标签:令行 pre project 文件 图片 命令行编译 out 不同 dir
网上的 MapReduce WordCount 教程对于如何编译 WordCount.java 几乎是一笔带过… 而有写到的,大多又是 0.20 等旧版本版本的做法,即 javac -classpath /usr/local/hadoop/hadoop-1.0.1/hadoop-core-1.0.1.jar WordCount.java,但较新的 2.X 版本中,已经没有 hadoop-core*.jar 这个文件,因此编辑和打包自己的MapReduce程序与旧版本有所不同。
本文以 Hadoop 2.6.0 单机模式环境下的 WordCount 实例来介绍 2.x 版本中如何编辑自己的 MapReduce 程序。
Hadoop 2.x 版本中 jar 不再集中在一个 hadoop-core*.jar 中,而是分成多个 jar,如使用 Hadoop 2.6.0 运行 WordCount 实例至少需要如下三个 jar:
实际上,通过命令 hadoop classpath 我们可以得到运行 Hadoop 程序所需的全部 classpath 信息。
我们将 Hadoop 的 classhpath 信息添加到 CLASSPATH 变量中,在 ~/.bashrc 中增加如下几行:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
别忘了执行 source ~/.bashrc 使变量生效,接着就可以通过 javac 命令编译 WordCount.java 了(使用的是 Hadoop 源码中的 WordCount.java,源码在文本最后面):
编译时会有警告,可以忽略。编译后可以看到生成了几个 .class 文件。
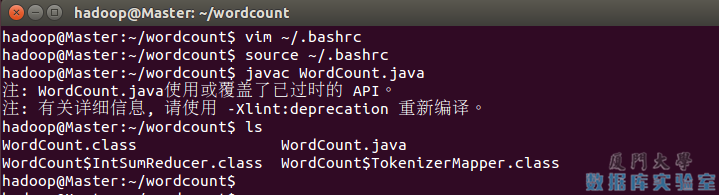 使用Javac编译自己的MapReduce程序
使用Javac编译自己的MapReduce程序
接着把 .class 文件打包成 jar,才能在 Hadoop 中运行:
打包完成后,运行试试,创建几个输入文件:
 创建WordCount的输入
创建WordCount的输入
如果读者Hadoop的环境是单机模式,请跳过此步骤。如果读者的Hadoop环境已经配置成伪分布式,那么读者还需要进行执行下列操作命令:
开始运行。直接运行/usr/local/hadoop/bin/hadoop jar WordCount.jar WordCount input output,可能会出现找不到类的错误: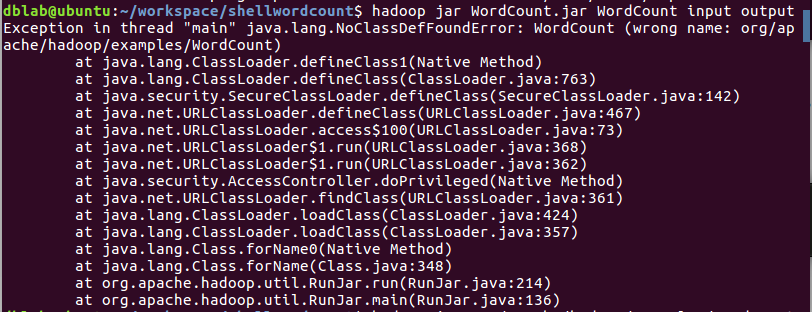
这是因为我们在代码中设置了package包名,这里也要写全,正确的命令如下。
正确运行后的结果如下: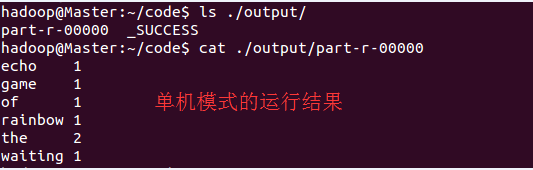
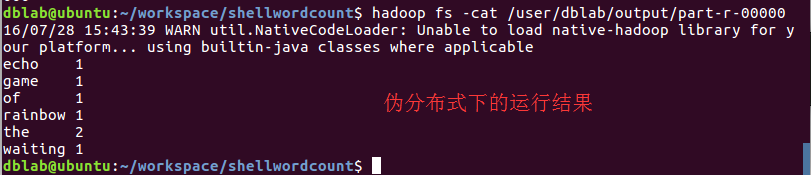
查看结果
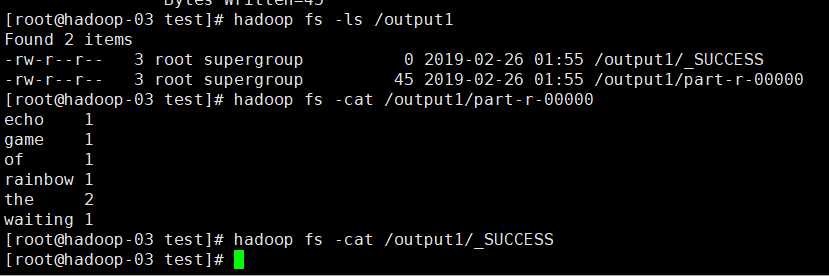
使用命令行编译打包运行自己的MapReduce程序 Hadoop2.6.0
标签:令行 pre project 文件 图片 命令行编译 out 不同 dir
原文地址:https://www.cnblogs.com/lfxiao/p/10432377.html