标签:dump.rdb list state discard 子进程 mys 说明 异常 sync
大数据时代要求:
高并发操作不建议使用关联查询,而使用冗余数据,分布式系统支持不了太多的并发。
横向 VS 纵向:
Not Only SQL,不仅仅是SQL,泛指非关系型数据库,这种类型数据库存储不需要固定的关系模式,数据之间没有直接关系,更易于横向扩展。由于它的无关系性,数据库结构简单,此类数据库即使是在大数据量的情况下也具有非常高的性能。
| 类别 | 典型应用 | 应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| KV键值对 | Redis、Memcache | 内容缓存;大数据量的高负载访问 | k-v(Hashtable) | 查询速度快 | 数据无结构,通常只被当作字符串或者二进制数据 |
| 文档型数据库 | MongoDB | web应用,基于分布式文件存储的数据库,由C++编写,旨在为web应用提供可扩展的高性能数据存储解决方案,是NoSQL中功能最丰富最像SQL的。 | 通常是Bson,与k-v类似,但value是结构化的数据,不同的是数据库能够了解value的内容 | 数据结构要求不严格;表结构可变,不需要预先定义表结构 | 查询性能不高;缺乏统一的查询语法 |
| 列存储数据库 | HBase | 分布式文件系统 | 列簇式存储,将同一列数据存在一起 | 查询速度快;可扩展性强;更容易进行分布式扩展 | 功能相对较局限 |
| 图关系数据库 | Neo4J | 社交网络,专注于构建关系图谱 | 图结构 | 利用图结构相关算法,如最短路径寻址 | 很多时候都需要对整个图做计算才能得到需要的数据 |
分区容错性:Partition tolerance
CAP的3进2:在分布式系统中,最多只能实现CAP原理中的两点,而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容错性是必须要实现的。
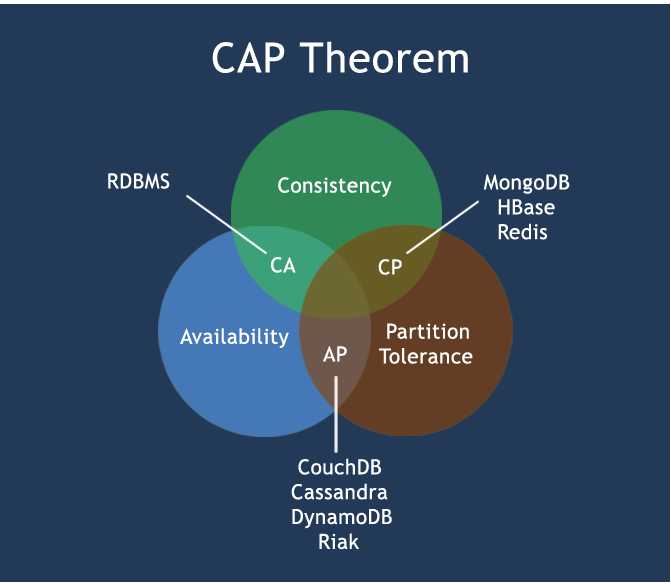
BASE:
完全开源免费的,使用C语言开发,遵守BSD协议
一个高性能的分布式内存数据库,基于内存运行并支持持久化的NoSQL,也被称为数据结构服务器
特点
linux版安装与启动:
Redis是单进程的,处理速度完全取决于主线程的执行效率,默认16个数据库,统一密码管理,使用select
String:字符串,redis中最基本的类型,是二进制安全的,即可以包含图片或者序列化对象等任意对象,最多支持512M大小。
Hash:哈希,是一个键值对集合,但V是一个键值对类似于java里的Map<String, Map<String,Object>>
Set:集合,无序的,是通过Hashtable实现的
ZSet(sorted set):有序集合,不同于set的是每个元素前都会带有一个double类型的可重复的score,根据score进行排序。
Key
String
Hash
List
Set
Zset
Units:单位,配置大小单位,只支持bytes,不支持bit,忽略大小写
INCLUDES:可以包含其它的配置文件
GENERAL:通用
SNAPSHOTTING:RDB文件的快照
REPLICATION:复制
SECURITY安全:访问密码的查看、设置和取消
LIMITS限制:
APPEND ONLY MODE:追加
RDB:
Fork:就是复制一个和当前主进程完全一样的子进程,子进程的所有数据都和原进程一致,消耗的资源也会翻倍。
动态停止:redis-cli config set save ""
缺点:
AOF:
Rewrite,redis为防止文件过大增加的重写机制,aof文件大小超出阈值时进行压缩只保留可以恢复数据的最小指令集,可以使用命令bgrewriteaof,重写类似于快照,也是Fork出一个新的进程,遍历内存数据重写AOF文件
缺点:
Which One?
开启事务:MULTI
入队:将执行的操作放入队列queue中,执行时按队列顺序地串行化执行而不会被其它命令插入,不许加塞
执行种类:
放弃事务:DISCARD
特性:
主机数据更新后根据配置和策略自动同步数据到从机上,Master以写为主,Slave以都为主
原理:Slave启动成功连接到Master后会发送一个sync指令,master接收到启动后台的存盘进程,同时收集所有修改数据命令,执行完毕后将传送给Slave,完成一次全量复制,之后进行增量复制,同步master收到的修改命令,但只要重新连接master则就会自动执行一次全量复制。
使用:
从库配置:slaveof [主库ip] [主库端口],每次与master断开连接后都需要重新连接,除非修改redis.conf
复制缺点:复制延时,由于所有写操作都在Master上操作,再同步到Slave,当主机繁忙时,延迟会更加严重,Slave机器数量的增加也会使延时问题更加严重。
修改bin文件夹的权限,否则无法生存dump.rdb文件
修改 /etc/sysctl.conf 文件 添加 vm.overcommit_memory=1然后重启或者执行命令:sysctl vm.overcommit_memory=1
执行命令:sysctl -w fs.file-max=100000,调整最大文件数量
import redis.clients.jedis.*;
public class TestRedis {
@Test
public void testTx() throws InterruptedException {
Jedis jedis = new Jedis("192.168.43.178",6379);
jedis.set("balance", "100");
jedis.set("debt", "0");
jedis.watch("balance");
// Thread.sleep(5000);
/**/
if (Integer.parseInt(jedis.get("balance")) < 50) {
System.out.println("error");
jedis.unwatch();
return;
} else {
Transaction tx = jedis.multi();
tx.incrBy("debt", 50);
tx.decrBy("balance", 50);
tx.exec();
System.out.println("success");
}
System.out.println(jedis.get("balance"));
System.out.println(jedis.get("debt"));
}
@Test
public void testMasterSlaver() throws InterruptedException {
Jedis jedis_m = new Jedis("192.168.43.178",6379);
Jedis jedis_s = new Jedis("192.168.43.178",6380);
jedis_s.slaveof("192.168.43.178", 6379);
jedis_m.set("kkk", "master");
Thread.sleep(1000);
System.out.println(jedis_s.get("kkk"));
}
@Test
public void testPool() throws InterruptedException {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(1000);
jedisPoolConfig.setMaxIdle(50);
jedisPoolConfig.setMaxWaitMillis(60 * 1000);
jedisPoolConfig.setTestOnBorrow(true);
JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.43.178",6379);
Jedis jedis = jedisPool.getResource();
try {
jedis.set("pool", "cool");
System.out.println(jedis.get("pool"));
} catch (Exception e) {
e.printStackTrace();
} finally {
jedis.close();
jedisPool.returnResourceObject(jedis);
}
}
}标签:dump.rdb list state discard 子进程 mys 说明 异常 sync
原文地址:https://www.cnblogs.com/mabaoqing/p/10368944.html