标签:ima exe pip art win main 数据处理 raw lin
1.安装
1、安装wheel pip install wheel 2、安装lxml https://pypi.python.org/pypi/lxml/4.1.0 3、安装pyopenssl https://pypi.python.org/pypi/pyOpenSSL/17.5.0 4、安装Twisted https://www.lfd.uci.edu/~gohlke/pythonlibs/ 5、安装pywin32 https://sourceforge.net/projects/pywin32/files/ 6、安装scrapy pip install scrapy
2.创建项目
1. 创建工程 scrapy startproject movie 2. 创建爬虫程序 cd movie scrapy genspider meiju meijutt.com
3.项目结构
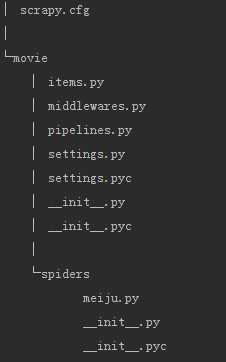
4.文件说明
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
5.设置爬虫可调试运行
from scrapy.cmdline import execute if __name__ == ‘__main__‘: execute(["scrapy", "crawl", "sdz"])
标签:ima exe pip art win main 数据处理 raw lin
原文地址:https://www.cnblogs.com/songdongdong6/p/10361222.html