标签:矩形 决定 形状 运算 间隔 包含 利用 mic 字幕
本文主要针对RNN与LSTM的结构及其原理进行详细的介绍,了解什么是RNN,RNN的1对N、N对1的结构,什么是LSTM,以及LSTM中的三门(input、ouput、forget),后续将利用深度学习框架Kreas,结合案例对LSTM进行进一步的介绍。
一、RNN的原理
RNN(Recurrent Neural Networks),即全称循环神经网络,它是一种对序列型的数据进行建模的深度模型。如图1.1所示。
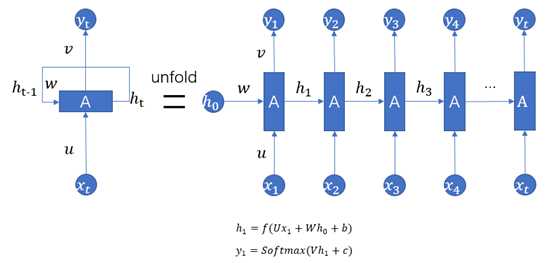
图1.1
1、其中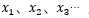 为序列数据。即神经网络的输入,例如nlp中,X1可以看作第一个单词、X2可以看作是第二个单词,依次类推。语音处理中,可以将
为序列数据。即神经网络的输入,例如nlp中,X1可以看作第一个单词、X2可以看作是第二个单词,依次类推。语音处理中,可以将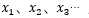 是每帧的声音信号。时间序列中,例如,某生活用品的销量数据。
是每帧的声音信号。时间序列中,例如,某生活用品的销量数据。
2、U、W、V是参数矩阵,b、c是偏置项,f是激活函数,通常采用”热撸”、tanh函数作为激活函数,用softmax将输出转换成各个类别的概率。
3、上图为经典的RNN结构,其运算过程可以表示为:
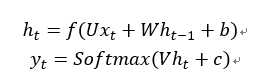
式中: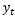 表示神经网络的输出;
表示神经网络的输出;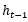 表示前一个时间点的状态;
表示前一个时间点的状态;
4、考虑到输入与输出的关系,序列问题具有以下分类:
一对多的RNN结构:序列输出,用于图像字幕,如图1.2所示。
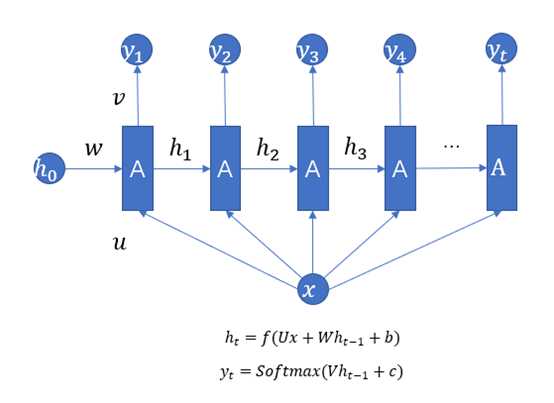
图1.2
多对一的RNN结构:序列输入,用于情感分类,如图1.3所示。
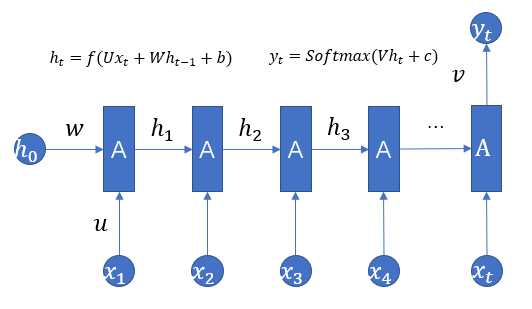
图1.3
多对多:序列输入和输出,用于机器翻译
同步多对多:同步序列输入和输出,用于视频分类
二、LSTM的原理
上面第一部分简单介绍了RNN的几种结构,接下来,介绍一下RNN的改进版:LSTM。LSTM(long short-term memory,长短时记忆网络),它的出现解决了很难处理的“长程依赖”问题,即无法学到序列中蕴含的间隔时间较长的规律。RNN每一层的隐状态都由前一层的隐状态经过变换和激活函数得到,反向传播求导时最终得到的导数会包含每一步梯度的连乘,将会引起梯度的消失或者梯度的爆炸。LSTM在隐状态使用了加法替代了每一步的迭代变换,这样便可以避免梯度消失的问题,从而使得网络学到长程的规律。
RNN可用图1.4表示
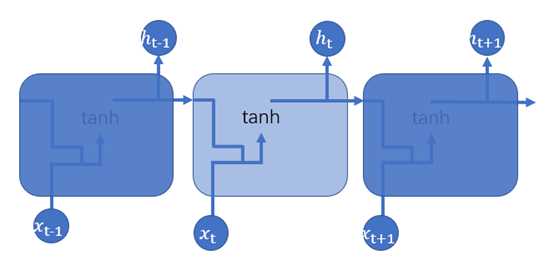
图1.4
同理,LSTM的结构图1.5所示
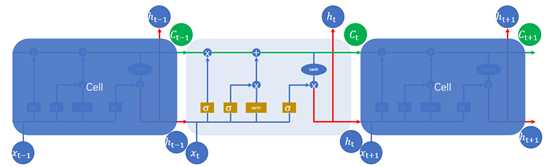
图1.5
其中图1.5中的符号,长方形表示对输入的数据做变换或激活函数;圆形表示逐点,逐点运算是指两个形状完全相同的矩形的对应位置进行相加、相乘或者其他的一些运算;箭头则表示向量会在那里进行运算。注意: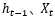 通过concat操作,才进入Sigmoid或tanh函数。
通过concat操作,才进入Sigmoid或tanh函数。
RNN与LSTM有所不同,LSTM的隐状态有两部分,一部分是ht ,另一部分则是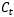 ,
,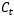 在各个步骤之间传递的主要信息,绿色的水平线可看作“主干道”,如图1.6所示。通过加法,
在各个步骤之间传递的主要信息,绿色的水平线可看作“主干道”,如图1.6所示。通过加法,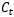 可以无障碍的在这条主干道上传递,因此较远的梯度也可以在长程上传播,这便是LSTM的核心思想。
可以无障碍的在这条主干道上传递,因此较远的梯度也可以在长程上传播,这便是LSTM的核心思想。
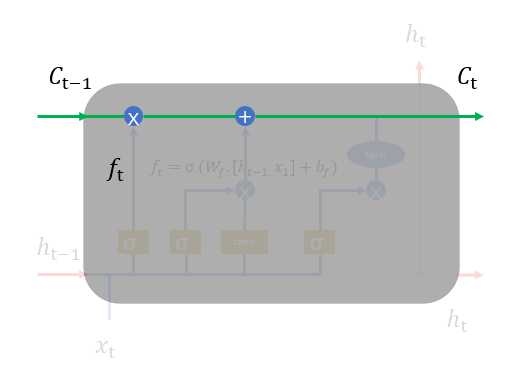
图1.6
但是,不是每一步的信息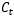 都是完全使用前一步的
都是完全使用前一步的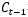 ,而是在
,而是在 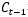 的基础之上“遗忘”掉一些内容,或“记住”一些内容。
的基础之上“遗忘”掉一些内容,或“记住”一些内容。
1、 遗忘门,我们首先谈一谈遗忘门,每个单元都有一个“遗忘门”,用来控制遗忘掉 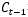 的那些部分,其结构如图1.7所示。其中σ是sigmoid激活函数,它的输出在0~1之间,遗忘门输出的
的那些部分,其结构如图1.7所示。其中σ是sigmoid激活函数,它的输出在0~1之间,遗忘门输出的 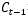 相同形状的矩阵,该矩阵将会和
相同形状的矩阵,该矩阵将会和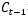 逐点相乘,决定遗忘掉那部分内容。经过激活函数的输出,f取值接近0的维度上的信息就会被“忘记”,而f取值接近1的维度上的信息就会被保留。
逐点相乘,决定遗忘掉那部分内容。经过激活函数的输出,f取值接近0的维度上的信息就会被“忘记”,而f取值接近1的维度上的信息就会被保留。
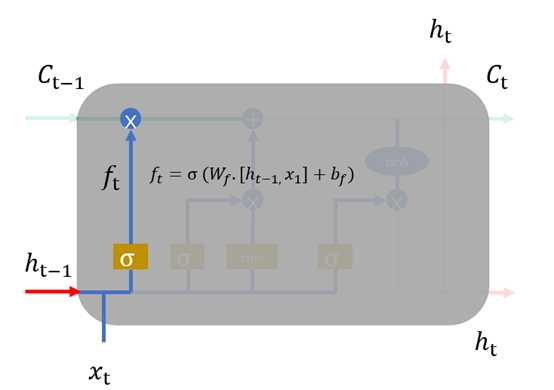
图1.7
2、 输入层,如图1.8,在循环神经网络“忘记”了部分之前的状态后,它还需要从当前的输入补充最新的记忆,这个过程就是“输入门”完成的。输入门的输入同样是两项,分别是:。它的输出项,一项是 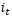 ,
,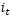 同样经过Sigmoid函数运算得到,其值都是在0~1之间,还有一项
同样经过Sigmoid函数运算得到,其值都是在0~1之间,还有一项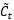 。最终要“记住”的内容是与
。最终要“记住”的内容是与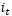 点相乘,如图1.9。
点相乘,如图1.9。
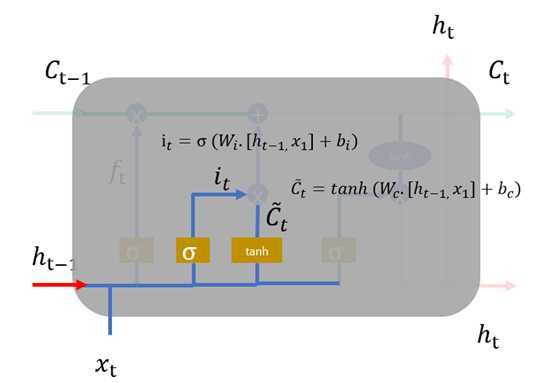
图1.8
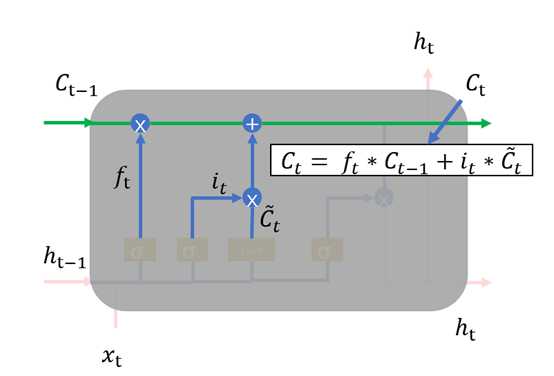
图1.9
3、 输出门,输出门用于计算另一个隐状态的值,真正的输出(如类别)需要通过做进一步运算得到。输出门的结构如图1.20所示,同样根据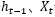 计算,
计算,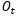 中每一个数值在0~1之间,
中每一个数值在0~1之间,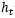 通过
通过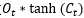 得到。
得到。
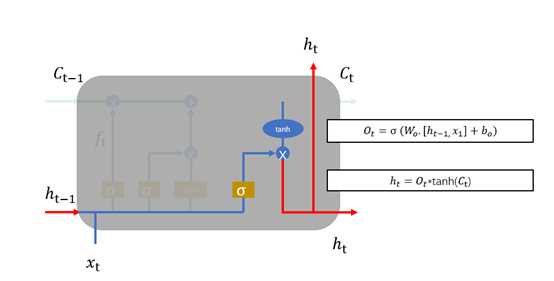
图1.20
最终总结:LSTM中每一步的输入是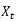 ,隐状态是
,隐状态是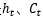 ,最终的输出必须要经过
,最终的输出必须要经过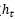 进一步变换得到。
进一步变换得到。
标签:矩形 决定 形状 运算 间隔 包含 利用 mic 字幕
原文地址:https://www.cnblogs.com/shenpings1314/p/10428519.html