标签:开关 串行化 热点 资源 系统分析 mem 原因 ehcache 空值
缓存来由
随着互联网系统发展的逐步完善,为了提高系统的qps,目前的绝大部分系统都增加了缓存机制从而避免请求过多的直接与数据库操作从而造成系统瓶颈,极大的提升了用户体验和系统稳定性。缓存主要都存放到内存里面,访问速度比数据库查询快很多。
缓存衍生的六大新生的问题
使用缓存给系统带来了一定的质的提升,但同时也带来了一些需要注意的问题。如果不注意。会导致系统的瘫痪。所以须仔细处理。六大问题分别为:1.缓存穿透 2.缓存雪崩 3.缓存击穿 4.缓存预热 5.缓存降级 6.缓存更新
缓存穿透之问题
缓存穿透是指查询一个一定不存在的数据,因为缓存中也无该数据的信息,则会直接去数据库层进行查询,从系统层面来看像是穿透了缓存层直接达到db,从而称为缓存穿透,没有了缓存层的保护,这种查询一定不存在的数据对系统来说可能是一种危险,如果有人恶意用这种一定不存在的数据来频繁请求系统,不,准确的说是攻击系统,请求都会到达数据库层导致db瘫痪从而引起系统故障。
缓存穿透之方案
缓存穿透业内的解决方案已经比较成熟,主要常用的有以下几种:
bloom filter:类似于哈希表的一种算法,用所有可能的查询条件生成一个bitmap,在进行数据库查询之前会使用这个bitmap进行过滤,如果不在其中则直接过滤,从而减轻数据库层面的压力。guava中有实现BloomFilter算法
空值缓存:一种比较简单的解决办法,在第一次查询完不存在的数据后,将该key与对应的空值也放入缓存中,只不过设定为较短的失效时间,例如几分钟,这样则可以应对短时间的大量的该key攻击,设置为较短的失效时间是因为该值可能业务无关,存在意义不大,且该次的查询也未必是攻击者发起,无过久存储的必要,故可以早点失效。
缓存雪崩之问题
在普通的缓存系统中一般例如redis、memcache等中,我们会给缓存设置一个失效时间,但是如果所有的缓存的失效时间相同,那么在同一时间失效时,所有系统的请求都会发送到数据库层,db可能无法承受如此大的压力导致系统崩溃。
缓存雪崩之方案
线程互斥:只让一个线程构建缓存,其他线程等待构建缓存的线程执行完,重新从缓存获取数据才可以,每个时刻只有一个线程在执行请求,减轻了db的压力,但缺点也很明显,降低了系统的qps。
交错失效时间:这种方法时间比较简单粗暴,既然在同一时间失效会造成请求过多雪崩,那我们错开不同的失效时间即可从一定长度上避免这种问题,在缓存进行失效时间设置的时候,从某个适当的值域中随机一个时间作为失效时间即可。关注Java技术栈微信公众号,在后台回复关键字:缓存,可以获取更多栈长整理的缓存系列技术干货。
缓存击穿之问题
缓存击穿实际上是缓存雪崩的一个特例,大家使用过微博的应该都知道,微博有一个热门话题的功能,用户对于热门话题的搜索量往往在一些时刻会大大的高于其他话题,这种我们成为系统的“热点“,由于系统中对这些热点的数据缓存也存在失效时间,在热点的缓存到达失效时间时,此时可能依然会有大量的请求到达系统,没有了缓存层的保护,这些请求同样的会到达db从而可能引起故障。击穿与雪崩的区别即在于击穿是对于特定的热点数据来说,而雪崩是全部数据。
缓存击穿之方案
二级缓存:对于热点数据进行二级缓存,并对于不同级别的缓存设定不同的失效时间,则请求不会直接击穿缓存层到达数据库。
这里参考了阿里双11万亿流量的缓存击穿解决方案,解决此问题的关键在于热点访问。由于热点可能随着时间的变化而变化,针对固定的数据进行特殊缓存是不能起到治本作用的,结合LRU算法能够较好的帮我们解决这个问题。那么LRU是什么,下面粗略的介绍一下,有兴趣的可以点击上面的链接查看.
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。最常见的实现是使用一个链表保存缓存数据,如下图所示
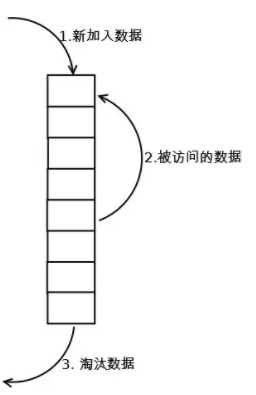
这个链表即是我们的缓存结构,缓存处理步骤为
首先将新数据放入链表的头部
在进行数据插入的过程中,如果检测到链表中有数据被再次访问也就是有请求再次访问这些数据,那么就其插入的链表的头部,因为它们相对其他数据来说可能是热点数据,具有保留时间更久的意义
最后当链表数据放满时将底部的数据淘汰,也就是不常访问的数据
LRU-K算法 ,其实上面的算法也是该算法的特例情况即LRU-1,上面的算法存在较多的不合理性,在实际的应用过程中采用该算法进行了改进,例如偶然的数据影响会造成命中率较低,比如某个数据即将到达底部即将被淘汰,但由于一次的请求又放入了头部,此后再无该数据的请求,那么该数据的继续存在其实是不合理的,针对这类情况LRU-K算法拥有更好的解决措施。结构图如下所示:
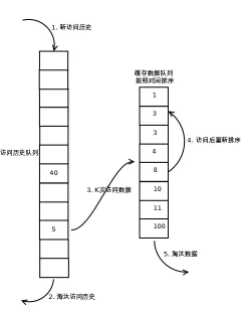
LRU-K需要多维护一个队列或者更多,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。关注Java技术栈微信公众号,在后台回复关键字:缓存,可以获取更多栈长整理的缓存系列技术干货。
第一步添加数据照样放入第一个队列的头部
如果数据在该队列里访问没有达到K次(该数值根据具体系统qps来定)则会继续到达链表底部直至淘汰;如果该数据在队列中时访问次数达到了K次,那么它会被加入到接下来的2级(具体需要几级结构也同样结合系统分析)链表中,按照时间顺序在2级链表中排列
接下来2级链表中的操作与上面算法相同,链表中的数据如果再次被访问则移到头部,链表满时,底部数据淘汰
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史,所以需要更多的内存空间来用来构建缓存,但优点也很明显,较好的降低了数据的污染率提高了缓存的命中率,对于系统来说可以用一定的硬件成本来换取系统性能也不失为一种办法。当然还有更为复杂的缓存结构算法,点击LRU算法即可学习,例如Two Queues和Mutil Queues等等,本文不过多赘述,只为读者提供一种解决思路。
缓存预热之问题
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据。
缓存预热之方案
1、直接写个缓存刷新页面,上线时手工操作下。
2、数据量不大,可以在项目启动的时候自动进行加载。
目的就是在系统上线前,将数据加载到缓存中。
缓存降级之问题
缓存降级就是利用ehcache等本地缓存(暂时使用),但主要还需要对源服务访问进行限流、资源隔离(熔断)、降级等。当访问量剧增、服务出现问题仍然需要保证服务还是可用的。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级,这里会涉及到运维的配合。降级的最终目的是保证核心服务可用,即使是有损的。
缓存降级之方案
在进行降级之前要对系统进行梳理,比如:哪些业务是核心(必须保证),哪些业务可以容许暂时不提供服务(利用静态页面替换)等,以及配合服务器核心指标,来后设置整体预案,比如:
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
(3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
(4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
缓存更新之问题
缓存更新是指若有多个操作都引起缓存的更新操作,会引起缓存的并发问题。
缓存更新之方案
其实redis自身就是单线程操作,多个client并发操作,按照先到先执行的原则,先到的先执行,其余的阻塞。当然,另外的解决方案是把redis.set操作放在队列中使其串行化,必须的一个一个执行。

标签:开关 串行化 热点 资源 系统分析 mem 原因 ehcache 空值
原文地址:https://www.cnblogs.com/lufeiludaima/p/pz20190205.html