标签:顺序 span 文档 不能 简化 数理统计 知乎 信息 训练
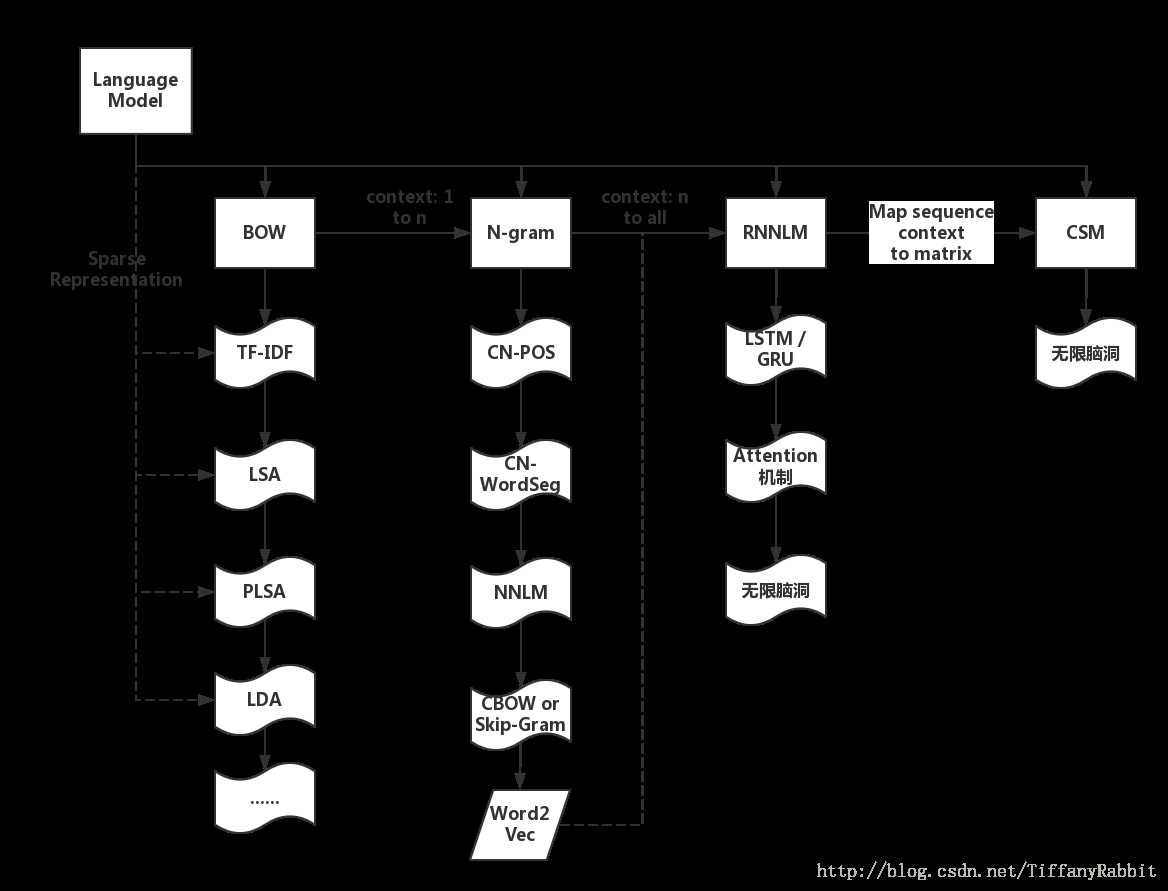
词袋模型是一种在NLP和IR中的简化的表示形式。在该模型中,文本被表示为成袋的单词,不考虑其语法甚至是单词顺序。词袋模型通常被用在文档分类的方法中,在这些方法中,每个单词的出现频率被用作训练分类器的特征。
在实际中,词袋模型主要用作产生特征的工具。这种列表表示不能保留原文本的顺序,该技术在Email过滤方面有着成功的应用。
https://en.wikipedia.org/wiki/Bag-of-words_model
在信息检索领域,TF-IDF是一种用来反映一个单词对文档的重要性的数理统计方法。这是最受欢迎的项权重方案之一,83%的基于文本的推荐系统使用了该方法。一项单词在文档中出现的权重只与项出现的频率成正比。对于常出现的单词,要减少出现的频率,对于不常出现的单词要增加权重。Karen想出来一个统计学解释叫做IDF,并成为项权重的基石:词语的独特性可以作为文档数量的反转函数来衡量。
继续阅读理解:
https://zhuanlan.zhihu.com/p/31197209
https://en.wikipedia.org/wiki/Tf–idf
标签:顺序 span 文档 不能 简化 数理统计 知乎 信息 训练
原文地址:https://www.cnblogs.com/billdingdj/p/10432976.html