标签:简单 可行性 概率 精度 提取 包含 向量 重要 函数
前面介绍的R-CNN系的目标检测采用的思路是:首先在图像上提取一系列的候选区域,然后将候选区域输入到网络中修正候选区域的边框以定位目标,对候选区域进行分类以识别。虽然,在Faster R-CNN中利用RPN网络将候选区域的提取以放到了CNN中,实现了end-to-end的训练,但是其本质上仍然是提取先提取候选区域,然后对候选区域识别,修正候选区域的边框位置。这称为tow-stage的方法,虽然在精度已经很高了,但是其速度却不是很好。造成速度不好的主要原因就是候选区域的提取,这就需要一种网络能够直接预测出图像中目标的位置,中间不需要候选区域的计算,这就是one-stage。
YOLO系就是one-stage目标检测的一种,其全名You only look once很形象,只需要将图片输入到网络中就预测中其中目标的bounding box以及bounding box所属的类别。相比R-CNN,YOLO损失了一定的精度,但是其有点就是速度快。
YOLO V1将目标检测定义为一个回归问题,从图像像素信息直接得到目标的边框以及所属类别的概率,其有以下的优点:
YOLO 和R-CNN性能的对比

YOLO的也有一定的缺点,其准确度落后于Faster R-CNN,并且由于其使用比较粗糙的网格来划分原图,导致其对小目标的检测效果不是很好。
相对于R-CNN系首先从原图中计算出一系列的候选区域,YOLO则使用简单的方法,首先将图像划分为\(S\times S\)(论文中\(S = 7\))的网格,如果某个目标的中心位于一个grid cell中,则该grid cell就负责检测这个目标。
在YOLO网络中,目标的坐标信息是通过相对于某个grid cell左上角的偏移来表示的,目标的宽和高是用原图的宽和高占比表示的。 这就是这里为什么会说,如果某个目标的中心位于一个grid cell中,则该grid cell就负责检测这个目标,在做边框回归的时候,其GT就是该grid cell。
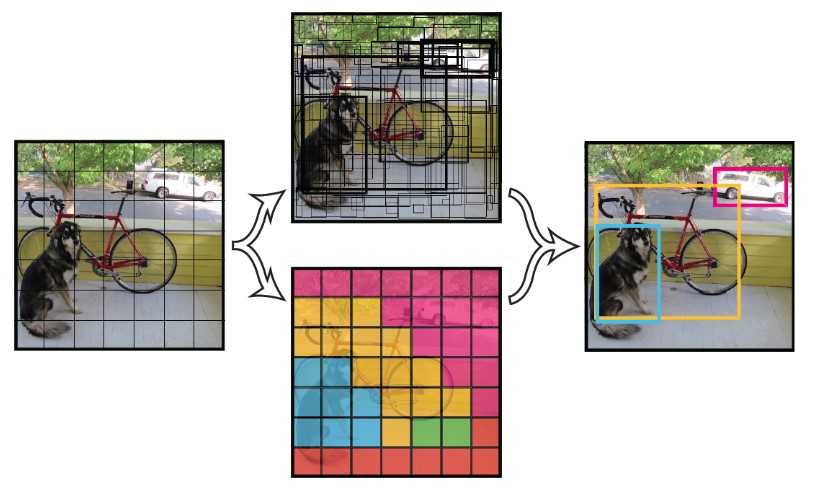
上面提到如果某个目标的中心位于一个grid cell中,则该grid cell就负责检测这个目标,也就是说在YOLO中,grid cell设计为可以代表目标,在网络中也是针对grid cell进行处理的。 在每个grid cell中预测出来\(B\)(\(B = 2\)个bounding box,而且要为每个预测出来的bounding box打个分数,来表示该bounding box是否包含目标以及该bbox作为目标边框的可信度,这个分数称为Confidence。Confidence 的定义如下:
\[
Confidence = Pr(object) \cdot IoU_{pred}^{truth}
\]
其中,\(Pr(object)\)为bbox包含目标的概率(bbox存在目标则$Pr(object) =1 \(,不存在目标则\)Pr(object) = 0\(;\)IoU_{pred}^{truth}$表示预测出来的bbox和Ground Truth之间的IoU。 也就是说,如果bbox不含目标则其confidence = 0,包含目标的话Confidence就是bbox和Ground Truth之间的IoU。
这样,通过每个grid cell预测出来的bbox可由一个五元组表示\((x,y,w,h,Confidence)\),其中\((x,y)\)表示bbox的中心相对该grid cell左上角的偏移量,使用grid cell的长宽为比例,将其值归一化到\([0,1]\)之间;\((w,h)\)为bbox的宽度和长度,以图像的宽度和长度归一化到\([0,1]\)之间;\(C\)就是上面提到的Confidence,其值也是在\([0,1]\)之间。 这样每个bbox可以使用五元组\((x,y,w,h,Confidence)\)表示,并且其值都是在\([0,1]\)之间。
以grid cell为准预测出来的bbox表示了目标的边框信息,并不能判断出来其中包含的目标是属于哪一个类。所以YOLO网络还为每一个grid cell预测出\(C\)个conditional class probability(条件类别概率):
\[
P(class_i | object)
\]
即在一个grid cell中有一个Object的前提下,它属于某个类的概率。只为每个grid cell预测一组类概率,而不考虑框的数量。
类别概率\(P(class_i | object)\)是对于某个grid cell的,表示该grid cell能够预测一个目标的条件下,其目标的属于某个类的概率;而bbox的confidence表示的是,包含目标的可行性。 将这两个值相乘,就可以得到bbox中包含的目标的的类别的概率了。
所以在测试阶段,将grid cell的\(P(class_i | object)\)和以该grid cell为准预测出来bbox的confidence相乘
\[
P(class_i | object) \cdot P(object) \cdot IoU_{pred}^{truth}
\]
该值就能反应出bbox包含某一个具体类别的目标的可信度。
在YOLO论文中,使用VOC的数据集,即有20个类别,将图像划分为\(7 \times 7\)的网格,每个grid cell预测出2个bbox,因此最终输出的数据张量尺寸为\(7 \times 7 \times 30\)。(\(S \times S \times (B \times 5 + C)\))。
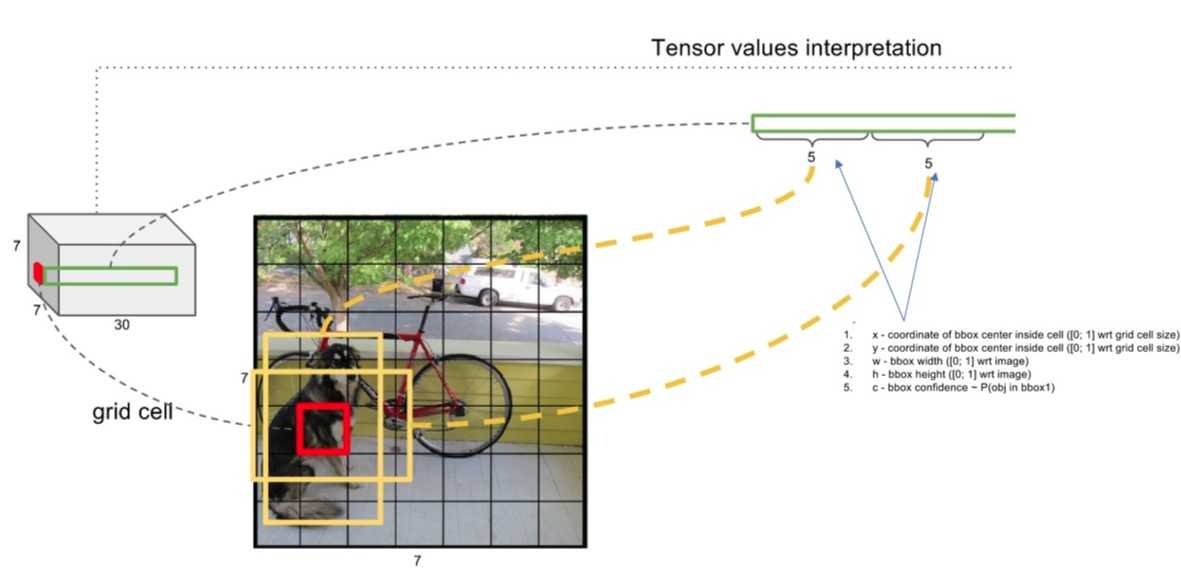
上图表示了YOLO网络针对某个grid cell的输出。
YOLO使用CNN来提取图像的特征,最后使用全连接层做回归预测,并且借鉴GooLeNet的思路,使用了\(1 \times 1\)卷积核。
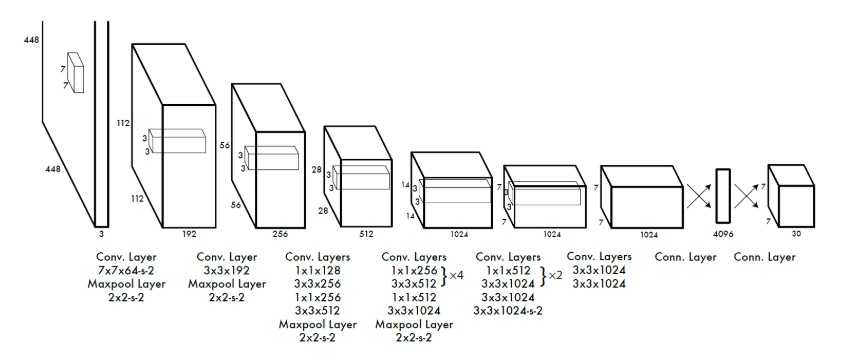
YOLO由24个卷积层和2个全连接层组成,最终的输出为\(7 \times 7 \times 30\)的张量,也就是针对每一个grid cell YOLO网络都输出了一个30维的向量,这个30维的向量就包括上面提到的各种信息:grid cell为基准预测出来的两个bbox五元组,以及针对grid cell的预测某个类别的条件概率。具体如下:

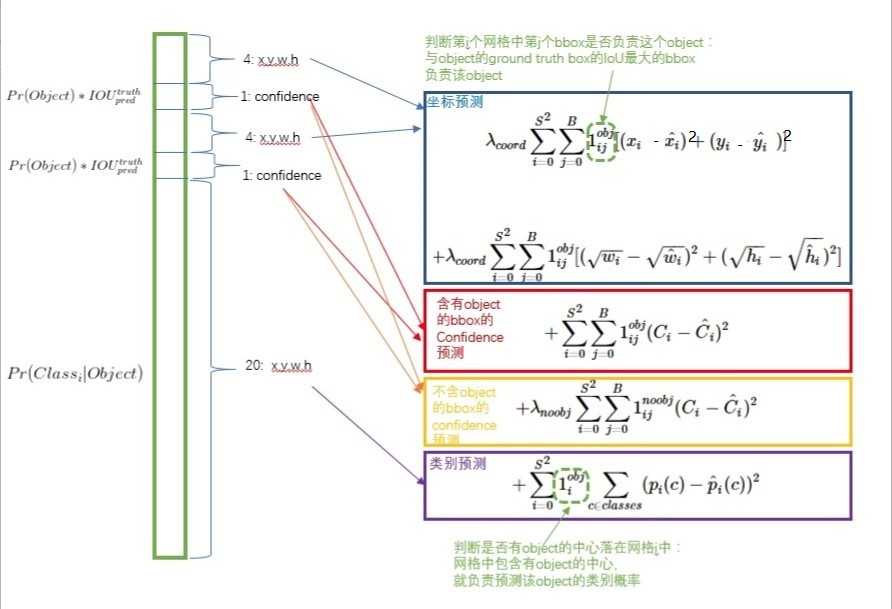
YOLO网络的输出实际上包含了三部分信息:bbox的位置信息,每个bbox的confidence以及每个grid cell的类别条件概率。 目标函数也就包含的三个部分:
\[
\begin{align*}
& \lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{ij}^{obj}\left(x_i - \hat{x_i})^2 + (y_i - \hat{y_i)^2}) \right] + \lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{ij}^{obj} \left[(\sqrt{w_i} - \sqrt{\hat{w_i}})^2 + (\sqrt{h_i} - \sqrt{\hat{h_i}})^2 \right] \\& + \sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{ij}^{obj}(C_i - \hat{C_i})^2 + \lambda_{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{ij}^{noobj}(C_i - \hat{C_i})^2 \\& +
\sum_{i=0}^{S^2}1_{i}^{obj}\sum_{c \in classes}(p_i(c) - \hat{p_i)(c))^2})
\end{align*}
\]
很长的损失函数,首先来看两个超参\(\lambda_{coord}\)和\(\lambda_{noobj}\).
由于要将bbox的位置信息,confidence以及类别的概率放到同一个目标函数中,而且各个分量占的输出数据的多少也相差很多(位置信息只占了8个维度,而类别则占了20个维度),如果只是简单的使用方差作为损失则很难对三个要优化的目标做好平衡:
针对上述问题,损失函数中使用权重来解决。
为了平衡没有目标的grid cell,给没有目标的损失设较小的权重,论文中设置的是\(\lambda_{noobj} = 0.5\)
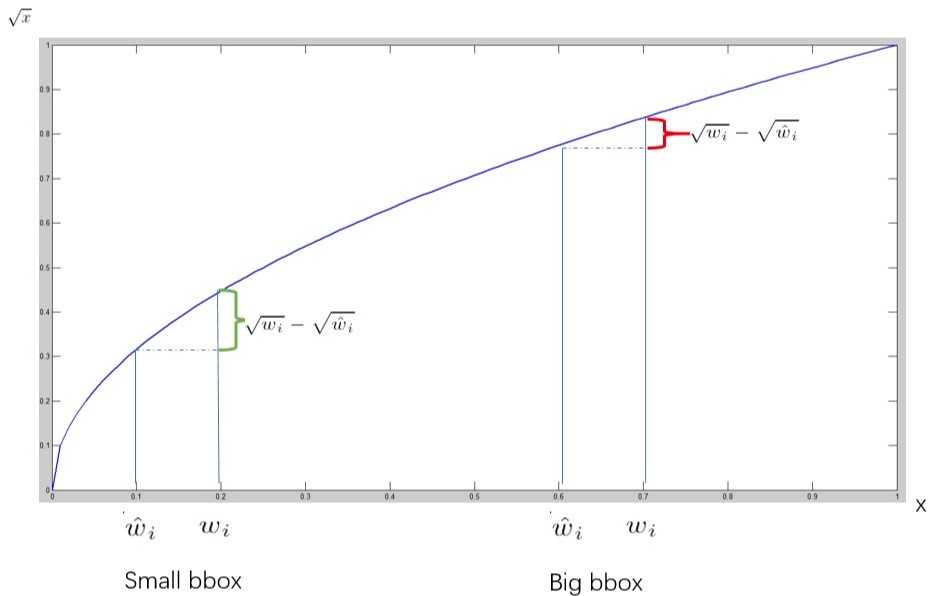 相同的位置偏移,反应在小目标的偏移损失比大目标预测的bbox要大。
相同的位置偏移,反应在小目标的偏移损失比大目标预测的bbox要大。公式的第二行是bbox的confidence的损失。 YOLO中一个目标被一个grid cell负责检测,而同一个grid cell生成的\(B\)个bbox,也是和目标的 ground truth 的IoU负责。这样就会有大量的bbox是不负责检测目标的,也就是\(1_{ij}^{obj} = 0,1_{ij}^{noobj}=1\),而且由于包含目标的bbox较不包含目标的bbox要多很多,这里使用权值\(\lambda_{noobj}\)作为平衡,论文中使用\(\lambda_{noobj}=0.5\)
公式的第三行是grid cell的类别条件概率损失. \(1_{i}^{obj}\)表示第\(i\)个grid cell是否负责一个目标的检测。
下图能更好的解释YOLO损失函数的意义
输入图片,网络会按照与训练时相同的分割方式将测试图片分割成\(S \times S\)的网格,因此,划分出来的每个网格预测的class信息和Bounding box预测的confidence信息相乘,就得到了每个Bounding box的class-specific confidence score,即得到了每个Bounding box预测具体物体的概率和Ground Truth重叠的好坏。
对于论文中,图片划分为\(7 \times 7\)的网格,最终会得到98个bbox。要分类的目标有20个类给,这样每个bbox对得到20个分数,表示该bbox在20个对象的得分。根据这20个得分情况,对98个bbox进行最大值抑制NMS,选出每个类别的最终bbox。
NMS的步骤如下:
1. 设置一个Score的阈值(0.2),低于该阈值的候选对象排除掉(将该Score设为0)。
2. 遍历20个对象(找到每个对象的最好的bbox)
2.1 遍历所有的98个bbox
2.1.1 选择socre最大的bbox添加到输出列表中
2.1.2 将计算余下的bbox的和score最大的bbox的IoU,如果大于设定的IoU阈值(0.5),则将该bbox的socre 设置为0.
2.1.3 从余下的bbox中选择score最大的,重复上面的过程,直到所有的bbox要么在输出列表中,要不其socre为0
2.2 输出列表中bbox即为当前类的预测bboxYOLO是one-stage的目标检测网络,其优点:
缺点:
标签:简单 可行性 概率 精度 提取 包含 向量 重要 函数
原文地址:https://www.cnblogs.com/wangguchangqing/p/10406367.html