标签:好的 for row crontab sch mamicode 17. amp 表数
1、什么是统计信息?
统计信息就是数据库的侦察兵,记录了表和表中一些列的一些信息,一般SQL指定执行计划的时候都要先看表的统计信息,以决定执行计划的选择。
表的统计信息一般在dba_tables中,表中列的统计信息一般在dba_tab_col_statistics

select table_name,column_name,num_distinct,num_nulls,last_analyzed,avg_col_len,histogram from dba_tab_col_statistics where table_name=‘TEST‘;

没有收集统计系信息之前,dba_tables中记录的关于表的 num_rows和blocks都是空的。 dba_tab_col_statistics中是没有列的记录的。我们来看一下手机完统计信息的状态。

select table_name,column_name,num_distinct,num_nulls,last_analyzed,avg_col_len,histogram from dba_tab_col_statistics where table_name=‘TEST‘;
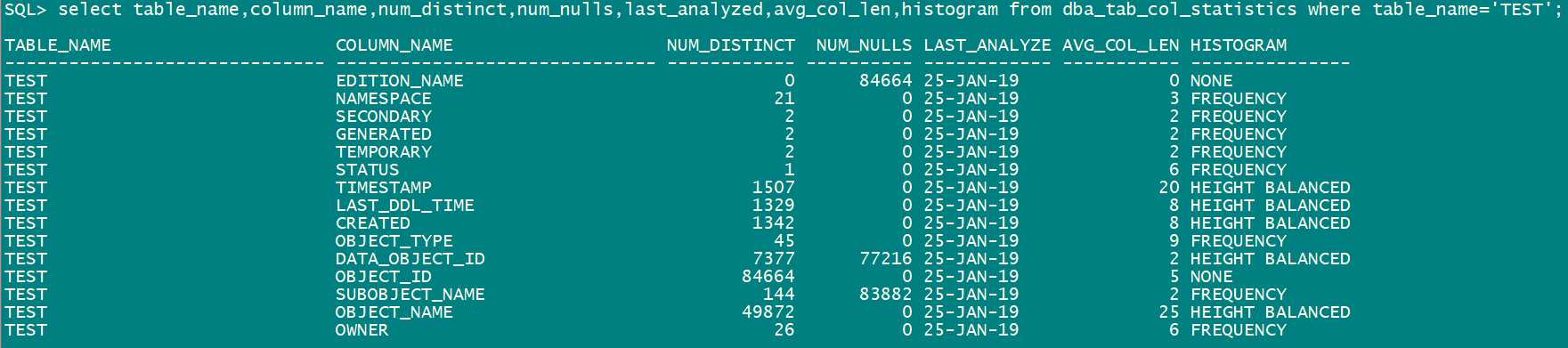
收集统计信息的过程:
1、将表有多少行,表中有多少个block 计算出来,记录到dba_tables中。(select count(*) from test; select SEGMENT_NAME,blocks from dba_segments where segment_name=‘TEST‘; )
2、计算表中每个列的基数,null值,平均的行长度等,记录到基表中。
采样率:
一个表是由块组成的,如果采样率不是100%有些块就会收集不到。如果采样率设置成30%,就会随机的抽取表中30%的块,进行统计信息的收集。
小表基本都是100%收集的。
一般经验: <1G 100% 1-5G 50% 5-10G 30% >10G一般为分区表了,老分区的数据一般是不会变的, 最新一个区的数据才会变化,所以一般是已分区为粒度来收集的。
(estimate_persent => 100)控制
收集直方图与否:
method_opt => for all columns size 1 不收集直方图
method_opt => for all columns size skewonly 收集直方图 (没收集直方图之前histogram是none,num_bucket是0)
自动收集直方图时,Oracle对直方图的选择, FREQUENCY ----频率直方图(基数小于254时使用) HEIGHT BALANCED ------ 等高直方图(基数大于254时使用) NONE distinct值=行数 或者distinct值为0的时候不收集
生产中不可以使用这个选项,因为表我们只对where中的列和基数很低的列收集。。这个选项会收集所有列的
method_opt => for all columns size auto 这个是10g、11g、12c中收集统计信息的默认选项,自动根据where条件中的信息对列有选择性的收直方图(只收集出现在where条件中并且基数很低的列)。也是官方推荐的方式
Oracle怎么判断哪些列在where条件中呢? begin dbms_stats.flush_database_monitoring_info;end;--将内存中的统计数据刷出去【这个在生产上也可以随便刷,就是将内存中的数据刷到磁盘上,这个数据非常小,不会刷死库的】 (默认是由smon刷的,15min一次) select r.name owner, o.name table_name, c.name column_name, equality_preds,----等值过滤的次数 equijoin_preds,----等值过滤join,比如where a.id=b.in range_preds,----范围过滤,比如><and,between like_preds,----like过滤 null_preds,----null过滤 timestamp from sys.col_usage$ u,sys.obj$ o,sys.col$ c,sys.user$ r where o.obj# = u.obj# and c.obj# = u.obj# and c.col# = u.intcol# and r.name = ‘SCOTT‘ and o.name = ‘TEST‘;
auto也不是万能的,比如 有些时候生产上的where条件是没有某些列的,但是我们私底下sqlplus查询时候查过这些列,也会导致这些列被auto收集。
method_opt => for all columns size repeat 延续上一次收集的方法,之前怎么收集的,这次还怎么收集
method_opt => for columns owner size auto 只针对owner列收集直方图 (下次如果是for all columns size repeat 还是只对owner收集直方图)
method_opt = > for columns owner,subobject_name size auto 对owner和subobject_name两列收集直方图(如果确定了哪些列要收集直方图,以后每次收集的时候都确定也可以不用repeat)
一般去新公司工作的时候用repeat (其实11g后用auto也可以)
新系统上线的时候用 1,不收集直方图,对跑得慢的列再收直方图,久而久之这个系统就稳定了
统计信息知识总结:
1、如何查看已收集了统计信息的一个表的采样率:
select owner,table_name,num_rows,sample_size, ceil(sample_size/num_rows*100) estimate_percent from dba_tab_statistics where owner = ‘SCOTT‘ and table_name = ‘TEST‘;

2、收集统计信息:
begin dbms_stats.gather_table_stats( ownname=>‘SCOTT‘, tabname=>‘TEST‘, estimate_percent=>30, method_opt=>‘for all columns size auto‘, no_invalidate=>FALSE, degree=>1, cascade=>true); end; /
3、收集完统计信息后,隔多久再收集一次?
3.1看统计信息是否过期。过期就需要收集。
判断统计信息是否过期:
begin dbms_stats.flush_database_monitoring_info; end; / select owner,table_name name,object_type,stale_stats, last_analyzed from dba_tab_statistics where table_name in (‘TEST‘) and owner = ‘SCOTT‘ and (stale_stats = ‘YES‘ or last_analyzed is null);
stale_stats为 no 就是没有过期,yes 就是过期了。

一个表有超过10%的数据变化,统计信息就会过期
3.2 怎么判断统计信息是因为什么过期的。
alter session set nls_date_format=‘yyyymmdd hh24:mi:ss‘;
col owner for a15 col table_name for a15 col partition_name for a20 col subpartition_name for a20 select * from ( select * from ( select * from ( select u.name owner,o.name table_name, null partition_name, null subpartition_name, m.inserts,m.updates,m.deletes,m.timestamp, decode(bitand(m.flags,1),1,‘YES‘,‘NO‘) truncated, m.drop_segments from sys.mon_mods_all$ m, sys.obj$ o,sys.tab$ t,sys.user$ u where o.obj# = m.obj# and o.obj#=t.obj# and o.owner# = u.user# union all select u.name,o.name,o.subname,null, m.inserts,m.updates,m.deletes,m.timestamp, decode(bitand(m.flags,1),1,‘YES‘,‘NO‘), m.drop_segments from sys.mon_mods_all$ m,sys.obj$ o,sys.user$ u where o.owner#=u.user# and o.obj#=m.obj# and o.type#=19 union all select u.name,o.name,o2.subname,o.subname, m.inserts,m.updates,m.deletes,m.timestamp, decode(bitand(m.flags,1),1,‘YES‘,‘NO‘), m.drop_segments from sys.mon_mods_all$ m,sys.obj$ o,sys.tabsubpart$ tsp,sys.obj$ o2, sys.user$ u where o.obj#=m.obj# and o.owner#=u.user# and o.obj# = tsp.obj# and o2.obj#=tsp.pobj# ) where owner not like ‘%SYS%‘ and owner not like ‘XDB‘ union all select * from ( select u.name owner,o.name table_name,null partition_name, null subpartition_name, m.inserts,m.updates,m.deletes,m.timestamp, decode(bitand(m.flags,1),1,‘YES‘,‘NO‘) truncated, m.drop_segments from sys.mon_mods$ m,sys.obj$ o,sys.tab$ t,sys.user$ u where o.obj#=m.obj# and o.obj#=t.obj# and o.owner#=u.user# union all select u.name,o.name,o.subname,null, m.inserts,m.updates,m.deletes,m.timestamp, decode(bitand(m.flags,1),1,‘YES‘,‘NO‘), m.drop_segments from sys.mon_mods$ m,sys.obj$ o,sys.user$ u where o.owner#=u.user# and o.obj#=m.obj# and o.type#=19 union all select u.name,o.name,o2.subname,o.subname, m.inserts,m.updates,m.deletes,m.timestamp, decode(bitand(m.flags,1),1,‘YES‘,‘NO‘), m.drop_segments from sys.mon_mods$ m,sys.obj$ o,sys.tabsubpart$ tsp,sys.obj$ o2, sys.user$ u where o.obj#=m.obj# and o.owner#=u.user# and o.obj# = tsp.obj# and o2.obj#=tsp.pobj# ) where owner not like ‘%SYS%‘ and owner not like ‘%XDB%‘ ) order by inserts desc ) where rownum<50;

该语句查询的是 最近一次收集统计信息后,到现在为止表数据量的变化。
该脚本可以用来监控系统中核心表的dml,也可以判断高水位线是否需要回收、索引是否需要重建,等等。
3.3 数据库有一个自动的job每天晚上自动收集统计信息。
如果有希望的计划任务,最好用OS的crontab不要用scheduler,scheduler会死,但是crontab不会
数据库自带的job收集统计信息是不好的,因为很有可能收集不完。
最好把db自带的收集统计信息的job停掉,然后自己定制收集方案。
标签:好的 for row crontab sch mamicode 17. amp 表数
原文地址:https://www.cnblogs.com/nathon-wang/p/10332255.html