标签:不可 comment any size rest operator cal 框架 集群
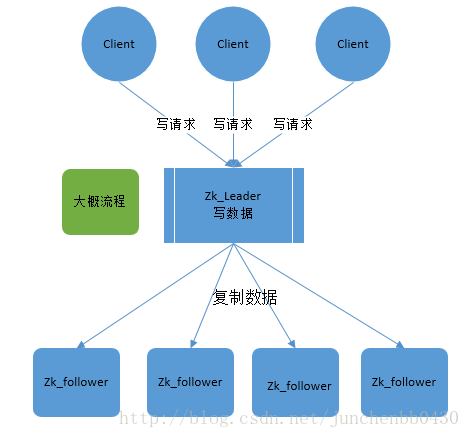
zookeeper根据ZAB协议建立了主备模型完成zookeeper集群中数据的同步。这里所说的主备系统架构模型是指,在zookeeper集群中,只有一台leader负责处理外部客户端的事物请求(或写操作),然后leader服务器将客户端的写操作数据同步到所有的follower节点中。
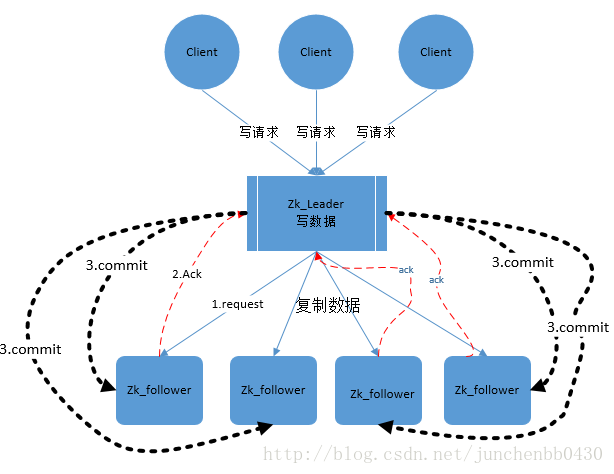
ZAB的协议核心是在整个zookeeper集群中只有一个节点即Leader将客户端的写操作转化为事物(或提议proposal)。Leader节点再数据写完之后,将向所有的follower节点发送数据广播请求(或数据复制),等待所有的follower节点反馈。在ZAB协议中,只要超过半数follower节点反馈OK,Leader节点就会向所有的follower服务器发送commit消息。即将leader节点上的数据同步到follower节点之上。 (先写在提交)
ZAB协议中主要有两种模式,第一是消息广播模式;第二是崩溃恢复模式
在zookeeper集群中数据副本的传递策略就是采用消息广播模式。zookeeper中数据副本的同步方式与二阶段提交相似但是却又不同。二阶段提交的要求协调者必须等到所有的参与者全部反馈ACK确认消息后,再发送commit消息。要求所有的参与者要么全部成功要么全部失败。二阶段提交会产生严重阻塞问题。
ZAB协议中Leader等待follower的ACK反馈是指”只要半数以上的follower成功反馈即可,不需要收到全部follower反馈”
图中展示了消息广播的具体流程图
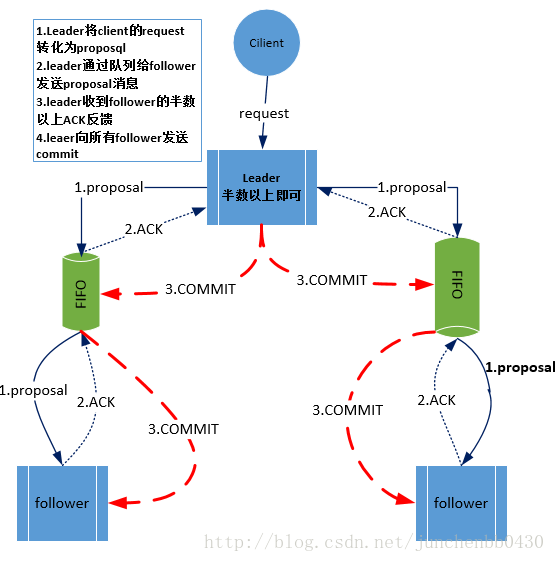
zookeeper中消息广播的具体步骤如下: 4.1. 客户端发起一个写操作请求 4.2. Leader服务器将客户端的request请求转化为事物proposql提案,同时为每个proposal分配一个全局唯一的ID,即ZXID。 4.3. leader服务器与每个follower之间都有一个队列,leader将消息发送到该队列 4.4. follower机器从队列中取出消息处理完毕(写入本地事物日志中)后,向leader服务器发送ACK确认。 4.5. leader服务器收到半数以上的follower的ACK后,即认为可以发送commit 4.6. leader向所有的follower服务器发送commit消息。
zookeeper采用ZAB协议的核心就是只要有一台服务器提交了proposal,就要确保所有的服务器最终都能正确提交proposal。这也是CAP/BASE最终实现一致性的一个体现。
leader服务器与每个follower之间都有一个单独的队列进行收发消息,使用队列消息可以做到异步解耦。leader和follower之间只要往队列中发送了消息即可。如果使用同步方式容易引起阻塞。性能上要下降很多。
zookeeper集群中为保证任何所有进程能够有序的顺序执行,只能是leader服务器接受写请求,即使是follower服务器接受到客户端的请求,也会转发到leader服务器进行处理。
如果leader服务器发生崩溃,则zab协议要求zookeeper集群进行崩溃恢复和leader服务器选举。
ZAB协议崩溃恢复要求满足如下2个要求: 3.1. 确保已经被leader提交的proposal必须最终被所有的follower服务器提交。 3.2. 确保丢弃掉leader服务器中的没有被提交的proposal。
根据上述要求,新选举出来的leader不能包含未提交的proposal,即新选举的leader必须都是已经提交了的proposal的follower服务器节点。同时,新选举的leader节点中含有最高的ZXID。这样做的好处就是可以避免了leader服务器检查proposal的提交和丢弃工作。
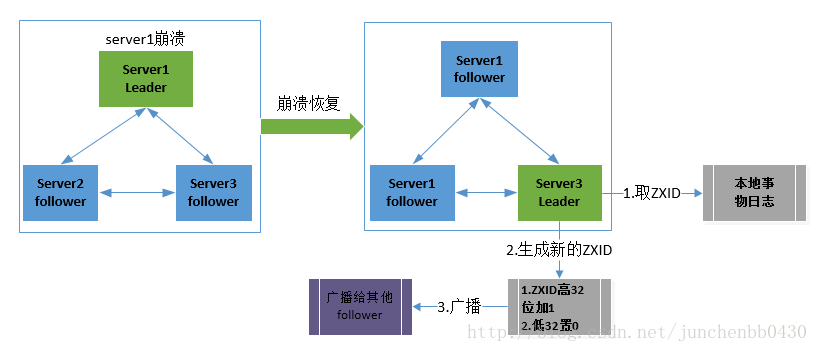
leader服务器发生崩溃时分为如下场景: 5.1. leader在提出proposal时未提交之前崩溃,则经过崩溃恢复之后,新选举的leader一定不能是刚才的leader。因为这个leader存在未提交的proposal。 5.2 leader在发送commit消息之后,崩溃。即消息已经发送到队列中。经过崩溃恢复之后,参与选举的follower服务器(刚才崩溃的leader有可能已经恢复运行,也属于follower节点范畴)中有的节点已经是消费了队列中所有的commit消息。即该follower节点将会被选举为最新的leader。剩下动作就是数据同步过程。
在zookeeper集群中新的leader选举成功之后,leader会将自身的提交的最大proposal的事物ZXID发送给其他的follower节点。follower节点会根据leader的消息进行回退或者是数据同步操作。最终目的要保证集群中所有节点的数据副本保持一致。
数据同步完之后,zookeeper集群如何保证新选举的leader分配的ZXID是全局唯一呢?这个就要从ZXID的设计谈起。 2.1 ZXID是一个长度64位的数字,其中低32位是按照数字递增,即每次客户端发起一个proposal,低32位的数字简单加1。高32位是leader周期的epoch编号,至于这个编号如何产生(我也没有搞明白),每当选举出一个新的leader时,新的leader就从本地事物日志中取出ZXID,然后解析出高32位的epoch编号,进行加1,再将低32位的全部设置为0。这样就保证了每次新选举的leader后,保证了ZXID的唯一性而且是保证递增的。
ZAB协议要求每个leader都要经历三个阶段,即发现,同步,广播。
发现:即要求zookeeper集群必须选择出一个leader进程,同时leader会维护一个follower可用列表。用于将来客户端可以和这些follower中的节点进行通信。
同步:leader要负责将本身的数据与follower完成同步,做到多副本存储。这样也是体现了CAP中高可用和分区容错。follower将队列中未处理完的请求消费完成后,写入本地事物日志中。
广播:leader可以接受客户端新的proposal请求,将新的proposal请求广播给所有的follower。
zookeeper作为当今最流行的分布式系统应用协调框架,采用zab协议的最大目标就是建立一个高可用可扩展的分布式数据主备系统。即在任何时刻只要leader发生宕机,都能保证分布式系统数据的可靠性和最终一致性。
深刻理解ZAB协议,才能更好的理解zookeeper对于分布式系统建设的重要性。以及为什么采用zookeeper就能保证分布式系统中数据最终一致性,服务的高可用性。
Zab与Paxos Zab的作者认为Zab与paxos并不相同,之所以没有采用Paxos是因为Paxos保证不了全序顺序: Because multiple leaders can propose a value for a given instance two problems arise. First, proposals can conflict. Paxos uses ballots to detect and resolve conflicting proposals. Second, it is not enough to know that a given instance number has been committed, processes must also be able to fi gure out which value has been committed. Paxos算法的确是不关心请求之间的逻辑顺序,而只考虑数据之间的全序,但很少有人直接使用paxos算法,都会经过一定的简化、优化。
Paxos算法优化 Paxos算法在出现竞争的情况下,其收敛速度很慢,甚至可能出现活锁的情况,例如当有三个及三个以上的proposer在发送prepare请求后,很难有一个proposer收到半数以上的回复而不断地执行第一阶段的协议。因此,为了避免竞争,加快收敛的速度,在算法中引入了一个Leader这个角色,在正常情况下同时应该最多只能有一个参与者扮演Leader角色,而其它的参与者则扮演Acceptor的角色。 在这种优化算法中,只有Leader可以提出议案,从而避免了竞争使得算法能够快速地收敛而趋于一致;而为了保证Leader的健壮性,又引入了Leader选举,再考虑到同步的阶段,渐渐的你会发现对Paxos算法的简化和优化已经和上面介绍的ZAB协议很相似了。
总结 Google的粗粒度锁服务Chubby的设计开发者Burrows曾经说过:“所有一致性协议本质上要么是Paxos要么是其变体”。这句话还是有一定道理的,ZAB本质上就是Paxos的一种简化形式。
这篇主要分析leader的选主机制,zookeeper提供了三种方式:
LeaderElection
AuthFastLeaderElection
FastLeaderElection
默认的算法是FastLeaderElection,所以这篇主要分析它的选举机制。
比如有三台服务器,编号分别是1,2,3。
编号越大在选择算法中的权重越大。
服务器中存放的最大数据ID.
值越大说明数据越新,在选举算法中数据越新权重越大。
或者叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比,根据不同的值做出不同的判断。
LOOKING,竞选状态。
FOLLOWING,随从状态,同步leader状态,参与投票。
OBSERVING,观察状态,同步leader状态,不参与投票。
LEADING,领导者状态。
在投票完成后,需要将投票信息发送给集群中的所有服务器,它包含如下内容。
服务器ID
数据ID
逻辑时钟
选举状态
因为每个服务器都是独立的,在启动时均从初始状态开始参与选举,下面是简易流程图。
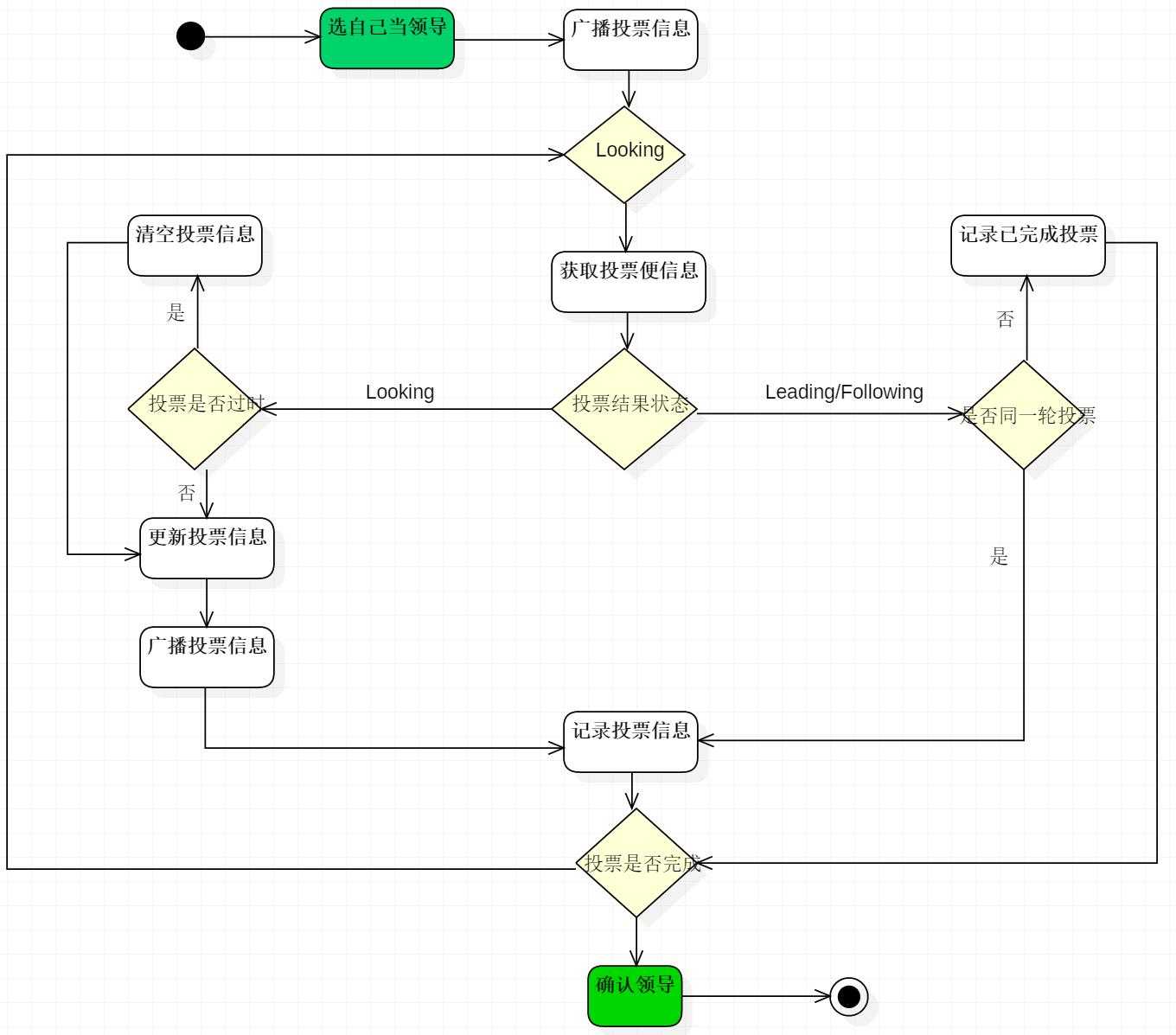
下面详细解释一下这个流程:
首先给出几个名词定义:
(1)Serverid:在配置server时,给定的服务器的标示id。
(2)Zxid:服务器在运行时产生的数据id,zxid越大,表示数据越新。
(3)Epoch:选举的轮数,即逻辑时钟。随着选举的轮数++
(4)Server状态:LOOKING,FOLLOWING,OBSERVING,LEADING
FastLeaderElection步骤:
一、 Server刚启动(宕机恢复或者刚启动)准备加入集群,此时读取自身的zxid等信息。
二、 所有Server加入集群时都会推荐自己为leader,然后将(leader id 、 zxid 、 epoch)作为广播信息,广播到集群中所有的服务器(Server)。然后等待集群中的服务器返回信息。
三、 收到集群中其他服务器返回的信息,此时要分为两类:该服务器处于looking状态,或者其他状态。
(1) 服务器处于looking状态
首先判断逻辑时钟 Epoch:
a) 如果接收到Epoch大于自己目前的逻辑时钟(说明自己所保存的逻辑时钟落伍了)。更新本机逻辑时钟Epoch,同时 Clear其他服务发送来的选举数据(这些数据已经OUT了)。然后判断是否需要更新当前自己的选举情况(一开始选择的leader id 是自己)
判断规则rules judging:保存的zxid最大值和leader Serverid来进行判断的。先看数据zxid,数据zxid大者胜出;其次再判断leader Serverid, leader Serverid大者胜出;然后再将自身最新的选举结果(也就是上面提到的三种数据(leader Serverid,Zxid,Epoch)广播给其他server)
b) 如果接收到的Epoch小于目前的逻辑时钟。说明对方处于一个比较OUT的选举轮数,这时只需要将自己的 (leader Serverid,Zxid,Epoch)发送给他即可。
c) 如果接收到的Epoch等于目前的逻辑时钟。再根据a)中的判断规则,将自身的最新选举结果广播给其他 server。
同时Server还要处理2种情况:
a) 如果Server接收到了其他所有服务器的选举信息,那么则根据这些选举信息确定自己的状态(Following,Leading),结束Looking,退出选举。
b) 即使没有收到所有服务器的选举信息,也可以判断一下根据以上过程之后最新的选举leader是不是得到了超过半数以上服务器的支持,如果是则尝试接受最新数据,倘若没有最新的数据到来,说明大家都已经默认了这个结果,同样也设置角色退出选举过程。
(2) 服务器处于其他状态(Following, Leading)
a) 如果逻辑时钟Epoch相同,将该数据保存到recvset,如果所接收服务器宣称自己是leader,那么将判断是不是有半数以上的服务器选举它,如果是则设置选举状态退出选举过程
b) 否则这是一条与当前逻辑时钟不符合的消息,那么说明在另一个选举过程中已经有了选举结果,于是将该选举结果加入到outofelection集合中,再根据outofelection来判断是否可以结束选举,如果可以也是保存逻辑时钟,设置选举状态,退出选举过程。
以上就是FAST选举过程。
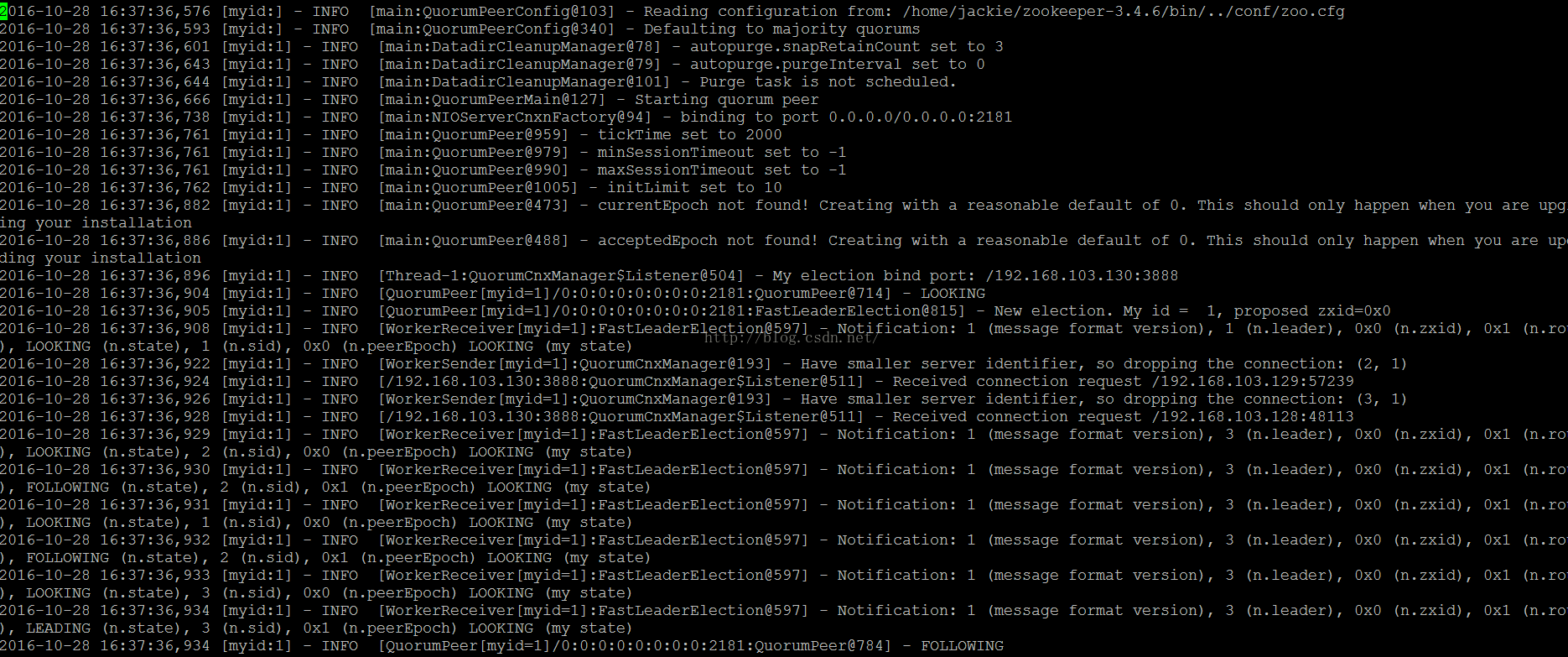
Zookeeper具体的启动日志如下图所示:
以上就是我自己配置的Zookeeper选主日志,从一开始LOOKING,然后new election, my id = 1, proposedzxid=0x0 也就是选自己为Leader,之后广播选举并重复之前Fast选主算法,最终确定Leader。
主要看这个类,只有LOOKING状态才会去执行选举算法。每个服务器在启动时都会选择自己做为领导,然后将投票信息发送出去,循环一直到选举出领导为止。
public void run() {
//.......
?
try {
while (running) {
switch (getPeerState()) {
case LOOKING:
if (Boolean.getBoolean("readonlymode.enabled")) {
//...
try {
//投票给自己...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
} finally {
//...
}
} else {
try {
//...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
}
}
break;
case OBSERVING:
//...
break;
case FOLLOWING:
//...
break;
case LEADING:
//...
break;
}
}
} finally {
//...
}
}
它是zookeeper默认提供的选举算法,核心方法如下:具体的可以与本文上面的流程图对照。
public Vote lookForLeader() throws InterruptedException {
//...
try {
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
?
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
?
int notTimeout = finalizeWait;
?
synchronized(this){
//给自己投票
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
?
//将投票信息发送给集群中的每个服务器
sendNotifications();
?
//循环,如果是竞选状态一直到选举出结果
?
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
?
//没有收到投票信息
if(n == null){
if(manager.haveDelivered()){
sendNotifications();
} else {
manager.connectAll();
}
?
//...
}
//收到投票信息
else if (self.getCurrentAndNextConfigVoters().contains(n.sid)) {
switch (n.state) {
case LOOKING:
// 判断投票是否过时,如果过时就清除之前已经接收到的信息
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
//更新投票信息
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
//发送投票信息
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
//忽略
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
//更新投票信息
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
?
recvset.put(n.sid, new Vote(n.leader, n.zxid,