标签:默认值 key star top www. text work basis manage
1 spark伪分布搭建
jdk版本
java version "1.8.0_144" Java(TM) SE Runtime Environment (build 1.8.0_144-b01) Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
hadoop 版本
Hadoop 2.6.5 Subversion https://github.com/apache/hadoop.git -r e8c9fe0b4c252caf2ebf1464220599650f119997 Compiled by sjlee on 2016-10-02T23:43Z Compiled with protoc 2.5.0 From source with checksum f05c9fa095a395faa9db9f7ba5d754 This command was run using /utxt/hadoop-2.6.5/share/hadoop/common/hadoop-common-2.6.5.jar
scala 版本
Scala code runner version 2.10.5 -- Copyright 2002-2013, LAMP/EPFL
SPARK 版本
spark-2.4.0-bin-hadoop2.6
2 环境变量
hadoop setting export HADOOP_HOME=/utxt/hadoop-2.6.5 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH #SPARK setting export SPARK_HOME=/utxt/spark-2.4.0-bin-hadoop2.6 export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH #SCALA setting export SCALA_HOME=/utxt/scala-2.10.5 export PATH=$SCALA_HOME/bin:$PATH #java settings #export PATH export JAVA_HOME=/u01/app/software/jdk1.8.0_144 export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
3 SPARK 配置
spark-env.sh 添加如下几行 export SCALA_HOME=/utxt/scala-2.10.5 export SPARK_MASTER_IP=gc64 export SPARK_WORKER_MEMORY=1500m export JAVA_HOME=/u01/app/software/jdk1.8.0_144
slaves 添加一行
gc64
4 启动SPARK
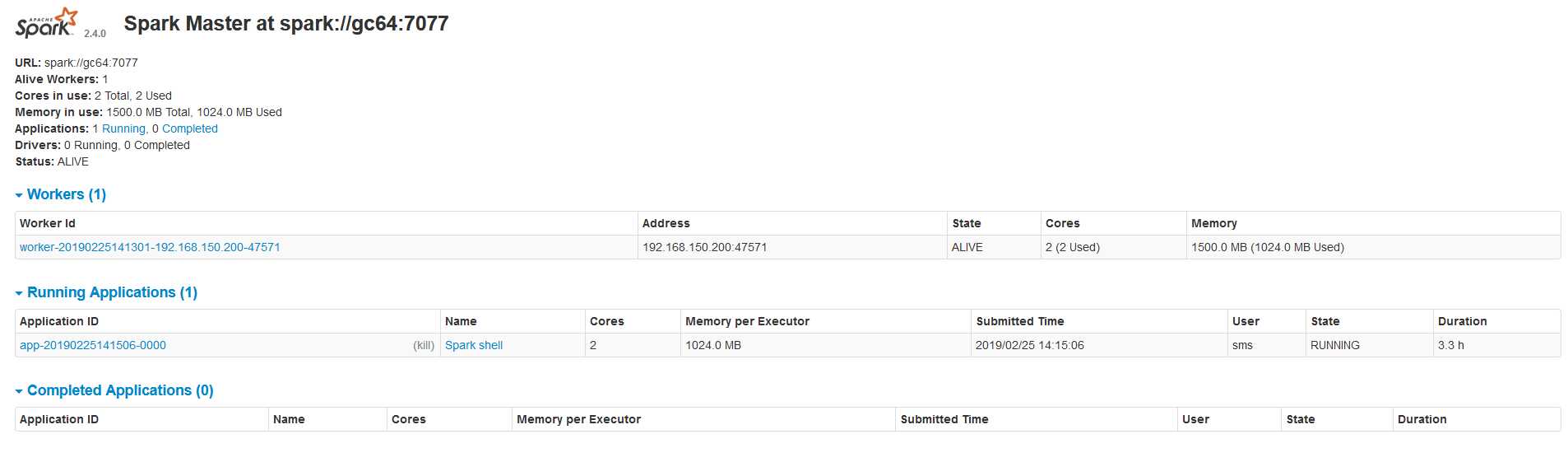
start-master.sh
在浏览器输入
http://gc64:8080/
启动worker
start-slaves.sh spark://gc64:7077
启动spark-shell
spark-shell --master spark://gc64:7077
5 运行例子测试
spark_shell(先启动hadoop) val file=sc.textFile("hdfs://gc64:9000/user/sms/test/test.txt") val rdd = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_) rdd.collect() rdd.foreach(println)
jar包测试
spark-submit --class JavaWordCount --executor-memory 1G --total-executor-cores 2 /utxt/test/spark-0.0.1.jar hdfs://gc64:9000/user/sms/test/test.txt
java代码
/* * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreements. See the NOTICE file distributed with * this work for additional information regarding copyright ownership. * The ASF licenses this file to You under the Apache License, Version 2.0 * (the "License"); you may not use this file except in compliance with * the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ import scala.Tuple2; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.sql.SparkSession; import java.util.Arrays; import java.util.List; import java.util.regex.Pattern; public final class JavaWordCount { private static final Pattern SPACE = Pattern.compile(" "); public static void main(String[] args) throws Exception { if (args.length < 1) { System.err.println("Usage: JavaWordCount <file>"); System.exit(1); } SparkSession spark = SparkSession .builder() .appName("JavaWordCount") .getOrCreate(); JavaRDD<String> lines = spark.read().textFile(args[0]).javaRDD(); JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator()); JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1)); JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2); List<Tuple2<String, Integer>> output = counts.collect(); for (Tuple2<?,?> tuple : output) { System.out.println(tuple._1() + ": " + tuple._2()); } spark.stop(); } }
其它例子请参考 spark-2.4.0-bin-hadoop2.6/examples/src/main

6 问题汇集
Failed to initialize mapreduce.shuffle yarn.nodemanager.aux-services项的默认值是“mapreduce.shuffle” 解决方案 将yarn.nodemanager.aux-services项的值改为“mapreduce_shuffle”。
7 参考资料
[1] 搭建Spark的单机版集群 https://www.cnblogs.com/ivictor/p/5135792.html
[2] http://spark.apache.org/
标签:默认值 key star top www. text work basis manage
原文地址:https://www.cnblogs.com/hdu-2010/p/10432165.html