标签:返回值 info erp 时间 dig sel val beta als
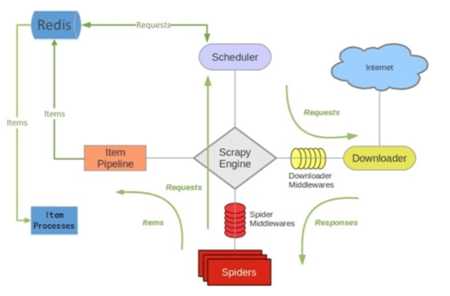
scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署。
可以启动多个spider工程,相互之间共享单个redis的requests队列。最适合广泛的多个域名网站的内容爬取。
爬取到的scrapy的item数据可以推入到redis队列中,这意味着你可以根据需求启动尽可能多的处理程序来共享item的队列,进行item数据持久化处理
Scheduler调度器 + Duplication复制 过滤器,Item Pipeline,基本spider
去重规则的校验
实现调度器对请求的调配
定制起始URL
pip install scrapy-redis
redis的集合有去重属性,在保存重复的值的时候返回值会是 0
from scrapy.dupefilter import BaseDupeFilter import redis from scrapy.utils.request import request_fingerprint class DupFilter(BaseDupeFilter): def __init__(self): self.conn = redis.Redis(host=‘140.143.227.206‘,port=8888,password=‘beta‘) def request_seen(self, request): """ 检测当前请求是否已经被访问过 :param request: :return: True表示已经访问过;False表示未访问过 """ fid = request_fingerprint(request) result = self.conn.sadd(‘visited_urls‘, fid) if result == 1: return False return True
# 直接加了配置就生效。但是是基于时间戳的,时间戳变了就会失效很不实用
################ scrapy redis连接 #################### REDIS_HOST = ‘127.0.0.1‘ # 主机名 REDIS_PORT = 6379 # 端口 REDIS_PARAMS = {‘password‘:‘yangtuo‘} # Redis连接参数,比如密码
# 默认:REDIS_PARAMS = {‘socket_timeout‘: 30,‘socket_connect_timeout‘: 30,‘retry_on_timeout‘: True,‘encoding‘: REDIS_ENCODING,}) REDIS_ENCODING = "utf-8" # redis编码类型 默认:‘utf-8‘ # REDIS_URL = ‘redis://user:pass@hostname:9001‘ # 连接URL(优先于以上配置)
################ scrapy redis去重 #################### DUPEFILTER_KEY = ‘dupefilter:%(timestamp)s‘ # 默认的是按照时间戳的。结果每次请求的时候是会进行去重 # 但是下一次请求时间戳不一致就会清空导致无法去重 因此这里存在优化空间 最好定死 # DUPEFILTER_CLASS = ‘scrapy_redis.dupefilter.RFPDupeFilter‘ # 如果使用 scrapy-redis 的默认去重是会使用这个类来处理去重 DUPEFILTER_CLASS = ‘dbd.xxx.RedisDupeFilter‘ # 这样使用自己自定义的去重规则
优化
from scrapy_redis.dupefilter import RFPDupeFilter from scrapy_redis.connection import get_redis_from_settings from scrapy_redis import defaults class RedisDupeFilter(RFPDupeFilter): @classmethod def from_settings(cls, settings):
server = get_redis_from_settings(settings) # key = defaults.DUPEFILTER_KEY % {‘timestamp‘: int(time.time())} # 源码这里是用的时间戳 不断变换导致每次重置 key = defaults.DUPEFILTER_KEY % {‘timestamp‘: ‘yangtuo‘} # 不要时间戳了,我定死一个固定值 debug = settings.getbool(‘DUPEFILTER_DEBUG‘) return cls(server, key=key, debug=debug)
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) SCHEDULER_QUEUE_CLASS = ‘scrapy_redis.queue.PriorityQueue‘ # SCHEDULER_QUEUE_CLASS = ‘scrapy_redis.queue.FifoQueue‘ # 广度优先 基于队列 先进先出 # SCHEDULER_QUEUE_CLASS = ‘scrapy_redis.queue.LifoQueue‘ # 深度优先 基于栈 后进先出 # SCHEDULER_QUEUE_CLASS = ‘scrapy_redis.queue.PriorityQueue‘ 的时候才有用 DEPTH_PRIORITY = 1 # 广度优先 # DEPTH_PRIORITY = -1 # 深度优先 后进先出 SCHEDULER_QUEUE_KEY = ‘%(spider)s:requests‘ # 调度器中请求存放在redis中的key SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle SCHEDULER_PERSIST = False # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 SCHEDULER_FLUSH_ON_START = True # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 # SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 SCHEDULER_DUPEFILTER_KEY = ‘%(spider)s:dupefilter‘ # 去重规则,在redis中保存时对应的key # 优先使用 DUPEFILTER_CLASS,如果没有就是用 SCHEDULER_DUPEFILTER_CLASS SCHEDULER_DUPEFILTER_CLASS = ‘scrapy_redis.dupefilter.RFPDupeFilter‘ # 去重规则对应处理的类
import scrapy from scrapy.http import Request import scrapy_redis from scrapy_redis.spiders import RedisSpider class ChoutiSpider(RedisSpider): # 继承改为 用 name = ‘chouti‘ allowed_domains = [‘chouti.com‘] # def start_requests(self): # 不再需要写 start_requests 了 # yield Request(url=‘https://dig.chouti.com‘,callback=self.parse) def parse(self, response): print(response)
import redis conn = redis.Redis(host=‘127.0.0.1‘,port=6379,password=‘yangtuo‘) # 通过往 redis 里面加数据从而控制爬虫的执行 # 如果没有数据就会夯住。一旦有数据就爬取,可以 conn.lpush(‘chouti:start_urls‘,‘https://dig.chouti.com/r/pic/hot/1‘)
scrapy crawl chouti --nolog
找到 SCHEDULER = "scrapy_redis.scheduler.Scheduler" 配置并实例化调度器对象
- 执行Scheduler.from_crawler
- 执行Scheduler.from_settings
- 读取配置文件:
SCHEDULER_PERSIST # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 SCHEDULER_FLUSH_ON_START # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 SCHEDULER_IDLE_BEFORE_CLOSE # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)
- 读取配置文件:
SCHEDULER_QUEUE_KEY # %(spider)s:requests # 读取保存在 redis 中存放爬虫名字的 name 的值 SCHEDULER_QUEUE_CLASS # scrapy_redis.queue.FifoQueue # 读取要使用的队列方式 SCHEDULER_DUPEFILTER_KEY # ‘%(spider)s:dupefilter‘ # 读取保存在 redis 中存放爬虫去重规则名字的 key 的值 DUPEFILTER_CLASS # ‘scrapy_redis.dupefilter.RFPDupeFilter‘ # 读取去重的配置的类 SCHEDULER_SERIALIZER # "scrapy_redis.picklecompat" # 读取保存在 redis 的时候用的序列化方式
- 读取配置文件:
REDIS_HOST = ‘140.143.227.206‘ # 主机名 REDIS_PORT = 8888 # 端口 REDIS_PARAMS = {‘password‘:‘beta‘} # Redis连接参数 默认:REDIS_PARAMS = {‘socket_timeout‘: 30,‘socket_connect_timeout‘: 30,‘retry_on_timeout‘: True,‘encoding‘: REDIS_ENCODING,}) REDIS_ENCODING = "utf-8"
- 实例Scheduler对象
- 调用 scheduler.enqueue_requests()
def enqueue_request(self, request): # 请求是否需要过滤? dont_filter = False 表示过滤 # 去重规则中是否已经有?(是否已经访问过,如果未访问添加到去重记录中。) # 要求过滤,且去重记录里面有就变表示访问过了 if not request.dont_filter and self.df.request_seen(request): self.df.log(request, self.spider) return False # 已经访问过就不要再访问了 if self.stats: self.stats.inc_value(‘scheduler/enqueued/redis‘, spider=self.spider) # print(‘未访问过,添加到调度器‘, request) self.queue.push(request) return True
- 调用 scheduler.next_requests()
def next_request(self): block_pop_timeout = self.idle_before_close request = self.queue.pop(block_pop_timeout) if request and self.stats: self.stats.inc_value(‘scheduler/dequeued/redis‘, spider=self.spider) return request
深度优先 :基于层级先进入到最深层级进行处理全部后再往上层级处理
广度优先 :基于从第一层级开始,每次层级处理之后进入下一层及处理
先进先出,广度优先 FifoQueue
后进先出,深度优先 LifoQueue
优先级队列:
DEPTH_PRIORITY = 1 # 广度优先
DEPTH_PRIORITY = -1 # 深度优先
调度器,调配添加或获取那个request.
队列,存放request。
dupefilter,访问记录。
调度器拿到一个 request 要先去 dupefilter 里面看下有没有存在
如果存在就直接丢了
如果不存在才可以放在队列中
然后队列要基于自己的类型来进行相应规则的存放
打比方来说:
调度器 货车司机
dupefilter 仓库门卫
队列 仓库
司机要往仓库放货。先问门卫
门卫说里面有货了不让就没法放
门卫说可以才可以放
放货的时候仓库要按照自己的规则放货
司机要拉货 仓库就基于自己的规则直接给司机就行了
标签:返回值 info erp 时间 dig sel val beta als
原文地址:https://www.cnblogs.com/shijieli/p/10360798.html