标签:image info inf com 质量 数据 谷歌 期望 清华大学
低资源:
平行语料库:质量不行。
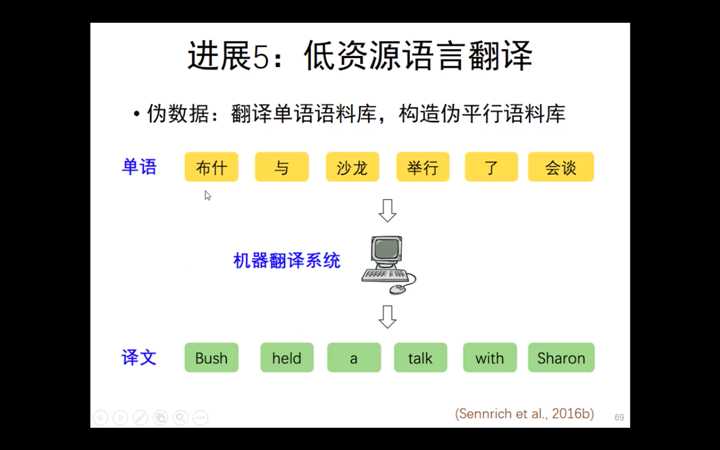
伪数据:用单语语料库单向翻译,构造伪平行语料库
半监督学习

对偶学习:微软的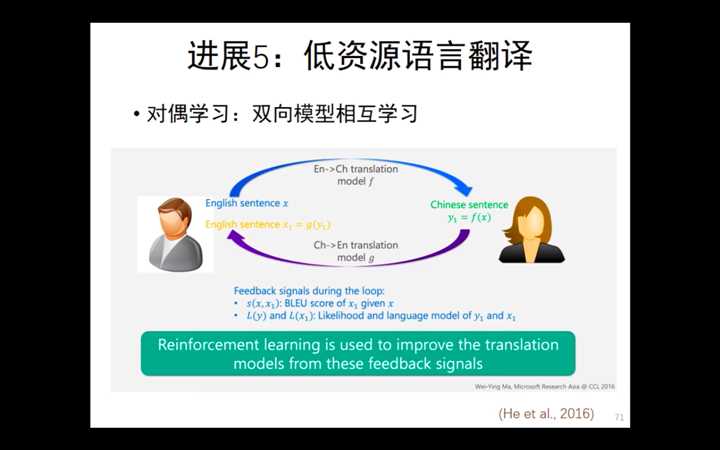
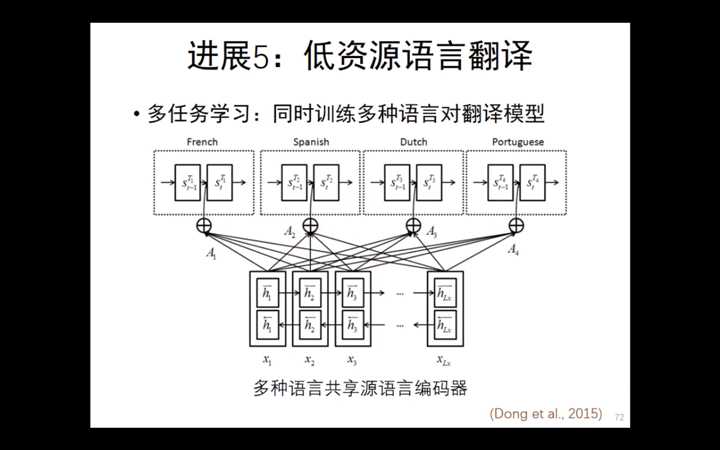
多任务学习:百度的
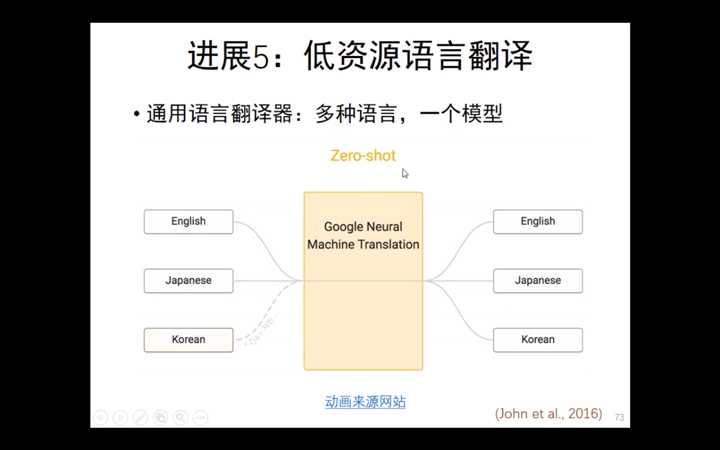
谷歌:通用的语言翻译模型
最大期望似然估计

————————————————————————————————————————————————————————————————————
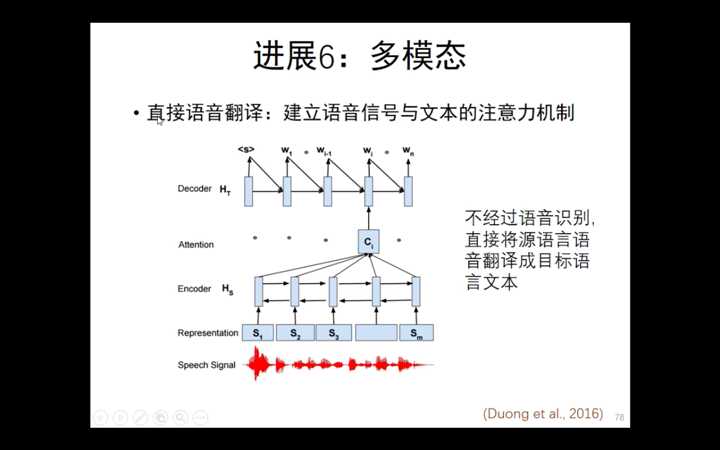
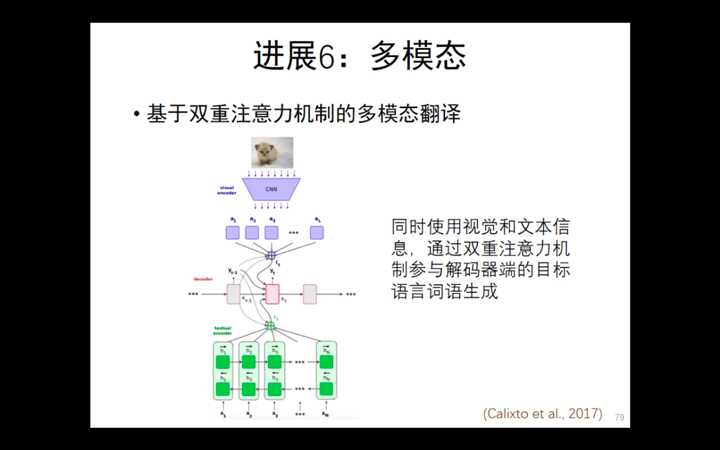
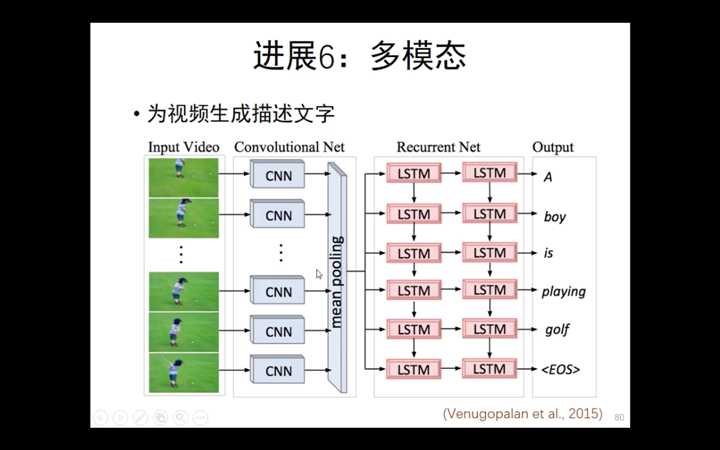





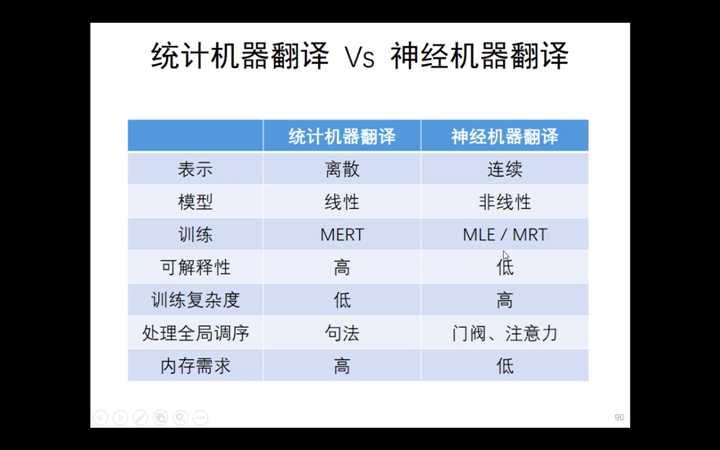
清华大学刘洋--基于深度学习的机器翻译(2)--- 低资源/多模态
标签:image info inf com 质量 数据 谷歌 期望 清华大学
原文地址:https://www.cnblogs.com/vector11248/p/10382951.html