标签:语言 bag image topic 数据 分析 选择 提取 算法
自然语言的话题topic分析
非监督学习 使用NMF非负矩阵分解提取文章话题,NMF是在矩阵中所有元素均为非负数约束条件之下的矩阵分解方法(NMF的基本思想可以简单描述为:对于任意给定的一个非负矩阵A,NMF算法能够寻找到一个非负矩阵U和一个非负矩阵V,使得满足 ,从而将一个非负的矩阵分解为左右两个非负矩阵的乘积。) 原始矩阵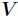 的列向量是对左矩阵
的列向量是对左矩阵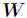 中所有列向量的加权和,而权重系数就是右矩阵对应列向量的元素,故称
中所有列向量的加权和,而权重系数就是右矩阵对应列向量的元素,故称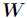 为基矩阵,
为基矩阵,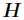 为系数矩阵。一般情况下
为系数矩阵。一般情况下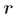 的选择要比
的选择要比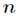 小,即满足
小,即满足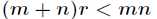 ,这时用系数矩阵代替原始矩阵,就可以实现对原始矩阵进行降维,得到数据特征的降维矩阵
,这时用系数矩阵代替原始矩阵,就可以实现对原始矩阵进行降维,得到数据特征的降维矩阵
单词 话题 文章 都是非负的数字
用矩阵的形式记录文章的内容 例如 矩阵中每一行代表一个单词,每一列代表一个文章。每一个数字代表 这个单词在这篇文章中出现的次数,即词袋模型 bag_words。例如有6篇文章4个单词,那么这个矩阵就是4*6的矩阵。单词出现频率 单词和话题间的密切程度 文本里面话题的权重
sklean
标签:语言 bag image topic 数据 分析 选择 提取 算法
原文地址:https://www.cnblogs.com/gaofeifei1-study/p/10396088.html