标签:函数 width 运行环境 dag 创建 根据 开始 组成 park
Spark运行模式
一:Spark 运行架构介绍
相关术语概念详解:
Application:指的是用户编写的Spark应用程序,包含了一个Driver功能的代码和分布在集群中多节点上运行的Executor代码。
Driver:Spark中的Driver就是运行Application的main()函数,并且创建SparkContext。SparkContext为Spark准备运行环境,它负责和ClusterManager通信,进行资源的申请、任务的分配和监控,当Executor部分运行完毕后,负责将SparkContext关闭。
Worker:集群中运行Application代码的节点。可以理解为服务器。
Executor:Application运行在work节点上的一个进程,该进程负责运行task。(理解work节点上的一个进程,来执行Driver的任务task)
ClusterManager:在集群上获取资源的外部服务。
Job(作业):包含多个task组成的并行计算。rdd包括转换和运行Action,只要有一个Action就是一个Job。
Stag(阶段):每个Job会被拆分成多组task。
Task(任务):最终被推送的到Executor进程上的任务。
Spark基本任务流程图
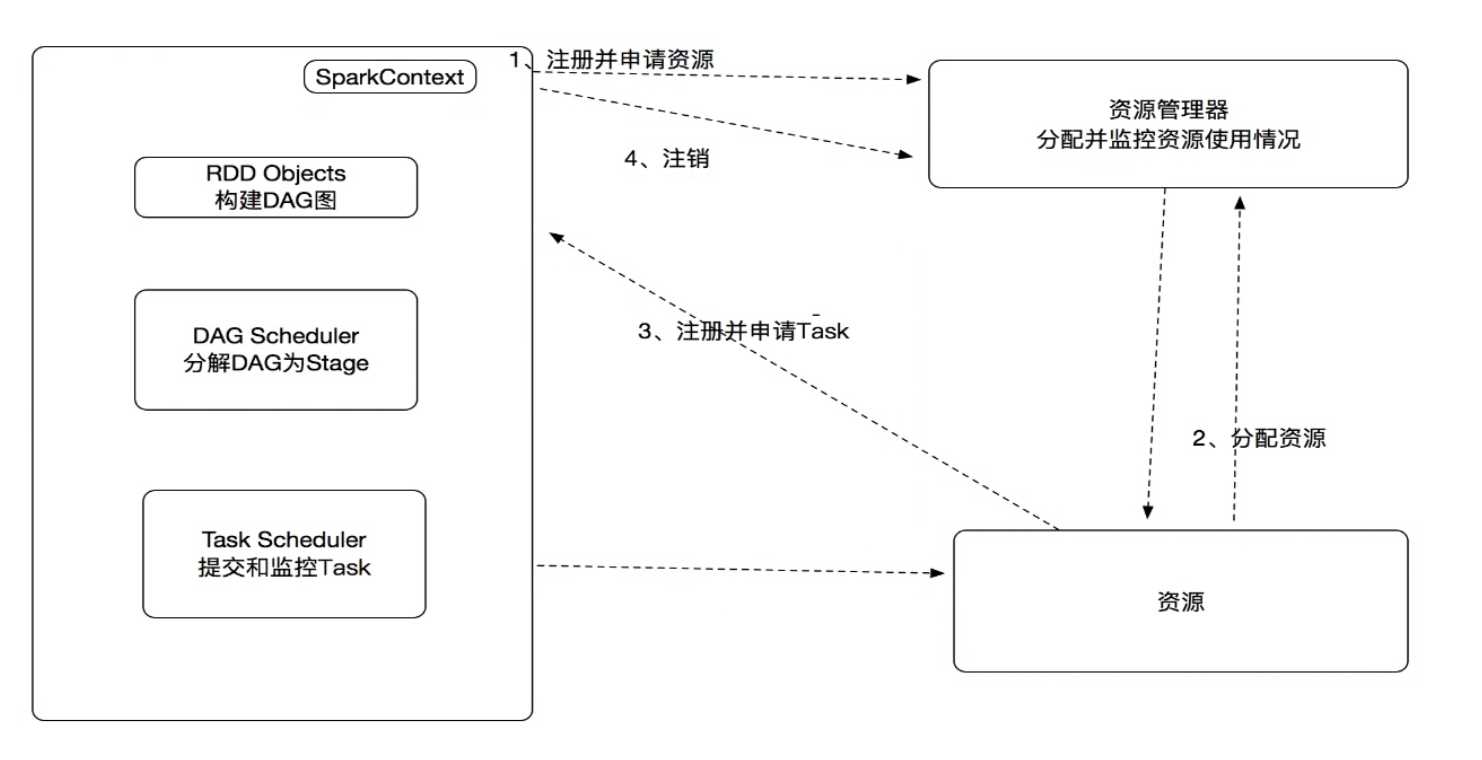
1:构建Spark Application的运行环境 ,启动sparkContext,sc注册并申请Executor
2:资源管理器分配Executor资源并启动 ****ExecutorBackend,Executor运行状态随着心跳发送到资源管理器
3:SC开始构建DAG(有向无环图),DAG开始分解成stage,并且有TaskSet发送给Task Scheduler 。Executor想SC申请Task。
DAGSchuduler
DAGSchuduler把一个Spark作业换成Stage的DAG,根据RDD和Stage之间的关系找出开销最小的调度方法,然后把Stage以TaskSet的形式提交给TaskScheduler。
TaskScheduler
TaskScheduler维护所有的TaskSet,当Executor向Driver发送心跳时,TaskScheduler会根据其资源剩余情况分配相应的Task。

上图是读取一个文件,spark解析为,一个Job,两个stage ,name下有33个文件,那么就有66个文件,这样就有66个task。
Spark 架构原理介绍 以及 job、task、stag 概念
标签:函数 width 运行环境 dag 创建 根据 开始 组成 park
原文地址:https://www.cnblogs.com/Tonyzczc/p/10421521.html