标签:idt 预测 style 效率 除了 mmm png auto 均值
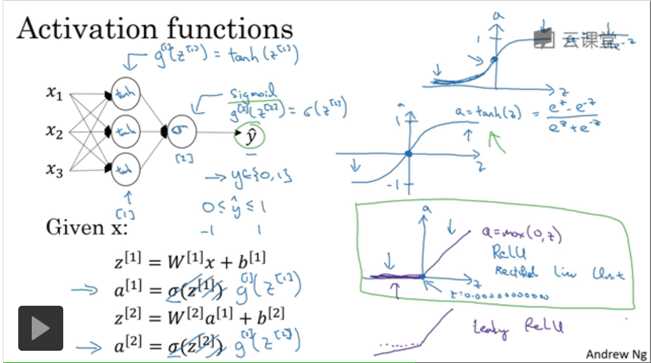
1.tanh函数比sigmoid效果更好,它的区间是[-1,1],所以均值为0,有类似于让数据中心化的效果。
//此时Ng说,tanh函数几乎在所有场合都更优越。
2.但是如果yhat是二分类,是{0,1},此时使用在[0,1]区间的激活函数更好,所以对于二分类在隐层中使用tanh,输出用sigmoid。
3.不同层的激活函数可以不同。
4.对于tanh和siogmoid最大的问题就是当z较大时,梯度变化非常小,斜率接近于0,所以就出现了ReLU线性修正单元a=max(0,z),
5.对于ReLU,在x=0时这一点的导数是0.000..非常小,这个函数是不可微的, 通常使用的比较多。
6.ReLU和带泄露的ReLU来说,因为对于z,其斜率离0差很远,能使NN训练更快,没有斜率接近0时学习效率减慢的现象。

常用激活函数:
1.对于sigmoid,除了二分类时就不要用。很少用。
2.tanh函数使用多,效果好。
3.ReLU使用多效果好,
4.带泄露的ReLU,通常a=max(0.01z,z),关于0.01的选取emmm
如果使用恒等的激活函数,也就是没有激活函数,两个线性函数结合依旧是线性函数,无法进行更深层次的计算,得不到更有趣的函数。

举了预测房价的例子:可以在隐藏层使用ReLU,或LeakyR,唯一可以使用线性激活函数的地方通常是输出层。
//计算过程:如果是恒等,那么实际上最后也是线性关系。
介绍了sigmoid\tanh\ReLU的导数,比较简单的。
4.
标签:idt 预测 style 效率 除了 mmm png auto 均值
原文地址:https://www.cnblogs.com/BlueBlueSea/p/10430245.html