标签:依赖 point hadoop 传递 用户 组成 inf 概念 ips
多用于本地测试,如在eclipse,idea中写程序测试等。
Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
资源调度框架。
¬ 要基于Yarn来进行资源调度,必须实现AppalicationMaster接口,Spark实现了这个接口,所以可以基于Yarn。
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
https://blog.csdn.net/zym1117/article/details/79532458
RDD是一个由多个partition(某个节点里的某一片连续的数据)组成的的list;将数据加载为RDD时,一般会遵循数据的本地性(一般一个hdfs里的block会加载为一个partition)。
一个函数计算每一个分片,RDD的每个partition上面都会有function,也就是函数应用,其作用是实现RDD之间partition的转换。
RDD会记录它的依赖 ,依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。为了容错(重算,cache,checkpoint),也就是说在内存中的RDD操作时出错或丢失会进行重算。
可选项,如果RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区,例如这里自定义的Partitioner是基于key进行分区,那则会将不同RDD里面的相同key的数据放到同一个partition里面
最优的位置去计算,也就是数据的本地性
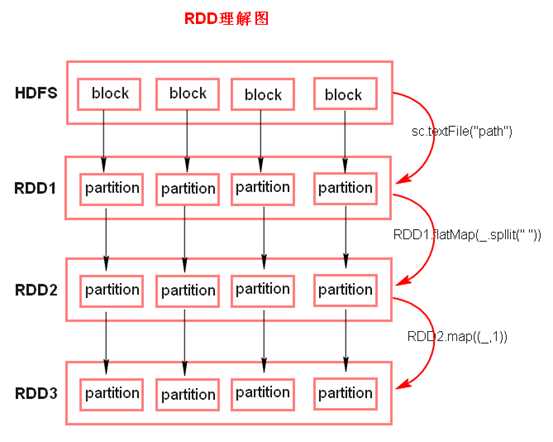
¬ textFile方法底层封装的是读取MR读取文件的方式,读取文件之前先split,默认split大小是一个block大小。
¬ RDD不存储数据
¬ 什么是K,V格式的RDD?
¬ 哪里体现RDD的弹性(容错)?
¬ 哪里体现RDD的分布式?
¬ RDD提供计算最佳位置,体现了数据本地化。体现了大数据中“计算移动数据不移动”的理念。
标签:依赖 point hadoop 传递 用户 组成 inf 概念 ips
原文地址:https://www.cnblogs.com/kpsmile/p/10421338.html