标签:依赖关系 text 计算 transform spark family 运行 加载 job
Spark-RDD 模型 以及运行原理
数据:在内存中计算,数组、list、set
spark:RDD是弹性分布性数据集合,并且是基于分区的只读记录。
RDD:操作类型(转换-Transformaction 和 行动-Action)
转换:Transformaction:根据原有的RDD创建一个新的RDD 。行动:Action是把RDD的操作返回给Driver。
所有的转换都是基于lazy模式(懒加载)。只有遇到Action的时候才开始执行。
RDD的依赖关系:job -> stag
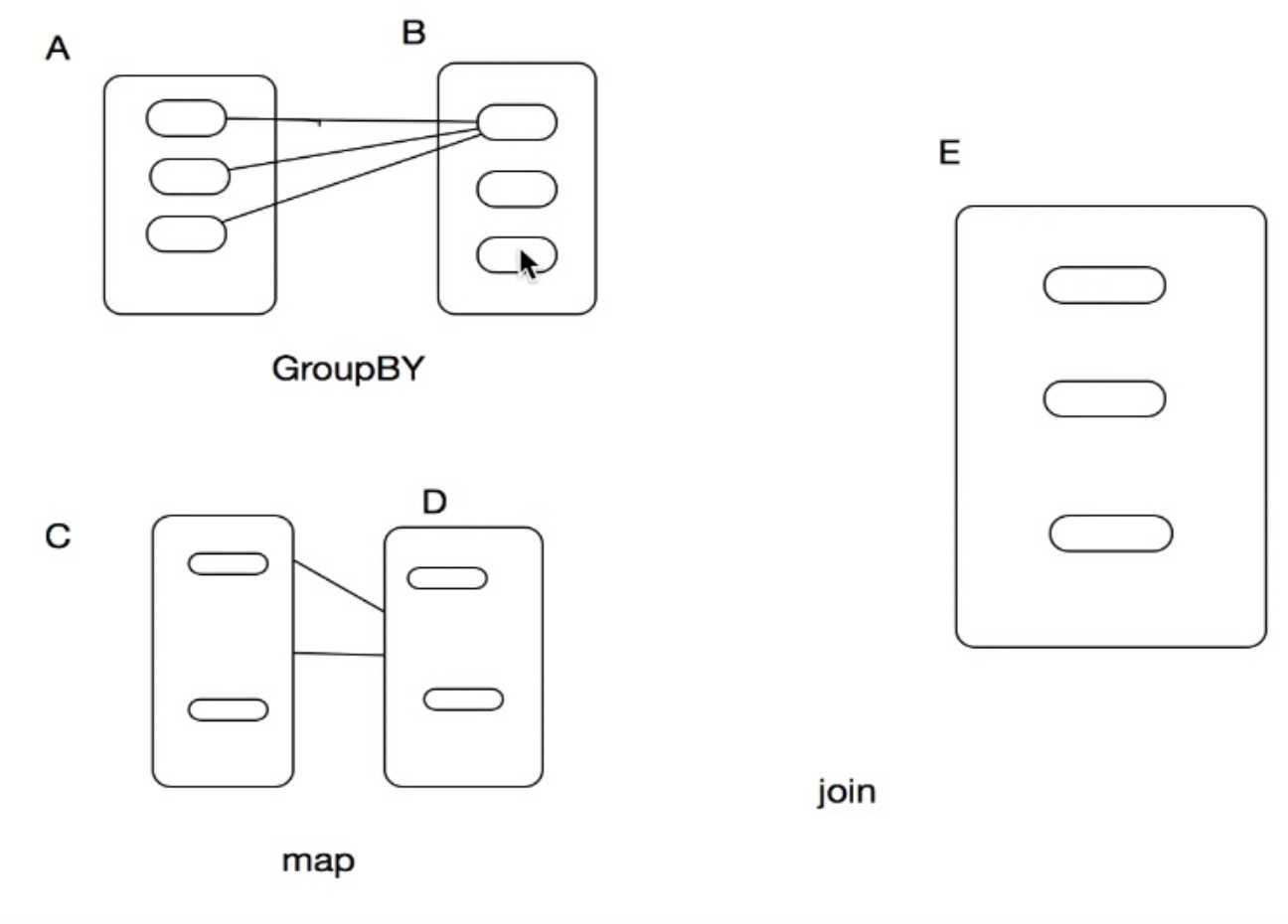
宽依赖,窄依赖
宽依赖:RDD的每个partition都依赖于父RDD的所有Partition。
窄依赖:只依赖一个或部分的Partition。
RDD分区与并行度
可以通过配置 spark.default.parallesism 的设置
标签:依赖关系 text 计算 transform spark family 运行 加载 job
原文地址:https://www.cnblogs.com/Tonyzczc/p/10421525.html