TCP如果收到ACK后,不管是顺序ACK还是重复ACK(可能带有SACK选项),都可能对传输队列进行4次扫描,它们先后顺序分别是:
1.第一遍扫面,分别做以下事情:
故事发生在tcp_ack->tcp_sacktag_write_queue函数
1.1.标记被SACK的数据包
故事发生在tcp_ack->tcp_sacktag_write_queue->函数主体
1.2.标记哪些已经重传的包可能丢失
故事发生在tcp_ack->tcp_sacktag_write_queue->tcp_mark_lost_retrans
1.3.更新网络乱序度reordering
故事发生在tcp_ack->tcp_sacktag_write_queue->if (...) tcp_update_reordering
整个故事如下图所示:

如果UNA向前推进了,我们就不多说了,如果没有推进UNA,而且有SACK标记(请注意,FACK并不是一种特殊的模式,它只是SACK的一种激进重传方案)的情况下,第一遍扫描会完成上述的1.1,1.2,1.3这三件事,其中第一件事就不说了,就是按照ACK数据包的选项,将传输队列中的被选项选中的数据包标记为SACK;第二件事有点复杂,一般而言,TCP的每一种重传机制除了RTO的退避机制会重传多次之外,只会将数据包重传一次,但是事实上并不绝对,如果可以启发到重传的数据包有很高的概率丢失,那么就可以将该重传过的数据包抹去其“已重传”标志,这意味着如果有哪个执行路径认为其可以被重传,那么它将会被再次重传一次!
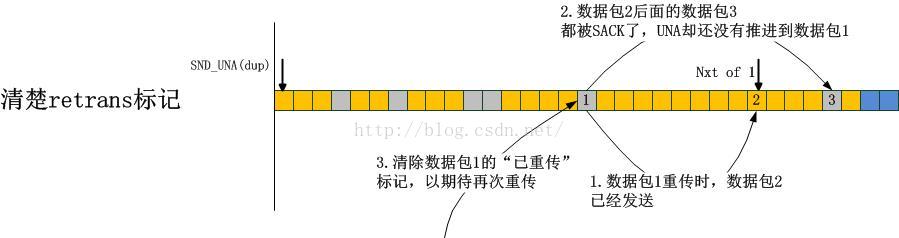
如何判断一个重传的数据包已经丢失呢?请看Linux协议栈之tcp_mark_lost_retrans函数,其主要思想是:
在重传每一个数据包的时候,记录重传当时的snd_nxt,记为其ack_seq字段,如果发现一个被重传的数据包的ack_seq后面的数据包都被SACK了,那么就说明该重传数据包可能又一次没有到达接收端,丢失了!注意,这也是一种启发式算法,因为在重传数据包N的时候,其ack_seq几乎同时也被传输了,那么正常来讲,它们的ACK应该同时到来,然而数据包N的ack_seq后面的都被SACK了,而数据包N却没有被SACK,说明它可能丢失了。如下图所示:
关于1.3,请看《
TCP拥塞控制图解(不包括RTO,因为它太简单了)》 原图中的网络重排序一节。
需要说明的是,对于1.3而言,扫描的时候,总是找到fack(请注意,它仅仅是一个计数器而已)最左边的第一个数据包(fack计数器每次都要从左到右撸一遍,撸的同时,记录从左到右第一个遇到的被SACK的数据包【它可能是被SACK的,也可能是被DSACK的】),然后fack与该数据包之间的距离就是新的reordering的值(如果它比老的reordering大的话)。
2.第二遍扫描:清除已经被顺序接收的数据包,更新诸多计数器
故事发生在tcp_ack->tcp_clean_rtx_queue
完成第一遍扫描之后,紧接着进行的第二遍扫描会根据新的UNA值,清除掉其左边直到prior UNA之间的数据包,同时,更重要的是,更新各个计数器,需要更新的计数器有,包括但不限于:
a).sacked_out:如果该数据包曾经被SACK过,即有SACKed标记,那么sacked_out会递减相应被清除掉的数据包大小;
b).lost_out:如果该数据包曾经被标记为LOST,那么lost_out会递减相应的数据包的大小;
c).packets_out:由于被ACK,那么packets_out会无条件递减被清除掉的数据包的大小;
d).retrans_out:如果该数据包被重传过,那么retrans_out会递减被清除掉的数据包的大小;
e).fackets_out:由于fack计数器仅仅与最右边被SACKed的数据包以及UNA有关,因此如果被清除掉的数据包大于fack计数器,那么fack归零,否则递减被清除掉的数据包大小。如图所示:
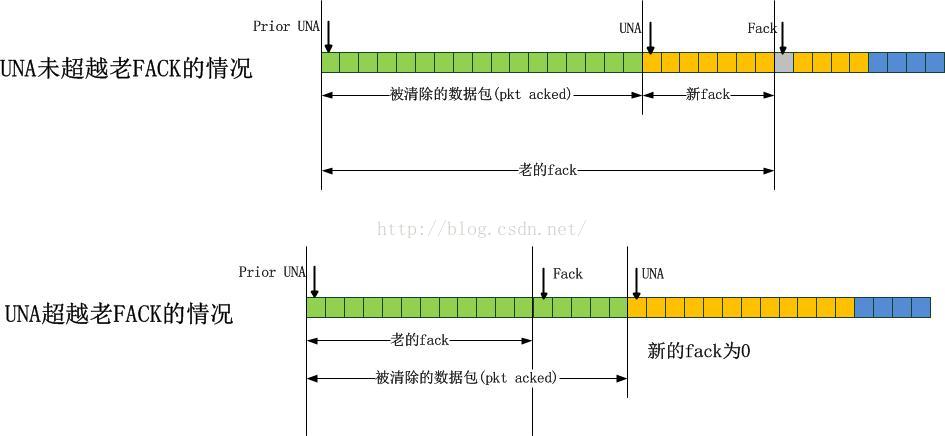
第二遍扫面的宗旨有二,其一是向前推进UNA,清除发送队列的skb,其二就是更新TCP的计数器,标准化“在途流量”。
3.第三遍扫描:标记可能已经LOST的数据包
故事发生在tcp_ack->tcp_fastretrans_alert->tcp_update_scoreboard
首先第一遍扫描标记了SACKed了哪些数据,并且清除了大概率已经丢失的重传数据标记,第二遍扫描清除了已经被顺序ACK的数据,那么现在该第三遍扫描了,即标记出哪些是已经丢失的数据,这个标记算法是启发式的,并不能表明一定准确,所以Linux的实现专门提供了各种undo机制!具体的细节,还是参见《
TCP拥塞控制图解(不包括RTO,因为它太简单了)》
4.第四遍扫描:按照RFC3517 nxtSeg例程传输该传输的数据包
故事发生在tcp_ack->tcp_fastretrans_alert->tcp_xmit_retransmit_queue
哪些数据包被SACK(已经标记),哪些被ACK(已经清除),哪些被当成LOST(已经标记),接下来该做什么呢?很显然,该重传了!到底怎么重传呢?还是参见《
TCP拥塞控制图解(不包括RTO,因为它太简单了)》以及其开头展示的勘误。
5.结语
本文用很短的篇幅简述了Linux协议栈收到TCP的ack包后的反应,开启了4遍扫描(对于fast路径,没有第一遍!),每一遍扫描都完成很少的特定任务,最终完成TCP的快速重传。
故事还没有结束