标签:play embedding tun hashing tar rac fir wing layer
The whole system is consisted with Document Retriever and Document Reader. The Document Retriever returns top five Wikipedia articles given any question, then the Document Reader will process these articles.
The Retriever compares the TF-IDF weighted bag of word vectors between the articles and questions. And if take the word order into account with n-gram features, the performence will be better. In the paper, useing bigram counts performed best. It used hashing of (Weinberger et al., 2009) to map the bigrams to \(2^{24}\) bins with an unsigned murmur3 hash to preserv speed and memory efficiency.
The Document Reader was consisted of a multi-layer BiLSTM and a RNN layer. The input first was processed by a RNN, and then a multi-layer BiLSTM.
Only apply a recurrent NN on top of word embedding of \(q_i\) and combine the resulting hidden units into one single vector: \(\{q_1, \cdots, q_l\} \rightarrow q\). The \(q\) was computed as following:
\[
\begin{aligned}
& b_j = \frac{exp(w \cdot q_j)}{\sum_{j^`} exp(w \cdot q_{j^`})}\& q = \sum_j b_jq_j
\end{aligned}
\]
where \(b_j\) encodes the importance of each question word. I think the computation is very similar with the question self attention.
Take the \(p\) and \(q\) as input to train a classifier to predict the correct span positions.
\[\begin{aligned}
P_{start}(i) & \propto exp(p_iW_sq)\ P_{end}(i) & \propto exp(p_iW_eq)
\end{aligned}
\]
Then select the best span from token \(i\) and token \(i^`\) such that \(i \leq i^` \leq i+15\) and \(P_{start}(i) \times P_{end}(i^`)\) is maximized.
The ablation analysis result:
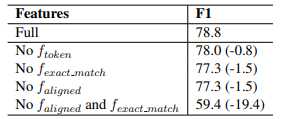
As the result showing, the aligned feature and exact_match feature are complementary and similar role as it does not matter when removing them respectively, but the performance drops dramatically wehn removing both of them.
标签:play embedding tun hashing tar rac fir wing layer
原文地址:https://www.cnblogs.com/ab229693/p/10425282.html