标签:ons 聚集 ... const begin his 详细 搜索 interval
最近分析bbr的时候,收集了线上的一些报文,其中有一个疑问一直在我脑海里面,如下:

本身处于delay_ack状态的客户端,大概40ms回复一个聚集ack,当收到一个490字节的小包之后,立刻回复了ack。且不止出现,是有规律的出现:
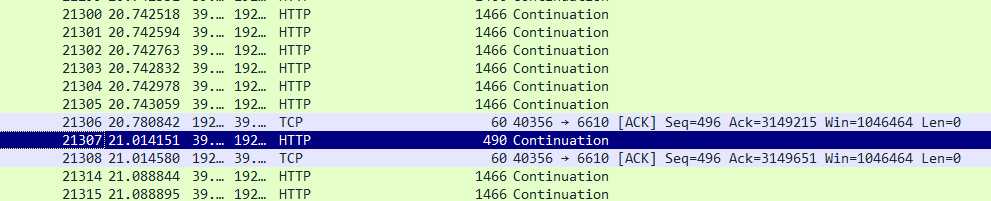
我是如何确定这个ack一定是打破了delay_ack的呢,除了在时间上和发包的时间相隔很短,我还特意确认了一下,之后报文的ack是否立刻回复的,结果确定
都是立刻回复的,也就是进入了quick_ack的模式,回复快速ack的数量也刚好是16,也就是符合代码:
icsk->icsk_ack.quick = min(quickacks, TCP_MAX_QUICKACKS);
根据接收窗口和mss,以及
/* * Check if sending an ack is needed. */ static void __tcp_ack_snd_check(struct sock *sk, int ofo_possible) { struct tcp_sock *tp = tcp_sk(sk); /* More than one full frame received... */ if (((tp->rcv_nxt - tp->rcv_wup) > inet_csk(sk)->icsk_ack.rcv_mss && /* ... and right edge of window advances far enough. * (tcp_recvmsg() will send ACK otherwise). Or... */ __tcp_select_window(sk) >= tp->rcv_wnd) || /* We ACK each frame or... */ tcp_in_quickack_mode(sk) || /* We have out of order data. */ (ofo_possible && !RB_EMPTY_ROOT(&tp->out_of_order_queue))) { /* Then ack it now */ tcp_send_ack(sk); } else { /* Else, send delayed ack. */ tcp_send_delayed_ack(sk); } }
然后我搜索代码,看什么时候调用 tcp_enter_quickack_mode,发现没有收获,这个包不满足条件。
这个包的神奇之处在哪?走查了delay_ack打破的条件,没法理解这个代码逻辑,关于delay_ack的出现场景,在另一篇博客中有描述《https://www.cnblogs.com/10087622blog/p/10315410.html》
我点击这个报文详细分析:
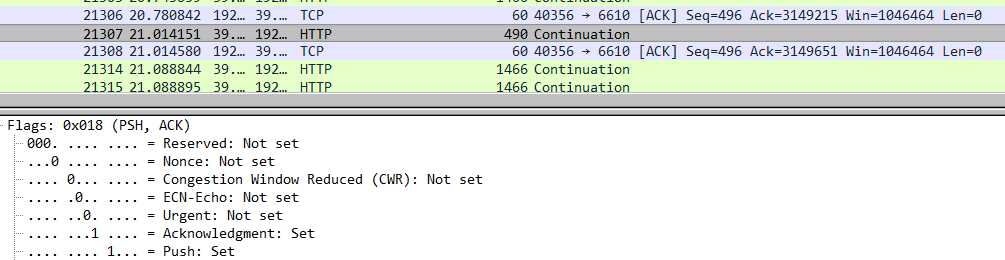
发现它和其他报文的区别是,它带了push标志,带了走查了代码,也没看出来,为啥push标志的报文会在delay_ack的情况下,能立刻发送ack。
最后,再回到报文,看到一点, 那就是这个小包与上一个ack之间的间隔为230ms左右,直觉感觉这个时间偏大,然后走查收包的代码:
/* There is something which you must keep in mind when you analyze the * behavior of the tp->ato delayed ack timeout interval. When a * connection starts up, we want to ack as quickly as possible. The * problem is that "good" TCP‘s do slow start at the beginning of data * transmission. The means that until we send the first few ACK‘s the * sender will sit on his end and only queue most of his data, because * he can only send snd_cwnd unacked packets at any given time. For * each ACK we send, he increments snd_cwnd and transmits more of his * queue. -DaveM */ static void tcp_event_data_recv(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); u32 now; inet_csk_schedule_ack(sk); tcp_measure_rcv_mss(sk, skb); tcp_rcv_rtt_measure(tp); now = tcp_time_stamp; if (!icsk->icsk_ack.ato) { /* The _first_ data packet received, initialize * delayed ACK engine. */ tcp_incr_quickack(sk); icsk->icsk_ack.ato = TCP_ATO_MIN; } else { int m = now - icsk->icsk_ack.lrcvtime; if (m <= TCP_ATO_MIN / 2) { /* The fastest case is the first. */ icsk->icsk_ack.ato = (icsk->icsk_ack.ato >> 1) + TCP_ATO_MIN / 2; } else if (m < icsk->icsk_ack.ato) { icsk->icsk_ack.ato = (icsk->icsk_ack.ato >> 1) + m; if (icsk->icsk_ack.ato > icsk->icsk_rto) icsk->icsk_ack.ato = icsk->icsk_rto; } else if (m > icsk->icsk_rto) {---------------------------进入这个流程 /* Too long gap. Apparently sender failed to * restart window, so that we send ACKs quickly. */ tcp_incr_quickack(sk);----------------------------------这个修改了quickack的发包数量 sk_mem_reclaim(sk); } } icsk->icsk_ack.lrcvtime = now; tcp_ecn_check_ce(tp, skb); if (skb->len >= 128) tcp_grow_window(sk, skb); }
正是因为发包的间隔大于了 icsk->icsk_rto,所以接收端觉得很长时间没有收到包了,那么尽快给对方回复ack。icsk->icsk_ack.quick 已经大于0了。
static bool tcp_in_quickack_mode(struct sock *sk) { const struct inet_connection_sock *icsk = inet_csk(sk); const struct dst_entry *dst = __sk_dst_get(sk); return (dst && dst_metric(dst, RTAX_QUICKACK)) || (icsk->icsk_ack.quick && !icsk->icsk_ack.pingpong); }
那么还需要一个条件就是,icsk->icsk_ack.pingpong 要为0,才行,否则单独增加 icsk->icsk_ack.quick 的值并不能保证立刻回复ack。
而我们目前这个流,明显是一个单向的发包流,并不是pingpong模式,所以这个值肯定为0,那么我们就满足了 tcp_in_quickack_mode 的条件,
打破了本端的delay_ack模式。
总结:
我只是搜索了tcp_enter_quickack_mode 的代码流程,没有注意到 tcp_incr_quickack 的调用,导致这个问题查了小半天。业务不精。
如果连续两个小包,加起来超过mss了,则可能会触发对端在delay_ack模式下立即回复ack,但是如果一个小包就打破了对端的delay_ack,则需要关注这个
小包的发包间隔了。
那么问题来了,为什么会相隔这么长时间发送小包?后面会继续探讨。
标签:ons 聚集 ... const begin his 详细 搜索 interval
原文地址:https://www.cnblogs.com/10087622blog/p/10423118.html