标签:opera sys 可扩展性 信息 number 分组 ble 要求 一个队列
ZooKeeper是一个高可用的分布式数据管理与系统协调框架。基于对Paxos算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基于这样的特性,使得ZooKeeper解决很多分布式问题。网上对ZK的应用场景也有不少介绍,本文将介绍比较常用的项目例子,系统地对ZK的应用场景进行一个分门归类的介绍。
值得注意的是,ZK并非天生就是为这些应用场景设计的,都是后来众多开发者根据其框架的特性,利用其提供的一系列API接口(或者称为原语集),摸索出来的典型使用方法。因此,也非常欢迎读者分享你在ZK使用上的奇技淫巧。
Zookeeper 会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统,如图所示:
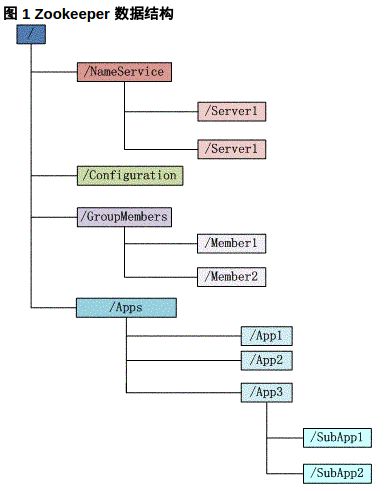
图中的每个节点称为一个znode. 每个znode由3部分组成:
stat. 此为状态信息, 描述该znode的版本, 权限等信息;
data. 与该znode关联的数据;
children. 该znode下的子节点;
Zookeeper 这种数据结构有如下这些特点:
每个子目录项如 NameService 都被称作为 znode,这个 znode 是被它所在的路径唯一标识,如 Server1 这个 znode 的标识为 /NameService/Server1;
znode 可以有子节点目录,并且每个 znode 可以存储数据,注意 EPHEMERAL 类型的目录节点不能有子节点目录;
znode 是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据;
znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个 session 失效,znode 也就删除了;
znode 的目录名可以自动编号,如 App1 已经存在,再创建的话,将会自动命名为 App2;
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是 Zookeeper 的核心特性,Zookeeper 的很多功能都是基于这个特性实现的,后面在典型的应用场景中会有实例介绍;
znode节点的状态信息:
使用get命令获取指定节点的数据时, 同时也将返回该节点的状态信息, 称为Stat. 其包含如下字段:
czxid. 节点创建时的zxid;
mzxid. 节点最新一次更新发生时的zxid;
ctime. 节点创建时的时间戳;
mtime. 节点最新一次更新发生时的时间戳;
dataVersion. 节点数据的更新次数;
cversion. 其子节点的更新次数;
aclVersion. 节点ACL(授权信息)的更新次数;
ephemeralOwner. 如果该节点为ephemeral节点, ephemeralOwner值表示与该节点绑定的session id. 如果该节点不是 ephemeral节点, ephemeralOwner值为0. 至于什么是ephemeral节点;
dataLength. 节点数据的字节数;
numChildren. 子节点个数;
?
zxid:
znode节点的状态信息中包含czxid和mzxid, 那么什么是zxid呢?
ZooKeeper状态的每一次改变, 都对应着一个递增的Transaction id, 该id称为zxid. 由于zxid的递增性质, 如果zxid1小于zxid2, 那么zxid1肯定先于zxid2发生. 创建任意节点, 或者更新任意节点的数据, 或者删除任意节点, 都会导致Zookeeper状态发生改变, 从而导致zxid的值增加.
session:
在client和server通信之前, 首先需要建立连接, 该连接称为session. 连接建立后, 如果发生连接超时, 授权失败, 或者显式关闭连接, 连接便处于CLOSED状态, 此时session结束.
节点类型:
讲述节点状态的ephemeralOwner字段时, 提到过有的节点是ephemeral节点, 而有的并不是. 那么节点都具有哪些类型呢? 每种类型的节点又具有哪些特点呢?
persistent. persistent节点不和特定的session绑定, 不会随着创建该节点的session的结束而消失, 而是一直存在, 除非该节点被显式删除.
ephemeral. ephemeral(临时)节点是临时性的, 如果创建该节点的session结束了, 该节点就会被自动删除. ephemeral节点不能拥有子节点. 虽然ephemeral节点与创建它的session绑定, 但只要该节点没有被删除, 其他session就可以读写该节点中关联的数据. 使用-e参数指定创建ephemeral节点.
create -e /xing/ei world
sequence. 严格的说, sequence(顺序)并非节点类型中的一种. sequence节点既可以是ephemeral的, 也可以是persistent的. 创建sequence节点时, ZooKeeper server会在指定的节点名称后加上一个数字序列, 该数字序列是递增的. 因此可以多次创建相同的sequence节点, 而得到不同的节点. 使用-s参数指定创建sequence节点.
[zk: localhost:4180(CONNECTED) 0] create -s /xing/item world
Created /xing/item0000000001
[zk: localhost:4180(CONNECTED) 1] create -s /xing/item world
Created /xing/item0000000002
[zk: localhost:4180(CONNECTED) 2] create -s /xing/item world
Created /xing/item0000000003
[zk: localhost:4180(CONNECTED) 3] create -s /xing/item world
Created /xing/item0000000004
?
watch:
watch的意思是监听感兴趣的事件. 在命令行中, 以下几个命令可以指定是否监听相应的事件.
ls命令. ls命令的第一个参数指定znode, 第二个参数如果为true, 则说明监听该znode的子节点的增减, 以及该znode本身的删除事件.
[zk: localhost:4180(CONNECTED) 21] ls /xing true
[]
[zk: localhost:4180(CONNECTED) 22] create /xing/item item000
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/xing
Created /xing/item
get命令. get命令的第一个参数指定znode, 第二个参数如果为true, 则说明监听该znode的更新和删除事件.
[zk: localhost:4180(CONNECTED) 39] get /xing true
world
cZxid = 0x100000066
ctime = Fri May 17 22:30:01 CST 2013
mZxid = 0x100000066
mtime = Fri May 17 22:30:01 CST 2013
pZxid = 0x100000066
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
[zk: localhost:4180(CONNECTED) 40] create /xing/item item000
Created /xing/item
[zk: localhost:4180(CONNECTED) 41] rmr /xing
WATCHER::
WatchedEvent state:SyncConnected type:NodeDeleted path:/xing
?
Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储,但是 Zookeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理,后面将会详细介绍 Zookeeper 能够解决的一些典型问题,这里先介绍一下,Zookeeper 的操作接口和简单使用示例。
客户端要连接 Zookeeper 服务器可以通过创建 org.apache.zookeeper.ZooKeeper 的一个实例对象,然后调用这个类提供的接口来和服务器交互。
前面说了 ZooKeeper 主要是用来维护和监控一个目录节点树中存储的数据的状态,所有我们能够操作 ZooKeeper 的也和操作目录节点树大体一样,如创建一个目录节点,给某个目录节点设置数据,获取某个目录节点的所有子目录节点,给某个目录节点设置权限和监控这个目录节点的状态变化。
ZooKeeper 基本的操作示例:
public class ZkDemo {
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
// 创建一个与服务器的连接
ZooKeeper zk = new ZooKeeper("127.0.0.1:2180", 60000, new Watcher() {
// 监控所有被触发的事件
// 当对目录节点监控状态打开时,一旦目录节点的状态发生变化,Watcher 对象的 process 方法就会被调用。
public void process(WatchedEvent event) {
System.out.println("EVENT:" + event.getType());
}
});
// 查看根节点
// 获取指定 path 下的所有子目录节点,同样 getChildren方法也有一个重载方法可以设置特定的 watcher 监控子节点的状态
System.out.println("ls / => " + zk.getChildren("/", true));
// 判断某个 path 是否存在,并设置是否监控这个目录节点,这里的 watcher 是在创建 ZooKeeper 实例时指定的 watcher;
// exists方法还有一个重载方法,可以指定特定的 watcher
if (zk.exists("/node", true) == null) {
// 创建一个给定的目录节点 path, 并给它设置数据;
// CreateMode 标识有四种形式的目录节点,分别是:
// PERSISTENT:持久化目录节点,这个目录节点存储的数据不会丢失;
// PERSISTENT_SEQUENTIAL:顺序自动编号的目录节点,这种目录节点会根据当前已近存在的节点数自动加 1,然后返回给客户端已经成功创建的目录节点名;
// EPHEMERAL:临时目录节点,一旦创建这个节点的客户端与服务器端口也就是 session 超时,这种节点会被自动删除;
// EPHEMERAL_SEQUENTIAL:临时自动编号节点
zk.create("/node", "conan".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("create /node conan");
// 查看/node节点数据
System.out.println("get /node => " + new String(zk.getData("/node", false, null)));
// 查看根节点
System.out.println("ls / => " + zk.getChildren("/", true));
}
// 创建一个子目录节点
if (zk.exists("/node/sub1", true) == null) {
zk.create("/node/sub1", "sub1".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("create /node/sub1 sub1");
// 查看node节点
System.out.println("ls /node => " + zk.getChildren("/node", true));
}
// 修改节点数据
if (zk.exists("/node", true) != null) {
// 给 path 设置数据,可以指定这个数据的版本号,如果 version 为 -1 怎可以匹配任何版本
zk.setData("/node", "changed".getBytes(), -1);
// 查看/node节点数据
// 获取这个 path 对应的目录节点存储的数据,数据的版本等信息可以通过 stat 来指定,同时还可以设置是否监控这个目录节点数据的状态
System.out.println("get /node => " + new String(zk.getData("/node", false, null)));
}
// 删除节点
if (zk.exists("/node/sub1", true) != null) {
// 删除 path 对应的目录节点,version 为 -1 可以匹配任何版本,也就删除了这个目录节点所有数据
zk.delete("/node/sub1", -1);
zk.delete("/node", -1);
// 查看根节点
System.out.println("ls / => " + zk.getChildren("/", true));