标签:可见 exec hbase sed 依次 table general 背景 Fix
最近遇到一例,并发拉取HBase大量指定列数据时,导致应用不响应的情形。记录一下。
退款导出中,为了获取商品规格编码,需要从HBase表 T 里拉取对应的数据。 T 对商品数据的存储采用了 表名:字段名:id 的列存储方式。由于这个表很大,且为详情公用,因此不方便使用 scan 的方式,担心带来集群的不稳定,进而影响详情和导出的整体稳定性。
要用 multiGet 的方式来获取多个订单的这个列的数据。 就必须动态生成相应的列,然后在 HBase 获取数据的时候指定列集合。 现有记录集合 List
然而,当 HBase指定列名集合比较大的时候, 似乎是有问题的。导致了堆内存爆了。

CPU 曲线也是直线上升
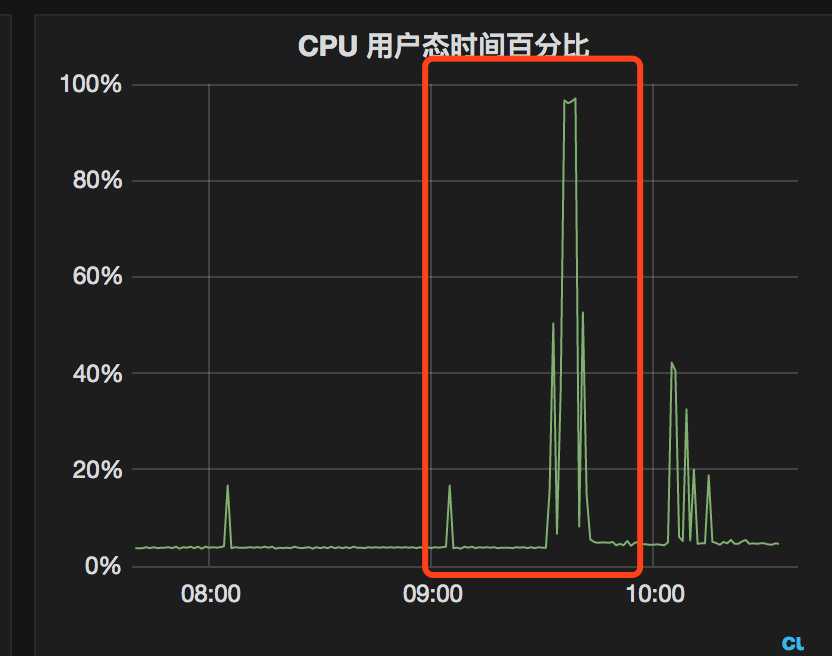
从错误日志上看,是因为 HBase 获取数据卡住了。 而此次的变更在于是增加了一个可以并发获取HBase指定列数据的插件。 因为某种原因,必须生成和指定大量列去查询HBase数据, 因此疑点主要锁定在 HBase 获取大量动态列数据是不是有问题,是不是因为指定列太多了。
原来的代码如下:
private List<Result> fetchDataFromHBase(List<OneRecord> data, List<String> rowKeys, HBaseDataConf hbaseDataConf) {
List<Result> hbaseResults = multiTaskExecutor.exec(rowKeys,
subRowkeys -> haHbaseService.getRawData(subRowkeys, hbaseDataConf.getTable(),
"cf", generateCols(hbaseDataConf.getFetchDataConf(), data), "", true), 200);
return hbaseResults;
}问题出在 subRowkeys -> haHbaseService.getRawData(subRowkeys, hbaseDataConf.getTable(), "cf", generateCols(hbaseDataConf.getFetchDataConf(), data) 这一行上。 data 是记录全集,这样 generalCols 会拿到所有订单的商品ID 对应的列集合。而 subRowkeys 是按照指定任务数分割后的 HBase Rowkeys 子集合。 假如 data 有 8000 条记录,那么 generateCols(hbaseDataConf.getFetchDataConf(), data) 会生成几万条动态列,而 subRowkeys 只有不足 200 条。 显然, generateCols 里的 data 应该是对应划分后的 subRowkeys 的那些记录,而不是全部记录。
修改后的代码如下:
private List<Result> fetchDataFromHBase(List<OneRecord> data, HBaseDataConf hbaseDataConf) {
List<Result> hbaseResults = multiTaskExecutor.exec(data,
partData -> fetchDataFromHBasePartially(partData, hbaseDataConf), 200);
return hbaseResults;
}
private List<Result> fetchDataFromHBasePartially(List<OneRecord> partData, HBaseDataConf hbaseDataConf) {
List<String> rowKeys = RowkeyUtil.buildRowKeys(partData, hbaseDataConf.getRowkeyConf());
logger.info("hbase-rowkeys: {}", rowKeys.size());
return haHbaseService.getRawData(rowKeys, hbaseDataConf.getTable(),
"cf", generateCols(hbaseDataConf.getFetchDataConf(), partData), "", true);
}这里,generalCols 用来生成的动态列就只对应分割后的记录集合。修改后,问题就解决了。
那么,为什么数万条指定列会导致HBase获取数据时内存爆掉了呢?
在 获取 HBase 数据的地方打日志:
String cf = (cfName == null) ? "cf" : cfName;
logger.info("columns: {}", columns);
List<Get> gets = buildGets(rowKeyList, cf, columns, columnPrefixFilters);
logger.info("after buildGet: {}", gets.size());
Result[] results = getFromHbaseFunc.apply(tableName, gets);
logger.info("after getHBase: {}", results.length);发现: columns 日志打出来了, after buildGet 没有打出来。程序卡住了。可以推断,是 buildGets 这一步卡住了。为什么卡在了 buildGets 这一步呢?
写一个单测,做个小实验。 先弄个串行的实验。 1000个订单, 列数从 2000 增长 24000
@Test
def "testMultiGetsSerial"() {
expect:
def columnSize = 12
def rowkeyNums = 1000
def rowkeys = (1..rowkeyNums).collect { "E001" + it }
(1..columnSize).each { colsSize ->
def columns = (1..(colsSize*2000)).collect { "tc_order_item:sku_code:" + it }
def start = System.currentTimeMillis()
List<Get> gets = new HAHbaseService().invokeMethod("buildGets", [rowkeys, "cf", columns, null])
gets.size() == rowkeyNums
def end = System.currentTimeMillis()
def cost = end - start
println "num = $rowkeyNums , colsSize = ${columns.size()}, cost (ms) = $cost"
}
}耗时如下:
num = 1000 , colsSize = 2000, cost (ms) = 2143
num = 1000 , colsSize = 4000, cost (ms) = 3610
num = 1000 , colsSize = 6000, cost (ms) = 5006
num = 1000 , colsSize = 8000, cost (ms) = 8389
num = 1000 , colsSize = 10000, cost (ms) = 8921
num = 1000 , colsSize = 12000, cost (ms) = 12467
num = 1000 , colsSize = 14000, cost (ms) = 11845
num = 1000 , colsSize = 16000, cost (ms) = 12589
num = 1000 , colsSize = 18000, cost (ms) = 20068
java.lang.OutOfMemoryError: GC overhead limit exceeded按照实际运行的并发情况做个实验。 从 1000 到 6000 个订单,列集合数量 从 1000 - 10000。 用并发来构建 gets 。
@Test
def "testMultiGetsConcurrent"() {
expect:
def num = 4
def columnSize = 9
(1..num).each { n ->
def rowkeyNums = n*1000
def rowkeys = (1..rowkeyNums).collect { "E001" + it }
(1..columnSize).each { colsSize ->
def columns = (1..(colsSize*1000)).collect { "tc_order_item:sku_code:" + it }
def start = System.currentTimeMillis()
List<Get> gets = taskExecutor.exec(
rowkeys, { new HAHbaseService().invokeMethod("buildGets", [it, "cf", columns, null]) } as Function, 200)
gets.size() == rowkeyNums
def end = System.currentTimeMillis()
def cost = end - start
println "num = $rowkeyNums , colsSize = ${columns.size()}, cost (ms) = $cost"
println "analysis:$rowkeyNums,${columns.size()},$cost"
}
}
}耗时如下:
num = 1000 , colsSize = 1000, cost (ms) = 716
num = 1000 , colsSize = 2000, cost (ms) = 1180
num = 1000 , colsSize = 3000, cost (ms) = 1378
num = 1000 , colsSize = 4000, cost (ms) = 2632
num = 1000 , colsSize = 5000, cost (ms) = 2130
num = 1000 , colsSize = 6000, cost (ms) = 4328
num = 1000 , colsSize = 7000, cost (ms) = 4524
num = 1000 , colsSize = 8000, cost (ms) = 5612
num = 1000 , colsSize = 9000, cost (ms) = 5804
num = 2000 , colsSize = 1000, cost (ms) = 1416
num = 2000 , colsSize = 2000, cost (ms) = 1486
num = 2000 , colsSize = 3000, cost (ms) = 2434
num = 2000 , colsSize = 4000, cost (ms) = 4925
num = 2000 , colsSize = 5000, cost (ms) = 5176
num = 2000 , colsSize = 6000, cost (ms) = 7217
num = 2000 , colsSize = 7000, cost (ms) = 9298
num = 2000 , colsSize = 8000, cost (ms) = 11979
num = 2000 , colsSize = 9000, cost (ms) = 20156
num = 3000 , colsSize = 1000, cost (ms) = 1837
num = 3000 , colsSize = 2000, cost (ms) = 2460
num = 3000 , colsSize = 3000, cost (ms) = 4516
num = 3000 , colsSize = 4000, cost (ms) = 7556
num = 3000 , colsSize = 5000, cost (ms) = 6169
num = 3000 , colsSize = 6000, cost (ms) = 19211
num = 3000 , colsSize = 7000, cost (ms) = 180950
……可见,耗时随着rowkey 数应该是线性增长; 而随着指定列集合的增大,会有超过线性的增长和波动。超线性增长是算法引起的,波动应该是由线程池执行引起的。
如果有 8800 个订单,指定 24000 个列, 可想而知,有多慢了。
查看buildGets代码,其中嫌疑最大的就是 addColumn 方法。这个方法添加列时,将列加入了 NavigableSet<byte[]> 这个数据结构里。NavigableSet是一个排序的集合。HBase 的 NavigableSet 实现类是 TreeSet, 是基于红黑树实现的。红黑树查询一个元素的复杂度是在O(Log2n) 。添加N个元素的复杂度在 n*O(Log2n) 。 如果添加大量列,就可能导致CPU计算消耗大,并发的情况会加剧。
那么, HBase 列数据集的结构为什么要用排序的Set 而不用普通的 Set 呢?是因为指定列从HBase获取数据时,HBase会将满足条件的数据拿出来,依次与指定列进行匹配过滤,这时候要应用到查找列功能。当指定列非常大时,TreeSet 的效率比 HashSet 的要大。
因为一个低级的错误,导致堆内存爆了; 又因为这个错误,深入了解了 HBase 读取列数据的一些内幕。 幸~~ 后续还需要深入学习下 红黑树的算法实现。
【完】
标签:可见 exec hbase sed 依次 table general 背景 Fix
原文地址:https://www.cnblogs.com/lovesqcc/p/10367112.html