标签:col 有序 margin isp microsoft 实例 split() orm 交换
使用urllib库可以模拟浏览器发送请求获得服务器返回的数据,下一步就是把有用的数据提取出来。数据分为两种形式:结构化和非结构化。
非结构化的数据一般指的是文本和HTML。文本的内容特别的杂乱,比如有电话号码,邮箱等信息,只能使用正则表达式进行提取;HTML可以使用CSS选择器,Xpath、正则表达式进行提取。
结构化的数据一般指的是JSON和XML。JSon可以使用JSonPath处理,也可以转化成python对象。XML可以转化成python对象,或者使用CSS选择器、Xpath、正则表达式进行提取。
这节主要研究一下正则表达式的使用方法和re模块的常用方法。
--------------------------------------------------------------华丽的分隔符---------------------------------------------------------------------
从字符串起始位匹配,如果匹配则返回第一个次提取的内容,如果不匹配则返回None。
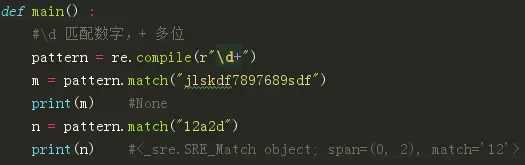
match中可以设置起始位置和结束位置。

compile()中可以设置一些参数,re.I 表示忽略大小写,re.S表示全文匹配

除了group()还有一个方法span(),返回的是字符下标。

切记,如果match对象为None时,使用group和span等方法会抛出异常,使用时进行非空判断。
从字符串任意位匹配,如果匹配则返回第一个次提取的内容,如果不匹配则返回None。

search中可以设置起始位置和结束位置。

从字符串任意位匹配,如果匹配则返回所有提取的内容,如果不匹配则返回[]。

findall中可以设置起始位置和结束位置。

从字符串任意位匹配,如果匹配则返回所有提取的内容组成的迭代对象,如果不匹配也返回一个迭代对象。

finditer中可以设置起始位置和结束位置。

finditer返回的迭代对象可以理解为match对象的集合,通过for遍历的方式,可以获取match,group方法可以获取匹配的值。
从字符串任意位匹配,如果匹配,则以匹配的内容为分割点,返回切分后的list数据。


从字符串任意位匹配,如果匹配,则替换匹配的内容,返回替换后的字符串。

从字符串任意位匹配,如果匹配,则交换匹配的内容的位置,返回处理后的字符串。

标签:col 有序 margin isp microsoft 实例 split() orm 交换
原文地址:https://www.cnblogs.com/beiyi888/p/10396023.html