标签:引擎 程序员 高效 code 存在 pid loader temp 开发者
1.Scrapy框架介绍
写一个爬虫,需要做很多的事情。比如:发送网络请求、数据解析、数据存储、反反爬虫机制(更换ip代理、设置请求头等)、异步请求等。这些工作如果每次都要自己从零开始写的话,比较浪费时间。因此Scrapy把一些基础的东西封装好了,在他上面写爬虫可以变的更加的高效(爬取效率和开发效率)。因此真正在公司里,一些上了量的爬虫,都是使用Scrapy框架来解决。
2.Scrapy架构图
流程图1:
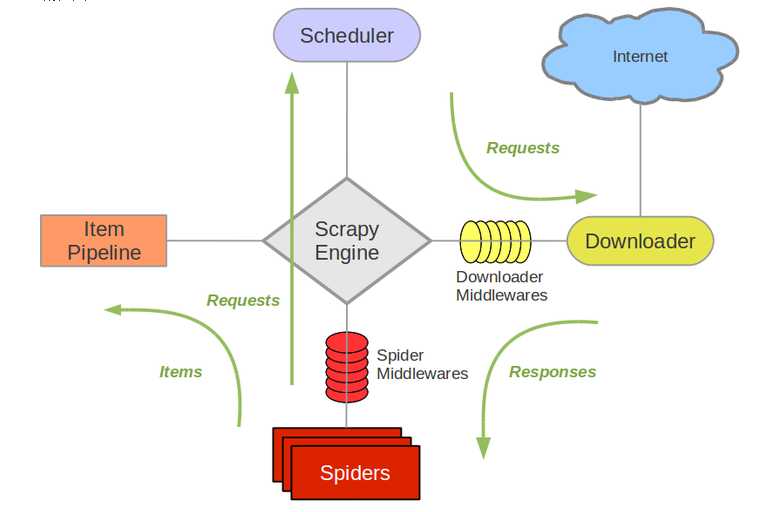
流程图2:
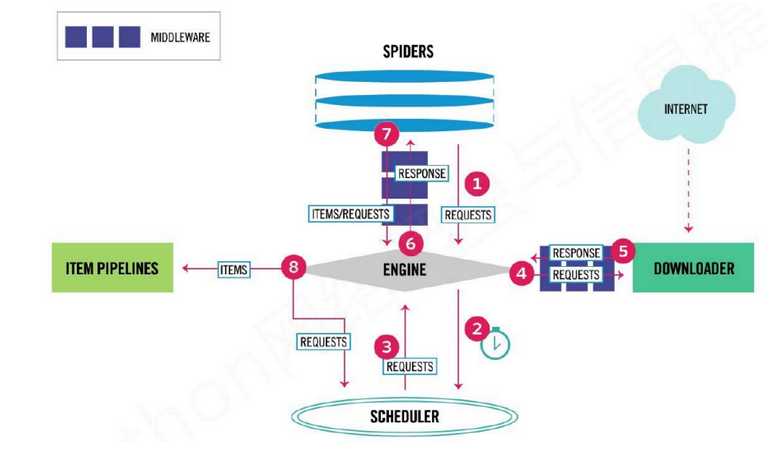
3.Scrapy框架模块功能
标签:引擎 程序员 高效 code 存在 pid loader temp 开发者
原文地址:https://www.cnblogs.com/apollo1616/p/10427116.html