标签:指标 技术 机器 分布 png stop 好的 验证 1.4
第一周
1.2 正交化
正交化:每一个维度只控制一个功能。
对于监督学习:1,在训练集上,达到评估的可接受效果;2,在验证集上有好的效果;3.在测试集有好的效果;4,系统在实际使用上表现得好。
在这四个部分,会有不同的独立按钮来控制实现更好的功能:1,训练集效果不好:增大神经网络,优化算法;2.在验证集上效果不好,正则化,增大训练集;3,.在测试集上效果不好:增大验证集;4.实际表现不好:改变验证集(验证集分布不正确),改变成本函数
提前终止(early stopping即会影响训练集还影响验证集,不够正交化)
1.3 --1.4单一数字评估指标
(如何判断系统是不是变得更好了,选出效果更好的分类器):把要考虑的指标合成一个单实数
查准率与查全率之间的折中:查准率,判断是猫的图片有多少真的是猫;查全率:在所有正在是猫的图片中被判断正确的比率(两者的分子都是系统判断是猫的图片,分母不一样);用F1指数:查准率和查全率调和平均数。
用一个指定的验证集,加上F1指数,能加快迭代速度。
有n个指标需要满足:设置单一数字评估:需要让取其中一个指标来尽量满足(尽量最高或者最低)+其他n-1个指标满足阈值即可。
1.5—1.6 数据集的划分
机器学习过程:在训练集上用不同的思路训练(不同的模型),然后用验证集来评估选择一个模型,然后不停地迭代去改善验证集的性能,最后得到一个最好的成本,拿去给测试集来评估。
让测试集和训练集来自同一个分布:
例子:把每个地区的数据随机混合在一起作为验证集和测试集
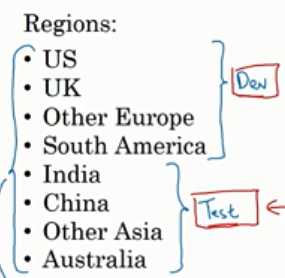
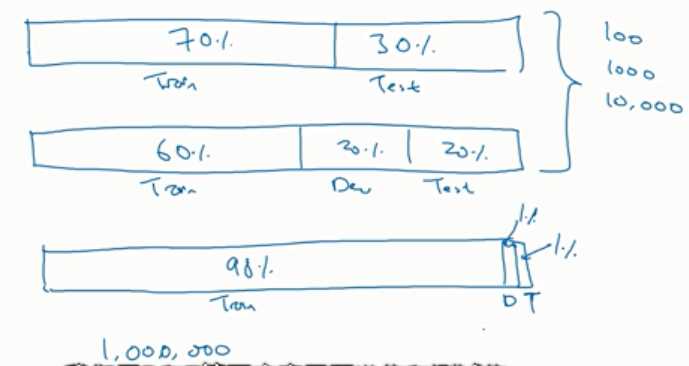
测试集的目的是具有一定置信度去评估,保证置信度就足够了不需要太大的数据集;而且有的时候不需要很高的置信度,所以只分为训练和验证,这时验证集被叫做开发集。
标签:指标 技术 机器 分布 png stop 好的 验证 1.4
原文地址:https://www.cnblogs.com/yttas/p/10354984.html