservices orchestration is sometimes considered to be at odds with core microservices principles such as loose coupling and independent deployability. But that doesn’t have to be the case! Microservices orchestration can be implemented in a way that aligns with these principles, and Zeebe was designed accordingly.
The Zeebe docs say it best:
Zeebe applies publish-subscribe as an interaction model for orchestration. A service capable of performing a certain task in a workflow subscribes to this task and is notified via a message when work is available. Publish-subscribe gives a lot of control to the service: the service decides to which tasks it subscribes to and when to subscribe, and the service can even control processing rates. These properties make the overall system highly resilient, scalable, and reactive.
Here’s a simple diagram showing how Zeebe can be used for microservices orchestration:
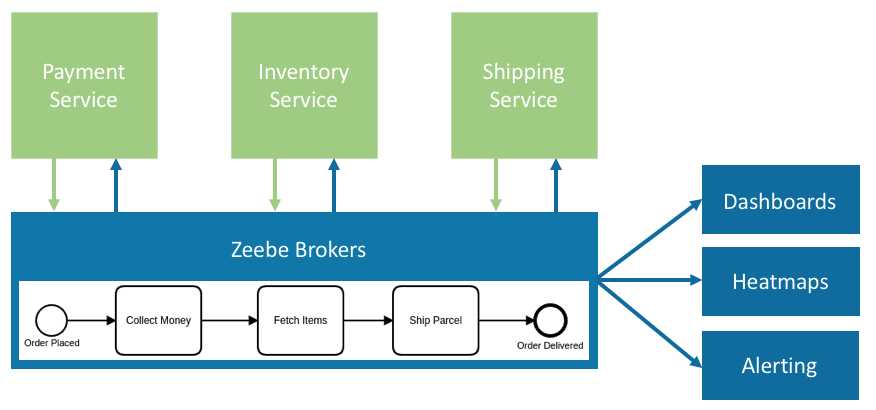
This architecture is very similar to to the “Zeebe for visibility” architecture we described above. A notable difference is that in our diagram, we’ve removed the messaging platform layer, and Zeebe communicates directly with the microservices that participate in a workflow.
It is still possible to use Zeebe for microservices orchestration without removing your existing messaging platform–in addition to subscribing to workflow-relevant events as illustrated in the “visibility” solution, Zeebe would simply publish events to the messaging platform, as well.
But Zeebe can also be used without a messaging platform, and we wanted to highlight that approach here.
You can think of Zeebe’s approach to workflow orchestration as a state machine. When a workflow instance progresses to a certain task, Zeebe sends a message to notify the responsible worker service then waits for the worker to complete the task.
Once a task is completed, the worker service notifies Zeebe, and the flow continues with the next step. If the worker fails to complete the task, the workflow remains at the current step, potentially retrying the task until it eventually succeeds or escalating to a different team if human intervention is required.
Zeebe decouples the creation of task notification messages from the actual performing of the work, meaning that Zeebe can send task notification messages at the maximum possible rate regardless of whether there is a worker service available to take on the work.
Zeebe queues task notifications until it can push them out to workers. If no worker service is currently available, work messages remain queued. If a worker service is subscribed, Zeebe’s backpressure protocols ensure that workers can control the rate at which they receive tasks.
This microservices orchestration approach still provides a full level of visibility into workflows and workflow instances while also ensuring that workflows are completed according to their definition, even when there are failures along the way.
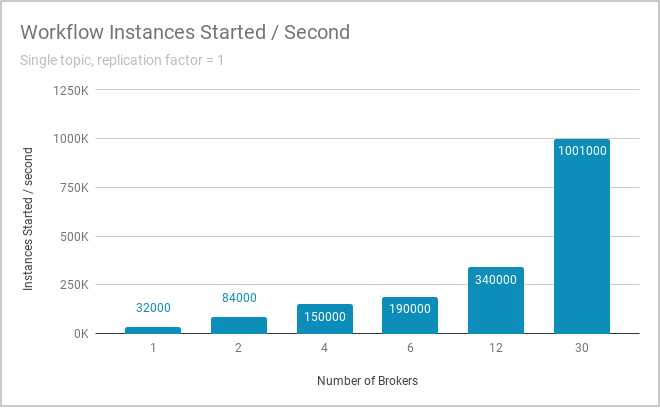
The ability to scale to handle high-throughput workloads is critical to Zeebe’s role in microservices orchestration. As event volume grows, it might become necessary to distribute Zeebe across a cluster of machines in order to meet throughput requirements. Zeebe uses partitioning to provide horizontal scalability, and according to our internal benchmarking, this is a very effective approach to scaling. You can see results of the benchmarks we run internally here and even run the benchmarks yourself.
Zeebe allows a user to configure a replication factor when creating a topic. The replication factor determines how many “hot standby” copies of a partition are stored on other brokers. If one broker goes down, another can replace it with no data loss. Because data is distributed across brokers in a cluster, Zeebe provides fault tolerance and high availability without the need for an external database, storing data directly on the filesystems in the servers where it’s deployed. Zeebe also does not require an external cluster orchestrator such as ZooKeeper. Zeebe is completely self-contained and self-sufficient.
ISO-standard BPMN 2.0 is the default modeling language for defining workflows in Zeebe. Workflows are defined visually and with full participation of both technical and non-technical stakeholders. While Zeebe’s coverage of BPMN symbols is not as comprehensive as that of a more mature BPM platform such as Camunda BPM, the Zeebe roadmap includes adding support for new symbols on a regular basis.
Currently, Zeebe provides two out-of-the-box clients in Java and Go. Zeebe clients are based on gRPC, meaning that a Zeebe client can be generated easily in many of the programming languages that organizations typically use to build microservices. A list of gRPC-supported programming languages is available here.
Zeebe brokers and clients communicate entirely via publish-subscribe, making it possible to adhere to the principle of loose coupling and to enable asynchronous communication between Zeebe and the microservices that participate in a workflow. Zeebe’s subscription protocol includes a backpressure mechanism to ensure that clients aren’t overloaded with work from Zeebe.
Zeebe exporters make it easy to stream workflow event data into a storage system so that this data can be available indefinitely. This is important for reporting and visibility, and depending on your industry, it might be necessary for regulatory reasons, too.
Yes, of course! We often talk about Zeebe in the context of the microservices orchestration use case because it’s a problem Zeebe solves really well, but Zeebe can be applied to use cases beyond microservices orchestration.
Zeebe is a workflow engine that handles a wide range of high-throughput use cases. Here are some of Zeebe’s general characteristics:
标签:loss cat ace storage self efficient ppi earlier generated
原文地址:https://www.cnblogs.com/rongfengliang/p/10352119.html