标签:集中 移动 style oid 决策 示例 距离 1.2 ec2
在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签,我们需要据此拟合一个假设函数。与此不同的是,在非监督学习中,我们的数据没有附带任何标签,我们拿到的数据就是这样的:
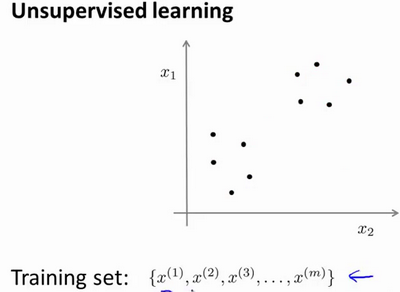
在非监督学习中,我们需要将一系列无标签的训练数据,输入到一个算法中,然后我们告诉这个算法,快去为我们找找这个数据的内在结构给定数据。我们可能需要某种算法帮助我们寻找一种结构。图上的数据看起来可以分成 两个分开的点集(称为簇),一个能够找到我圈出的这些点集的算法,就被称为聚类算法。
这将是我们介绍的第一个非监督学习算法。当然,此后我们还将提到其他类型的非监督学习算法,它们可以为我们找到其他类型的结构或者其他的一些模式,而不只是簇。
K-均值 是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
K-均值 是一个迭代算法,假设我们想要将数据 聚类成n个组,其方法为:
首先选择 K 个随机的点,称为聚类中心(cluster centroids);
对于数据集中的每一个数据,按照距离 K个中心点的距离,将其 与距离最近的中心点 关联起来,与 同一个中心点 关联的所有点聚成一类。
计算每一个组的平均值,将该组 所关联的中心点 移动到平均值的位置。
重复步骤2-4直至中心点不再变化。
下面是一个聚类示例:
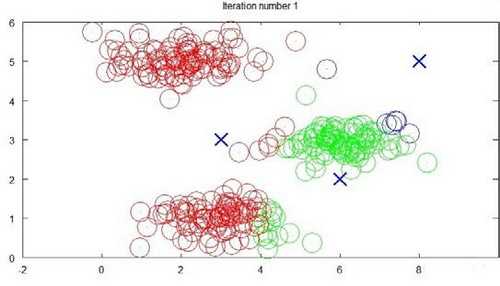
迭代 1 次
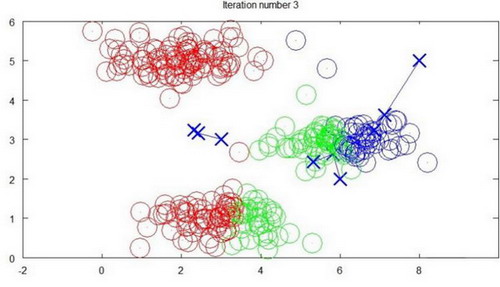
迭代 3 次
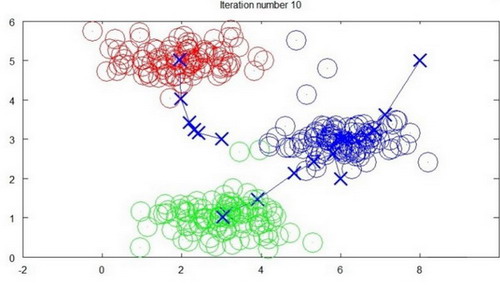
迭代 10 次
标签:集中 移动 style oid 决策 示例 距离 1.2 ec2
原文地址:https://www.cnblogs.com/douzujun/p/10356077.html