标签:性能 http 缺点 toc stat image 循环 info mount
目录
翻译自Jacob Devlin分享的slides
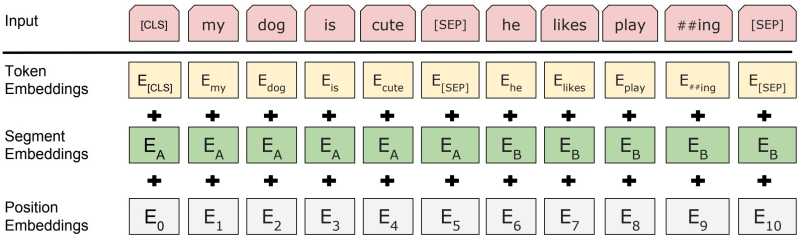
词嵌入是利用深度学习解决自然语言处理问题的基础。

词嵌入(例如word2vec,GloVe)通常是在一个较大的语料库上利用词共现统计预训练得到的。例如下面两个句子中,由于king和queen附近的上下文时常相同或相似,那么在向量空间中,这两个词的距离较为接近。

问题:通常的词嵌入算法无法表现一个词在不同语境(上下文)中不同的语义。例如bank一词在下列两个句子中有着不同的语义,但是却只能使用相同的向量来表示。
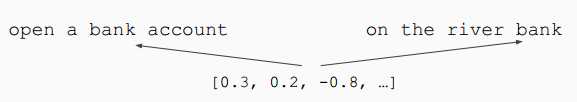
解决方案:在大语料上训练语境表示,从而得到不同上下文情况下的不同向量表示。

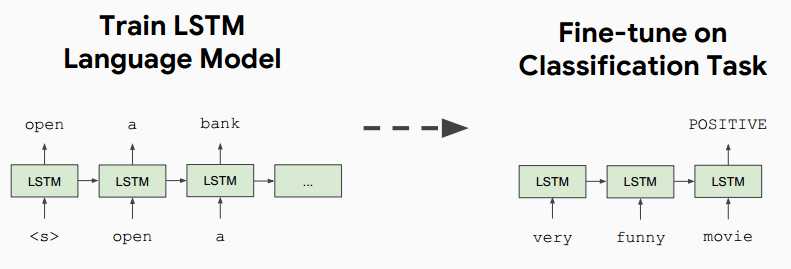
2018年中:GPT: Improving language understanding by generative pre-training, OpenAI
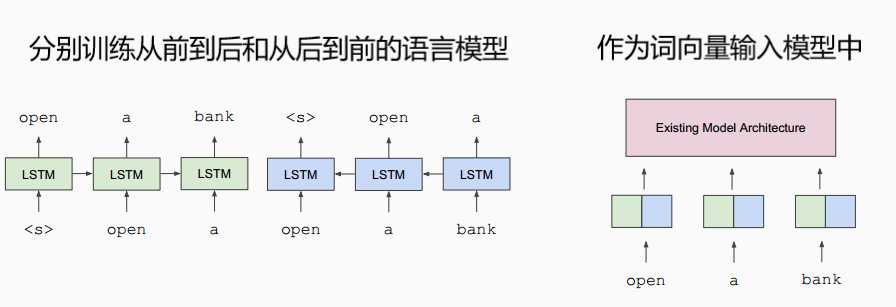
译者注:比较著名的还有2018年初fast.ai提出的ULMFiT
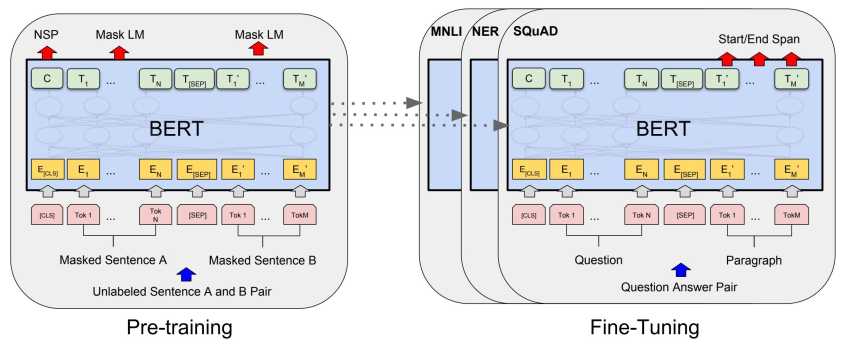
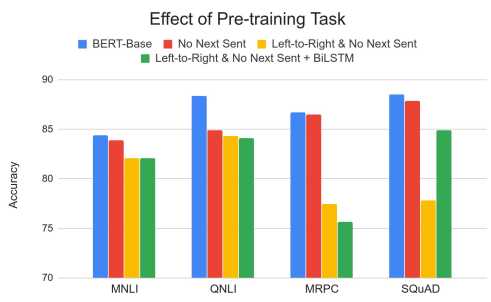
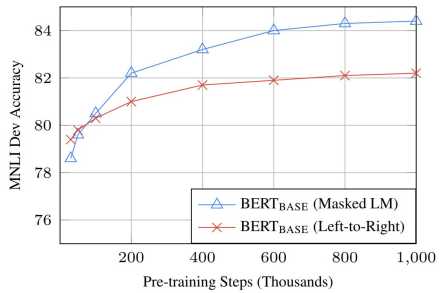
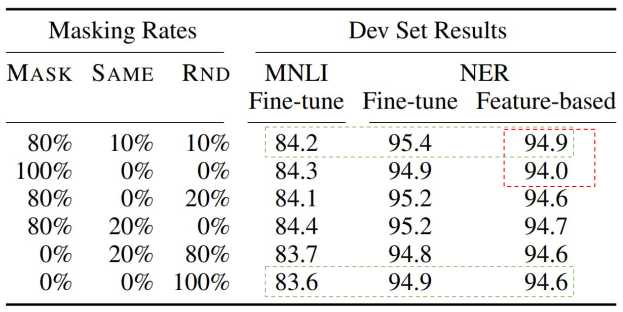
把输入序列中的k%(一般为15%)的词掩盖住,然后通过上下文预测这些被掩盖住的词。
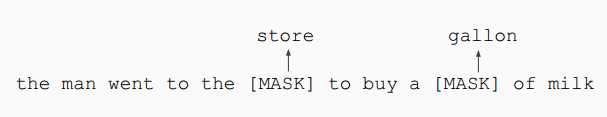

学习句子间的关系,预测句子B是否句子A的下一句话(译者注:二元分类任务)。

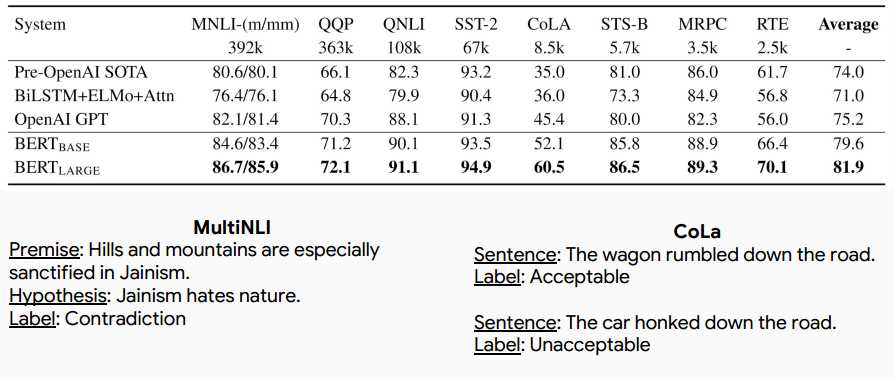
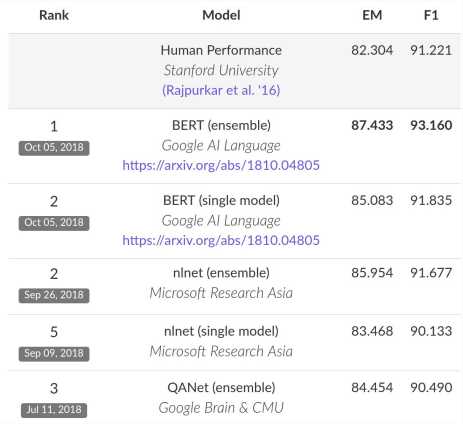
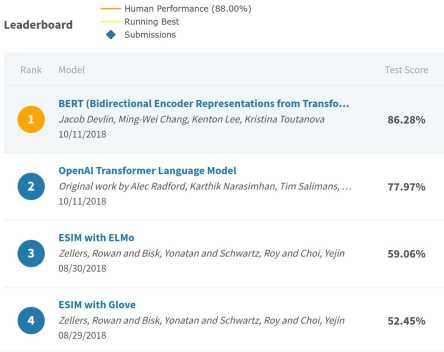
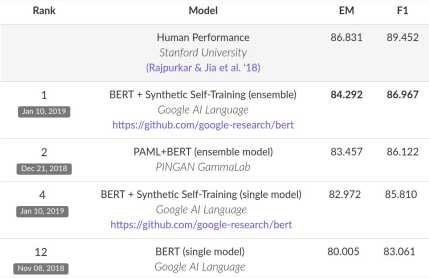
*注:榜单已经被很多基于BERT的模型刷新了

使用seq2seq模型从context+answer中生成正例问题
启发式地将正例问题转换为负例(如“no answer”/impossible )
在维基百科数据上预训练seq2seq模型
在SQuAD 进行微调——Context+Answer →Question
训练模型,预测答案,不使用问题描述
使用第三步的模型从大量维基百科数据中生成答案
使用第四步的输出作为seq2seq模型的输入,生成问题描述
利用基线SQuAD2.0 系统过滤不好的问题
启发式地生成强负例
可选步骤: Two-pass训练,
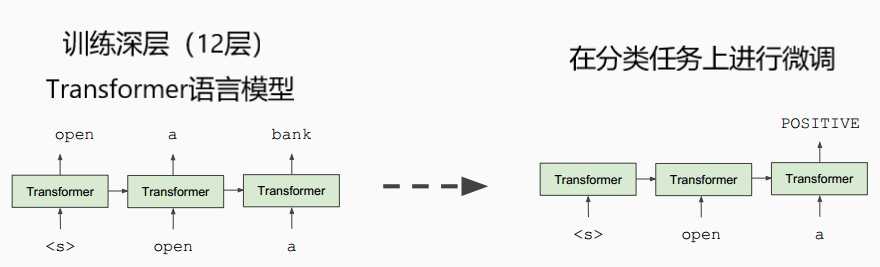
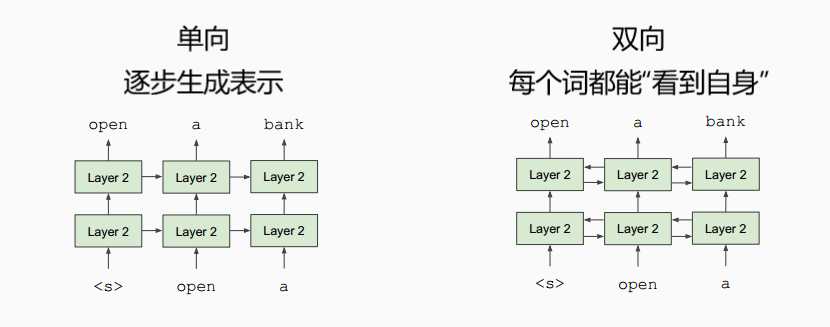
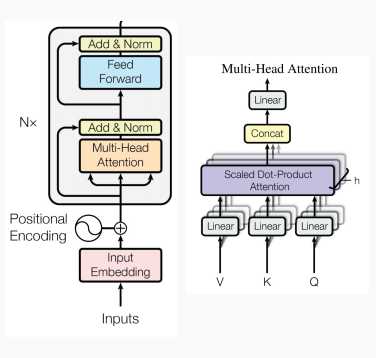
深度双向Transformer预训练【BERT第一作者分享】
标签:性能 http 缺点 toc stat image 循环 info mount
原文地址:https://www.cnblogs.com/d0main/p/10368965.html