标签:std 数据库文件 port from reverse filename item 就是 切割
最近爬了下自如网在深圳地域的租房信息,发现房价是一个很大的问题。
正好也刚看了机器学习实战这本书,感觉可以试一下写个图像识别来针对下这个问题=0=
(其实当时试了好多网上的方法,不知道为啥一张很明显的数字图片,就是读不出来,所以就自己模仿着写了个)
自如图片down下来后类似这种,由0-9十个数字,300*30大小的png格式组成的图片

下面的有两个数据库文件扔不上来,所以直接跑应该必报错。直接扔到github上了。
github:https://github.com/CzaOrz/smallStorage/tree/master/scrapy_shenzhen/ziru
两个文件:cza_keys.txt、cza_values.txt
import os
from PIL import Image
import numpy as np
import operator
"""img2gsi"""
def img2gsi(img,threshold):
"""传入image对象进行灰度、二值处理"""
img = img.convert("L") # 转灰度
pixdata = img.load()
w, h = img.size
for x in range(w):
for y in range(h):
if pixdata[x, y] > threshold:
pixdata[x, y] = 1
else:
pixdata[x, y] = 0
return img
"""自如图片由包含0-9的300*30大小的png格式图片组成,切割下"""
def splitImage(img, rownum, colnum):
list = []
w, h = img.size
if rownum <= h and colnum <= w:
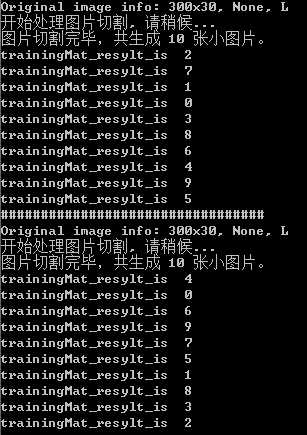
print(‘Original image info: %sx%s, %s, %s‘ % (w, h, img.format, img.mode))
print(‘开始处理图片切割, 请稍候...‘)
num = 0
rowheight = h // rownum
colwidth = w // colnum
for r in range(rownum):
for c in range(colnum):
box = (c * colwidth, r * rowheight, (c + 1) * colwidth, (r + 1) * rowheight)
list.append(np.array(img.crop(box), ‘f‘))#.save(os.path.join(basename + ‘_‘ + str(num) + ‘.‘ + ext), ext)
num = num + 1
print(‘图片切割完毕,共生成 %s 张小图片。‘ % num)
return list #切割之后,返回每一个图片的数组阵吗
else:
print(‘不合法的行列切割参数!‘)
"""机器学习实战上写的函数,直接手动copy"""
def classify0(inX, dataSet, labels, k): # inX is values you want to match, dataSet is learning database
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5 # ((x-x)**2 + (x-x)**2)**0.5, remember it is still a array
sortedDistIndicies = distances.argsort() # rerurn the array‘s index by reverse = False
classCount = {} # define a dictionary
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(),
key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]#,sortedClassCount[0][1],sortedClassCount[1][0],sortedClassCount[1][1]
def img2vector(data):
returnVect = np.zeros((1,900))
#fr = open(filename)
#print(fr)
count = 0
for row in data:#range(30):
for gsi in row:#range(30):
returnVect[0, count] = gsi#float(lineStr[j])
count += 1
return returnVect
def handwritingClassTest(testData):
list = [] #there may exist bug when run it
trainingMat = np.loadtxt(os.path.join(os.getcwd(), ‘cza_values.txt‘)) #读取训练数据库,数据库我没贴上来=0=
with open(os.path.join(os.getcwd(), ‘cza_keys.txt‘),‘r‘) as f_r: #读取训练数据库,数据库我没贴上来=0=
data = f_r.readline()
hwLabels = [int(i) for i in data]
print(‘read db done‘)
for data in testData:#range(mTest):
vectorUnderTest = img2vector(data)#os.getcwd()+‘\\test\\%s‘%fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
list.append(classifierResult)
print(‘trainingMat_resylt_is ‘, classifierResult)#,‘real result is ‘,classNumStr)
return list
def img2num(picture): # input a picture name is ok
img = Image.open(picture)
img = img2gsi(img,140)
testData = splitImage(img, 1, 10)
print(‘start handel‘)
result = handwritingClassTest(testData)
return result # this is a list including picture2num
if __name__ == ‘__main__‘:
img2num(‘123.png‘)
img2num(‘456.png‘)
最后结果类似这种,只是针对自如的这种图片可以达到成功率100%,其他的就不谈了,bug无解
菜鸟一个,刚学不久,不会的还是太多了QAQ
标签:std 数据库文件 port from reverse filename item 就是 切割
原文地址:https://www.cnblogs.com/czaOrz/p/10358442.html