标签:size 输入 实现 速度 倾斜 nmap nta spl 过滤
MapReduce Top N 、二次排序,MapJoin:
对于一组输入List(key,value),我们要创建一个Top N 列表,这是一种过滤模式,查看输入数据特定子集,观察用户的行为。
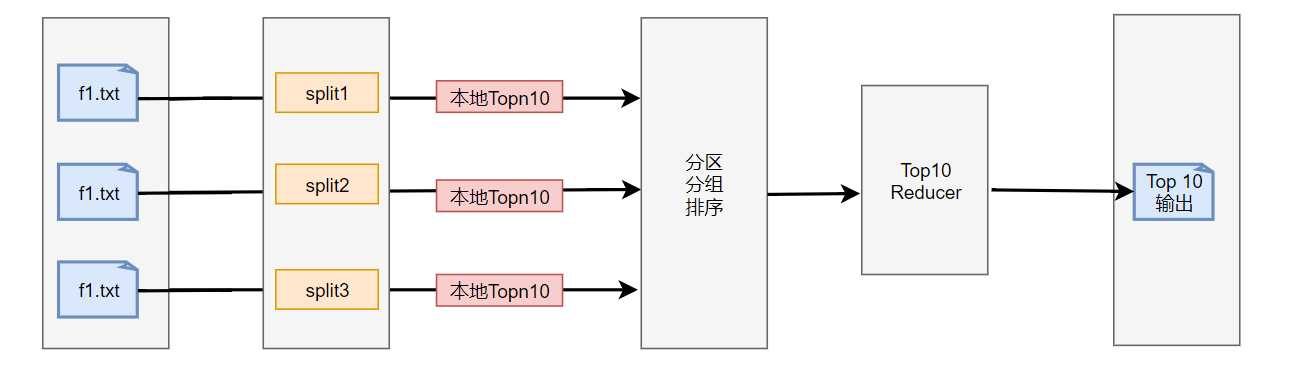
key是唯一键,需要对输入进行额外的聚集处理,先把输入分区成小块,然后把每个小块发送到一个映射器中。每个映射器会创建一个本地Top N 列表发送到一个规约器中,即最终由一个规约其产生一个Top N 列表。对于大多数的MapReduce算法,由一个规约器接收所有数据会使负载不均衡,从而产生瓶颈问题。但是本解决方案产生的Top N 是很少量的数据,如果有映射器,则会需要处理1000 X N的数据。
计算过程以K V对传输
可以创建一个最小堆,最常用的是SortMap<K,V> 和TreeMap<K,V>,如果top N.size()>N,则删除第一个元素(频数最小)如果求Bottom N构造最大堆。
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.TreeMap;
public class TopTenMapper extends Mapper<Object, Text, NullWritable, Text> {
private TreeMap<Integer, Text> visitimesMap = new TreeMap<Integer, Text>();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
if (value == null) {
return;
}
String[] strs = value.toString().split(" ");
String tId = strs[0];
String reputation = strs[1];
if (tId == null || reputation == null) {
return;
}
visitimesMap.put(Integer.parseInt(reputation), new Text(value));
if (visitimesMap.size() > 10) {
visitimesMap.remove(visitimesMap.firstKey());
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
for (Text t : visitimesMap.values()) {
context.write(NullWritable.get(), t);
}
}
}
Reduce
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.TreeMap;
public class TopTenReduce extends Reducer<NullWritable, Text, NullWritable, Text> {
private TreeMap<Integer, Text> visittimesMap = new TreeMap<Integer, Text>();
@Override
protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
String[] strs = value.toString().split(" ");
visittimesMap.put(Integer.parseInt(strs[1]), new Text(value));
if (visittimesMap.size() > 10) {
visittimesMap.remove(visittimesMap.firstKey());
}
}
for (Text t : visittimesMap.values()) {
context.write(NullWritable.get(), t);
}
}
}
Job
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TopTenJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
if (args.length != 2) {
System.out.println("Usage:TopTenDriver<in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf);
job.setJarByClass(TopTenJob.class);
job.setMapperClass(TopTenMapper.class);
job.setReducerClass(TopTenReduce.class);
job.setNumReduceTasks(1);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
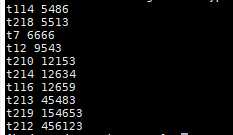
结果
假设所有的输入键是不唯一的,即会出现key相同而value不同的情况,则需要为两个阶段解决。
第一阶段:通过MapReduce先聚集具有相同键的元组,并将频数相加,将不唯一的键转换为唯一的键,其value值为频数和,输出为唯一键值对<key,value>
第二阶段:将第一阶段的输出的唯一键值对作为输入,采用唯一键的解决方案求Top N 即可。
创建随机数据
for i in {1..100000};
do
echo $RANDOM
done;
sh createdata.sh >data1 sh createdata.sh >data2 sh createdata.sh >data3 sh createdata.sh >data4
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<IntWritable, IntWritable> {
public int getPartition(IntWritable key, IntWritable value, int numPartitions) {
int keyInt = Integer.parseInt(key.toString());
if (keyInt > 20000) { //数据区间在在[0,350000]随机生成概率比较均匀.
return 2;
} else if (keyInt > 10000) {
return 1;
} else {
return 0;
}
}
}
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class Mysort extends WritableComparator {
public Mysort() {
super(IntWritable.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
IntWritable v1 = (IntWritable) a;
IntWritable v2 = (IntWritable) b;
return v2.compareTo(v1);
}
}
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class SimpleMapper extends Mapper<LongWritable, Text, IntWritable,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将Text类的value转换为IntWritable类型
IntWritable intvalue = new IntWritable(Integer.parseInt(value.toString()));
//值写入context
context.write(intvalue,intvalue);
}
}
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SimpleReducer extends Reducer<IntWritable, IntWritable, IntWritable, NullWritable> {
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
for (IntWritable value : values) {
context.write(value, NullWritable.get());
}
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SimpleJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SimpleJob.class);
job.setPartitionerClass(MyPartitioner.class);
job.setSortComparatorClass(Mysort.class);
job.setMapperClass(SimpleMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(SimpleReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(3);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
自定分区下实现用户按业务分区与Reduce任务数据一 一对于,使用全排序最终的解结果在文件中一次按顺序输出,可能存在认为对数据了解不够多,造成分区的数据个数不一致,导致发生数据倾斜的问题。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.InputSampler;
import org.apache.hadoop.mapreduce.lib.partition.TotalOrderPartitioner;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class TotalOrderingPartition extends Configured implements Tool {
//Map类
static class SimpleMapper extends Mapper<Text, Text, Text, IntWritable> {
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
IntWritable intWritable = new IntWritable(Integer.parseInt(key.toString()));
context.write(key, intWritable);
}
}
//Reduce类
static class SimpleReducer extends Reducer<Text, IntWritable, IntWritable, NullWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
for (IntWritable value : values) {
context.write(value, NullWritable.get());
}
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = Job.getInstance(conf);
job.setJarByClass(TotalOrderingPartition.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setNumReduceTasks(3);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
TotalOrderPartitioner.setPartitionFile(job.getConfiguration(), new Path(args[2]));
InputSampler.Sampler<Text, Text> sampler = new InputSampler.SplitSampler<Text, Text>(1000, 10);
InputSampler.writePartitionFile(job, sampler);
job.setPartitionerClass(TotalOrderPartitioner.class);
job.setMapperClass(SimpleMapper.class);
job.setReducerClass(SimpleReducer.class);
job.setJobName("Ite Blog");
return job.waitForCompletion(true) ? 0 : 1;
}
//主方法
public static void main(String[] args) throws Exception {
args = new String[]{"/input/simple","/output/random_simple1","/output/random_simple2"};
int exitCode = ToolRunner.run(new TotalOrderingPartition(), args);
System.exit(exitCode);
}
}
通过抽样分区,可以使个分区所含的记录大致相等,使作业的总体执行时间不会因为一个Reducer任务之后而拖慢整体进度。
二次排序不同于全排序,它在规约阶段对与中间键相关联的中间值的某个属性进行排序。可以对传如各个Reducer的值进行升序或降序排序,即首先按照第一个字段排序,在对第二个字段相同的排序,且不能破坏第一个排序结果。
流程
构造组合键(k,v1),其中v1是次键,K为自然键值,要在Reduce中注入一个值(v1)或者一个组合键。Reducer值按照什么来排序,就将其加入到自然键中,共同称为组合键。
对于Key=k2,若所有的映射器生成键值对为(k2,A1),(k2,A2),…(k2,An),对于一每个Ai,对于一个每一个Ai,设Ai为一个m元组值(ai2,ai3,…,aim)用bi来表示。因而映射器生成键值对可以做如下表示:
(k2,(a1,b1)),(k2(a2,b2)),…(k2,(an,bn))
自然键位k2,加入ai形成组合键((k2,ai))最终的映射器发出键值对如下:
((k2,a1),(a1,b1)),((k2,a2),(a2,b2)),….((k2,an),(an,bn))
在分区器中加入两个插件类:定制分区器,确保相同自然键的数据到达相同Reducer,也就是说,同一Reducer中可能由key=k2,key=k3的所有数据,定制比较器就将这些数据按照自然键进行分组。
分组比较器,可以使v1按有序的顺序到达Reducer,使用MapReduce执行框架完成排序,可以保证到达Reducer的值按键有序并按值有序。
实现类
MyWritable
import java.io.*;
import org.apache.hadoop.io.*;
public class MyWritable implements WritableComparable<MyWritable> {
private int first;
private int second;
public MyWritable() {
}
public MyWritable(int first, int second) {
set(first, second);
}
public void set(int first, int second) {
this.first = first;
this.second = second;
}
public int getFirst() {
return first;
}
public int getSecond() {
return second;
}
public void write(DataOutput out) throws IOException {
out.writeInt(first);
out.writeInt(second);
}
public void readFields(DataInput in) throws IOException {
first = in.readInt();
second = in.readInt();
}
@Override
public int hashCode() {
return first * 163 + second;
}
@Override
public boolean equals(Object o) {
if (o instanceof MyWritable) {
MyWritable ip = (MyWritable) o;
return first == ip.first && second == ip.second;
}
return false;
}
@Override
public String toString() {
return first + "\t" + second;
}
public int compareTo(MyWritable ip) {
int cmp = compare(first, ip.first);
if (cmp != 0) {
return cmp;
}
return compare(second, ip.second);
}
public static int compare(int a, int b) {
return (a < b ? -1 : (a == b ? 0 : 1));
}
}
MyComparator
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class MyComparator extends WritableComparator {
protected MyComparator() {
super(MyWritable.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
MyWritable ip1 = (MyWritable) w1;
MyWritable ip2 = (MyWritable) w2;
int cmp = MyWritable.compare(ip1.getFirst(), ip2.getFirst());
if (cmp != 0) {
return cmp;
}
return -MyWritable.compare(ip1.getSecond(), ip2.getSecond());
}
}
MyPartitioner
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<MyWritable, NullWritable> {
@Override
public int getPartition(MyWritable key, NullWritable value, int numPartitions) {
return (key.hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
MyGroup
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class MyGroup extends WritableComparator {
protected MyGroup() {
super(MyWritable.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
MyWritable ip1 = (MyWritable) w1;
MyWritable ip2 = (MyWritable) w2;
return MyWritable.compare(ip1.getFirst(), ip2.getFirst());
}
}
SecondarySortMapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class SecondarySortMapper extends
Mapper<LongWritable, Text, MyWritable, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
String year = strs[0];
String Temperature = strs[1];
if (year == null || Temperature == null) {
return;
}
context.write(
new MyWritable(Integer.parseInt(strs[0]), Integer
.parseInt(strs[1])), NullWritable.get());
}
}
SecondarySortReducer
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class SecondarySortReducer extends
Reducer<MyWritable, NullWritable, MyWritable, NullWritable> {
@Override
protected void reduce(MyWritable key, Iterable<NullWritable> values,
Context context) throws IOException, InterruptedException {
for (NullWritable val : values) {
context.write(key, NullWritable.get());
}
}
}
SecondarySortJob
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SecondarySortJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SecondarySortJob.class);
job.setMapperClass(SecondarySortMapper.class);
job.setPartitionerClass(MyPartitioner.class);
job.setSortComparatorClass(MyComparator.class);
job.setGroupingComparatorClass(MyGroup.class);
job.setReducerClass(SecondarySortReducer.class);
job.setOutputKeyClass(MyWritable.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(1);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
原始数据
2016 32 2017 38 2016 31 2016 39 2015 35 2017 34 2016 37 2017 36 2018 35 2015 31 2018 34 2018 33
排序后数据
2015 35 2015 31 2016 39 2016 37 2016 32 2016 31 2017 38 2017 36 2017 34 2018 35 2018 34 2018 33
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class TableBean implements Writable {
private String orderId;
private String pid;
private int amount;
private String pname;
private String flag;
public TableBean() {
super();
}
public TableBean(String orderId, String pid, int amount, String pname, String flag) {
super();
this.orderId = orderId;
this.pid = pid;
this.amount = amount;
this.pname = pname;
this.flag = flag;
}
@Override
public String toString() {
return orderId + "\t" + pname + "\t" + amount;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeUTF(pid);
out.writeInt(amount);
out.writeUTF(pname);
out.writeUTF(flag);
}
@Override
public void readFields(DataInput in) throws IOException {
orderId = in.readUTF();
pid = in.readUTF();
amount = in.readInt();
pname = in.readUTF();
flag = in.readUTF();
}
}
TableMapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class TableMapper extends Mapper<LongWritable, Text, Text, TableBean>{
Text k = new Text();
TableBean tableBean = new TableBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取文件名
FileSplit split = (FileSplit) context.getInputSplit();
String name = split.getPath().getName();
//判断
String line = value.toString();
if (name.startsWith("order")){
String[] fields = line.split("\t");
tableBean.setOrderId(fields[0]);
tableBean.setPid(fields[1]);
tableBean.setAmount(Integer.parseInt(fields[2]));
tableBean.setPname("");
tableBean.setFlag("0");
k.set(fields[1]);
context.write(k, tableBean);
}else {
String[] fields = line.split("\t");
tableBean.setOrderId("");
tableBean.setPid(fields[0]);
tableBean.setAmount(0);
tableBean.setPname(fields[1]);
tableBean.setFlag("1");
k.set(fields[0]);
context.write(k, tableBean);
}
}
}
TableReducer
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
import java.util.List;
public class TableReducer extends Reducer<Text, TableBean, NullWritable, TableBean> {
//1001 01 1
//01 小米
@Override
protected void reduce(Text key, Iterable<TableBean> values, Context context) throws IOException, InterruptedException {
//用来接收order表的数据
List<TableBean> orderBeans = new ArrayList<>();
//用来接受pd表的数据
TableBean pBean = new TableBean();
for (TableBean value : values){
//order表
if (value.getFlag().equals("0")){
TableBean oBean = new TableBean();
try {
BeanUtils.copyProperties(oBean, value);
orderBeans.add(oBean);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}else {
//pd.txt
try {
BeanUtils.copyProperties(pBean, value);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
for (TableBean orderbean : orderBeans){
orderbean.setPname(pBean.getPname());
context.write(NullWritable.get(),orderbean);
}
}
}
TableDriver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TableDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 指定本程序的jar包所在的本地路径
job.setJarByClass(TableDriver.class);
// 3 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(TableMapper.class);
job.setReducerClass(TableReducer.class);
// 4 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TableBean.class);
// 5 指定最终输出的数据的kv类型
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(TableBean.class);
// 6 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
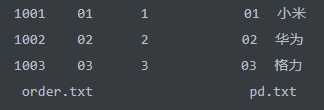
原始数据
结果
1001 小米 1 1002 华为 2 1003 格力 3
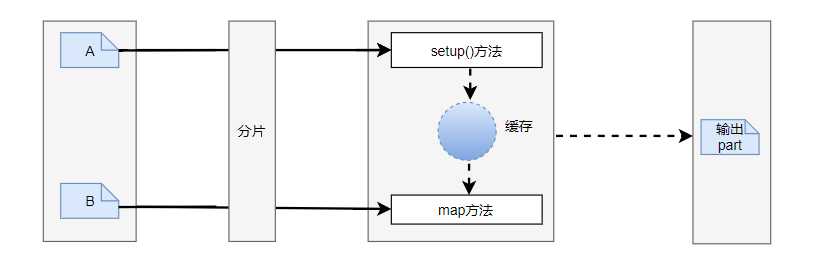
DistributedCacheMapper
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
public class DistributedCacheMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
Text k = new Text();
HashMap<String, String> map = new HashMap<>();
/**
* 先缓存pd表
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] cacheFiles = context.getCacheFiles();
//获取输入字节流
FileInputStream fis = new FileInputStream(cacheFiles[0].getPath());
//获取转换流
InputStreamReader isr = new InputStreamReader(fis, "UTF-8");
//获取缓存流
BufferedReader br = new BufferedReader(isr);
String line = null;
//开始一行一行读数据
while (StringUtils.isNotEmpty(line = br.readLine())) {
String[] fields = line.split("\t");
//将数据放入map中
map.put(fields[0],fields[1]);
}
fis.close();
isr.close();
br.close();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行
String line = value.toString();
//通过pid获取pname
String[] fields = line.split("\t");
String pid = fields[1];
String pname = map.get(pid);
String str = line + "\t" + pname;
k.set(str);
context.write(k, NullWritable.get());
}
}
DistributedCacheDriver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
public class DistributedCacheDriver {
public static void main(String[] args) throws Exception {
// 1 获取job信息
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置加载jar包路径
job.setJarByClass(DistributedCacheDriver.class);
// 3 关联map
job.setMapperClass(DistributedCacheMapper.class);
// 4 设置最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 5 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 加载缓存数据写入内存 默认是本地路径
job.addCacheFile(new URI(args[2]));
// 7 map端join的逻辑不需要reduce阶段,设置reducetask数量为0
job.setNumReduceTasks(0);
// 8 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
这种方法的运行速度很快,输入数据进行Mapper计算前分了部分,启用了一个Mapper,而Reducer连接时启动了两个Mapper.但该种计算模式受到JVM种堆的分配限制,如果集群中的内存足够大,业务符合逻辑(如内连接和做外连接)时可以考虑这种计算模式,如果数据集很大,Reducer连接操作是一个很不错的选择.当然连接操作的思想还有一些其他的方法,可以根据业务不同,采取不同的编程思想。
标签:size 输入 实现 速度 倾斜 nmap nta spl 过滤
原文地址:https://www.cnblogs.com/fmgao-technology/p/10416644.html