标签:网络模型 function 特征 ima 维数 center width 连接 集中
Tensorflow+CNN下的mnist数据集手写数字识别
MNIST数据集包含55000个训练样本,10000个测试样本,还有5000个交叉验证数据样本。
输入:加载的每个手写数字图像是28 x 28像素大小的灰度图像。为了简化起见,将28x28的像素点展开为一维数据(shape=784)。
输出:每张测试图片的预测结果y为一个10维数组,数组中值的取值范围为[0,1],使用tf.argmax(y,1),取出数组中最大值的下标,再用独热表示以及模型输出转换成数字标签。
2.定义算法公式,也就是前向计算的计算图
处理多分类任务,通常采用Softmax模型。y = Softmax(Wx + b),其中W为权值矩阵,b为偏置向量,x为输入特征矩阵。
使用Softmax函数是将各个类别的打分转换成合理的概率值。其中权值矩阵W是将784维的输入转换成一个10维的输出。
本实验中使用的的CNN模型,是将输入的784维的输入向量,还原为28x28的图片格式,再经过两次卷积层、一次全连接层处理后,得到的1024维的向量转换成10维,即对应10个类别,调用Softmax函数将其转换成10个类别的概率。
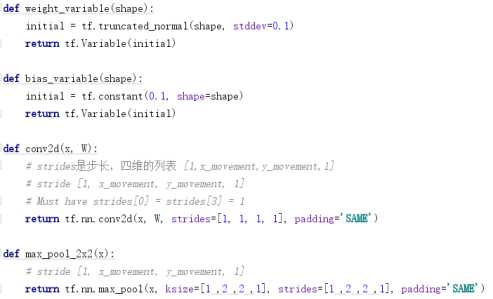
Weight_variable()和bias_ariable()为初始化权重和偏置的初始化函数,给权重制造一些随机的噪声来打破对称,而给偏置增加一些小的正值(0.1)来避免死亡节点
Cov2d()和max_pool_2x2()为定义卷积层与池化层,使用的为tensorflow自带的二维卷积函数与池化函数。
第一层的卷积层:

卷积:卷积特征提取采用5x5,输入为1维,输出为32维。
W_conv1 = weight_variable([5 ,5, 1 ,32]) # patch 5x5, in size 1, out size 32
conv2d(x_image, W_conv1) + b_conv1
激活:卷积之后使用ReLU作为激活函数。原因为增加非线性激活函数,增强拟合复杂函数的能力。
tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # output size 28x28x32
池化:池化窗口的大小设置为了2x2, 窗口在每一个维度上滑动的步长也设置为了2x2,所以图像由28x28x32-->14x14x32。
max_pool_2x2(h_conv1)
第二层卷积,与第一层卷积类似,输入由图像变成第一次卷积后结果,输出图像由14x14x64-->7x7x64

两次卷积之后,是全连接层,输出为1024维的向量

全连接层中加入了Dropout防止神经网络过拟合,选择的Dropout概率keep_prob为0.5,但训练的时候每一个连接都有50%的概率被去除,测试的时候keep_prob为1,即保留所有连接。
再设置一层全连接,将上一步的到的h_fcl_drop转换成10个类别的打分,在使用Softmax函数将其转化成10个类别的概率。
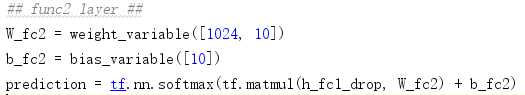
3.定义损失函数(loss function),选定优化器,并指定优化器优化损失函数
对于多分类问题,通常采用交叉熵(cross-entropy)作为损失函数。交叉熵的定义如下,其中y是预测的概率分布,y’是真实的概率分布:
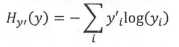
选择交叉熵作为损失函数,但优化器选择自适应的优化器Adagrad,并把学习率设为0.0001。(Softmax回归函数实现mnist手写数字识别使用的为GradientDescentOptimizer梯度下降算法优化器)

4.对数据进行迭代训练
模型迭代训练1000次,每次从训练集中随机选出100个样本训练一次。每隔50次训练,打印模型的预测准确率。

5.在测试集上进行准确率评估。
每一次测试结果准确度的函数定义:

6.Mnist数据集在Softmax回归函数、深度神经网络DNN、卷积神经网络模型CNN下运行结果。
|
模型名称 |
Softmax |
DNN |
CNN |
|
训练次数 |
1000 |
1000 |
1000 |
|
每次样本数 |
100 |
100 |
100 |
|
优化器 |
GradientDescentOptimizer |
AdagradOptimizer |
AdamOptimizer |
|
学习率 |
0.5 |
0.3 |
0.0001 |
|
准确度 |
0.9128 |
0.9737 |
0.9681 |
1) Softmax回归函数预测准确度为92%左右,训练中会出现过拟合问题,准确度骤降至很低。
2) CNN实验中使用的卷积神经网络为官方demo,样本训练次数加大到20000次时,准确度可以达到99.37%。实验中原程序中卷积层的特征提取窗口大小、维度,池化层中的池化窗口大小、步长,实验中的优化器AdagradOptimizer学习率,都可以作为后续学习中的调参对象。
3) DNN实验中定义了addConnect函数, 4个参数中第1个参数是输入层矩阵Inputs;第2个参数是连接上一层神经元个数in_size; 第3个参数是连接下一层神经元个数;第4个参数是激活函数。
实验中添加第1个连接层,输入参数为784维的图片向量、神经元个数为784、连接下一层的神经元个数300,激活函数ReLU,并将其输出结果赋值给变量connect_1;添加第2个连接层,输入参数为connect_1、神经元个数为300、连接下一层的神经元个数10,激活函数ReLU,并将其输出结果赋值给变量predict_y,即标签预测值。如下图所示:

4) 优化器optimizer:实验中使用了GradientDescentOptimizer、AdamOptimizer,对比可得,AdagradOptimizer在此问题的收敛效果较好。
运行结果截图:
从左到右依次为:Softmax回归函数、DNN、CNN(其中CNN模型在工作站
标签:网络模型 function 特征 ima 维数 center width 连接 集中
原文地址:https://www.cnblogs.com/xiaomai0379/p/10462250.html