标签:lin window 也会 自然语言 sed 分词 16px 实现 http
之前在其他博客文章有提到如何对英文进行分词,也说后续会增加解释我们中文是如何分词的,我们都知道英文或者其他国家或者地区一些语言文字是词与词之间有空格(分隔符),这样子分词处理起来其实是要相对容易很多,但是像中文处理起来就没有那么容易,因为中文字与字之间,词与词之间都是紧密连接在一起的,所以第一件事需要处理的就是如何确认词。中文文章的最小组成单位是字,但是独立的字并不能很好地传达想要表达整体的意思或者说欠缺表达能力,所以一篇成文的文章依旧是以词为基本单位来形成有意义的篇章,所以词是最小并且能独立活动的语言成分。这也就说明在处理中文文本的时候,首先将句子转化为特定的词语结构(so-called 单词),这就是中文分词的重点。在这篇博客中,主要介绍常用的中文分词技术有哪几种。
前方高能:因代码输出结果我都打印出来了,篇幅占了不少,但是为了说明问题,没办法,还请各位看官和看友见谅。另,因为将规则分词和统计分词放到了一篇博文中,进一步导致篇幅很长,希望真的没引起观感不适。??????
一、规则分词
规则分词(Rule-based Tokenization)是通过设立词典并不断地对词典进行维护以确保分词准确性的分词技术。基于规则分词是一种匹配式的分词技术,要进行分词的时候通过在词典中寻找相应的匹配,找到则进行切分,否则则不切分。传统的规则式分词主要有三种:正向最大匹配法(Maximum Match Method)、逆向最大匹配法(Reversed Maximum Match Method)以及双向最大匹配(Bi-direction Matching Method)。
1.1 正向最大匹配法
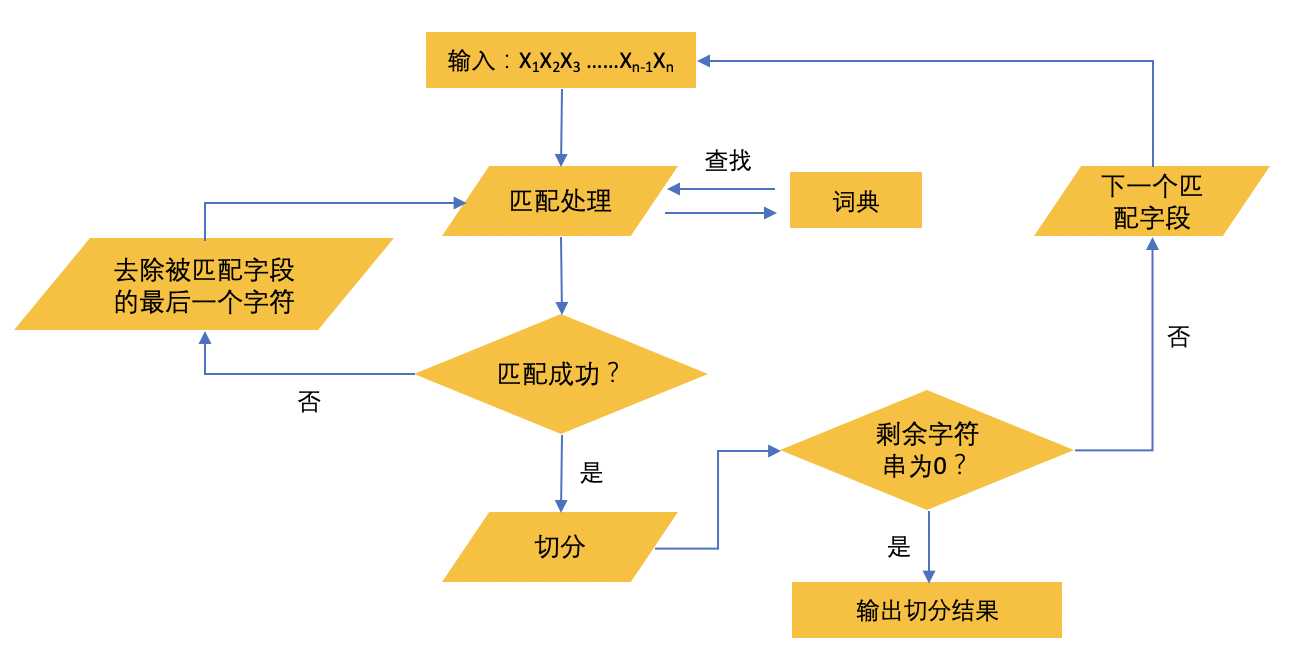
正向最大匹配法基本思想是假定设定好的词典中的最长词(也就是最长的词语)含有 i 个汉字字符,那么则用被处理中文文本中当前字符串字段的前 i 个字作为匹配字段去跟词典的这 i 个进行匹配查找(如处理的当前中文字符串中要查找“学海无涯”这四个字组成的词语,我们就在词典中去寻找相匹配的四个字并作为基本切分单位输出),假如词典中含有这么一个 i 字词语则匹配成功,切分该词,反之则匹配失败,那么这个时候就会去掉需要被匹配字段中的最后一个汉字字符,并对剩下的字符串进行匹配处理(继续把去掉最后一个字符的字符串跟词典继续匹配),循环往复直到所有字段成功匹配,循环终止的条件是切分出最后一个词或者剩余匹配的字符串的长度为零。下面流程图是正向最大匹配算法的描述过程(根据个人理解画出,如果有哪里不对的,还请指出!)。
下面是Python代码实现的简单的正向最大匹配算法:
1 class MaximumMatching(object): 2 3 def __init__(self): 4 self.window_size = 6 # 定义词典中的最长单词的长度 5 6 7 def tokenize(self, text): 8 tokens = [] # 定义一个空列表来保存切分的结果 9 index = 0 # 切分 10 text_length = len(text) 11 12 # 定义需要被维护的词典,其中词典最长词的长度为6 13 maintained_dic = [‘研究‘, ‘研究生‘, ‘自然‘, ‘自然语言‘, ‘语言‘,‘自然语言处理‘, ‘处理‘, ‘是‘, ‘一个‘, ‘不错‘, ‘的‘, ‘科研‘, ‘方向‘] 14 15 while text_length > index: # 循环结束判定条件 16 # print(text_length) 17 print(‘index 4: ‘, index) 18 for size in range(self.window_size + index, index, -1): # 根据窗口大小循环,直到找到符合的进行下一次循环 19 print(‘index 1: ‘, index) 20 print(‘window size: ‘, size) 21 piece = text[index: size] # 被匹配字段 22 if piece in maintained_dic: # 如果需要被匹配的字段在词典中的话匹配成功,新的index为新的匹配字段的起始位置 23 index = size - 1 24 print(‘index 2: ‘, index) 25 break 26 index += 1 27 print(‘index 3‘, index, ‘\n‘) 28 tokens.append(piece) # 将匹配到的字段保存起来 29 return tokens 30 31 if __name__ == ‘__main__‘: 32 text = ‘研究生研究自然语言处理是一个不错的研究方向‘ 33 tokenizer = MaximumMatching() 34 print(tokenizer.tokenize(text))
输出结果是(这里为了之后说明该算法的存在的一个短板,将循环的每一步都打印出来以便观察,输出结果可能有点长,为了说明问题所在,造成不便还请见谅):
index 4: 0 index 1: 0 window size: 6 index 1: 0 window size: 5 index 1: 0 window size: 4 index 1: 0 window size: 3 index 2: 2 index 3 3 index 4: 3 index 1: 3 window size: 9 index 1: 3 window size: 8 index 1: 3 window size: 7 index 1: 3 window size: 6 index 1: 3 window size: 5 index 2: 4 index 3 5 index 4: 5 index 1: 5 window size: 11 index 2: 10 index 3 11 index 4: 11 index 1: 11 window size: 17 index 1: 11 window size: 16 index 1: 11 window size: 15 index 1: 11 window size: 14 index 1: 11 window size: 13 index 1: 11 window size: 12 index 2: 11 index 3 12 index 4: 12 index 1: 12 window size: 18 index 1: 12 window size: 17 index 1: 12 window size: 16 index 1: 12 window size: 15 index 1: 12 window size: 14 index 2: 13 index 3 14 index 4: 14 index 1: 14 window size: 20 index 1: 14 window size: 19 index 1: 14 window size: 18 index 1: 14 window size: 17 index 1: 14 window size: 16 index 2: 15 index 3 16 index 4: 16 index 1: 16 window size: 22 index 1: 16 window size: 21 index 1: 16 window size: 20 index 1: 16 window size: 19 index 1: 16 window size: 18 index 1: 16 window size: 17 index 2: 16 index 3 17 index 4: 17 index 1: 17 window size: 23 index 1: 17 window size: 22 index 1: 17 window size: 21 index 1: 17 window size: 20 index 1: 17 window size: 19 index 2: 18 index 3 19 index 4: 19 index 1: 19 window size: 25 index 2: 24 index 3 25 [‘研究生‘, ‘研究‘, ‘自然语言处理‘, ‘是‘, ‘一个‘, ‘不错‘, ‘的‘, ‘研究‘, ‘方向‘]
通过上述输出结果的最后一行,我们可以看到通过正向最大匹配算法得到的切分结果还是很不错的,但是这并不意味着实际运用都会十分精准,这里主要有三个问题需要注意:
1.2 逆向最大匹配算法
逆向最大匹配算法的实现过程基本跟正向最大匹配算法无差,唯一不同的点是分词的切分是从后往前,跟正向最大匹配方法刚好相反。也就是说逆向是从字符串的最后面开始扫描,每次选取最末端的 i 个汉字字符作为匹配词段,若匹配成功则进行下一字符串的匹配,否则则移除该匹配词段的最前面一个汉字,继续匹配。需要注意的是,分词词典为逆向词典,即每个词条都以逆序的方式存放。当然这个也不一定非得这么处理,因为我们是逆向匹配,所以得到的结果是逆向的,只需要在最后反过来即可。
1 class ReversedMaximumMatching(object): 2 3 def __init__(self): 4 self.window_size = 6 5 6 def tokenize(self, text): 7 tokens = [] 8 index = len(text) 9 10 maintained_dic = [‘研究‘, ‘研究生‘, ‘自然‘, ‘自然语言‘, ‘语言‘,‘自然语言处理‘, ‘处理‘, ‘是‘, ‘一个‘, ‘不错‘, ‘的‘, ‘科研‘, ‘方向‘] 11 12 while index > 0: 13 print(‘Index 1: ‘, index) 14 for size in range(index - self.window_size, index): 15 print(‘Window Check point: ‘, size) 16 w_piece = text[size: index] 17 print(‘Checked Words‘, w_piece) 18 if w_piece in maintained_dic: 19 index = size + 1 20 print(‘Index 2: ‘, index) 21 break 22 index -= 1 23 print(‘Index 3: ‘, index, ‘\n‘) 24 tokens.append(w_piece) 25 print(tokens) 26 tokens.reverse() 27 28 return tokens 29 30 31 if __name__ == ‘__main__‘: 32 33 text = ‘研究生研究自然语言处理是一个不错的研究方向‘ 34 tokenizer = ReversedMaximumMatching() 35 print(tokenizer.tokenize(text))
上述代码的输出结果为:
Index 1: 21 Window Check point: 15 Checked Words 错的研究方向 Window Check point: 16 Checked Words 的研究方向 Window Check point: 17 Checked Words 研究方向 Window Check point: 18 Checked Words 究方向 Window Check point: 19 Checked Words 方向 Index 2: 20 Index 3: 19 Index 1: 19 Window Check point: 13 Checked Words 个不错的研究 Window Check point: 14 Checked Words 不错的研究 Window Check point: 15 Checked Words 错的研究 Window Check point: 16 Checked Words 的研究 Window Check point: 17 Checked Words 研究 Index 2: 18 Index 3: 17 Index 1: 17 Window Check point: 11 Checked Words 是一个不错的 Window Check point: 12 Checked Words 一个不错的 Window Check point: 13 Checked Words 个不错的 Window Check point: 14 Checked Words 不错的 Window Check point: 15 Checked Words 错的 Window Check point: 16 Checked Words 的 Index 2: 17 Index 3: 16 Index 1: 16 Window Check point: 10 Checked Words 理是一个不错 Window Check point: 11 Checked Words 是一个不错 Window Check point: 12 Checked Words 一个不错 Window Check point: 13 Checked Words 个不错 Window Check point: 14 Checked Words 不错 Index 2: 15 Index 3: 14 Index 1: 14 Window Check point: 8 Checked Words 言处理是一个 Window Check point: 9 Checked Words 处理是一个 Window Check point: 10 Checked Words 理是一个 Window Check point: 11 Checked Words 是一个 Window Check point: 12 Checked Words 一个 Index 2: 13 Index 3: 12 Index 1: 12 Window Check point: 6 Checked Words 然语言处理是 Window Check point: 7 Checked Words 语言处理是 Window Check point: 8 Checked Words 言处理是 Window Check point: 9 Checked Words 处理是 Window Check point: 10 Checked Words 理是 Window Check point: 11 Checked Words 是 Index 2: 12 Index 3: 11 Index 1: 11 Window Check point: 5 Checked Words 自然语言处理 Index 2: 6 Index 3: 5 Index 1: 5 Window Check point: -1 Checked Words Window Check point: 0 Checked Words 研究生研究 Window Check point: 1 Checked Words 究生研究 Window Check point: 2 Checked Words 生研究 Window Check point: 3 Checked Words 研究 Index 2: 4 Index 3: 3 Index 1: 3 Window Check point: -3 Checked Words Window Check point: -2 Checked Words Window Check point: -1 Checked Words Window Check point: 0 Checked Words 研究生 Index 2: 1 Index 3: 0 [‘方向‘, ‘研究‘, ‘的‘, ‘不错‘, ‘一个‘, ‘是‘, ‘自然语言处理‘, ‘研究‘, ‘研究生‘] [‘研究生‘, ‘研究‘, ‘自然语言处理‘, ‘是‘, ‘一个‘, ‘不错‘, ‘的‘, ‘研究‘, ‘方向‘]
倒数第二行输出结果是逆向匹配得到的结果,此时我们仅需对其reverse一下即可得到最终需要的结果。除此之外,通过观察上述的结果,亦可发现一个在正向最大匹配算法中同样遇到的问题,那就是程序的执行效率并不高,因为算法需要不断的去检测匹配的字段,这个在需要维护的词典是非常庞大的情况下是相当耗时间和耗资源的。
1.3 双向最大匹配算法
二、统计分词
2.1 Viterbi算法
2.2 隐马尔可夫模型(Hidden Markov Model)
标签:lin window 也会 自然语言 sed 分词 16px 实现 http
原文地址:https://www.cnblogs.com/jielongAI/p/10362314.html