标签:demo prot tput 分布 .text over color 参数 err
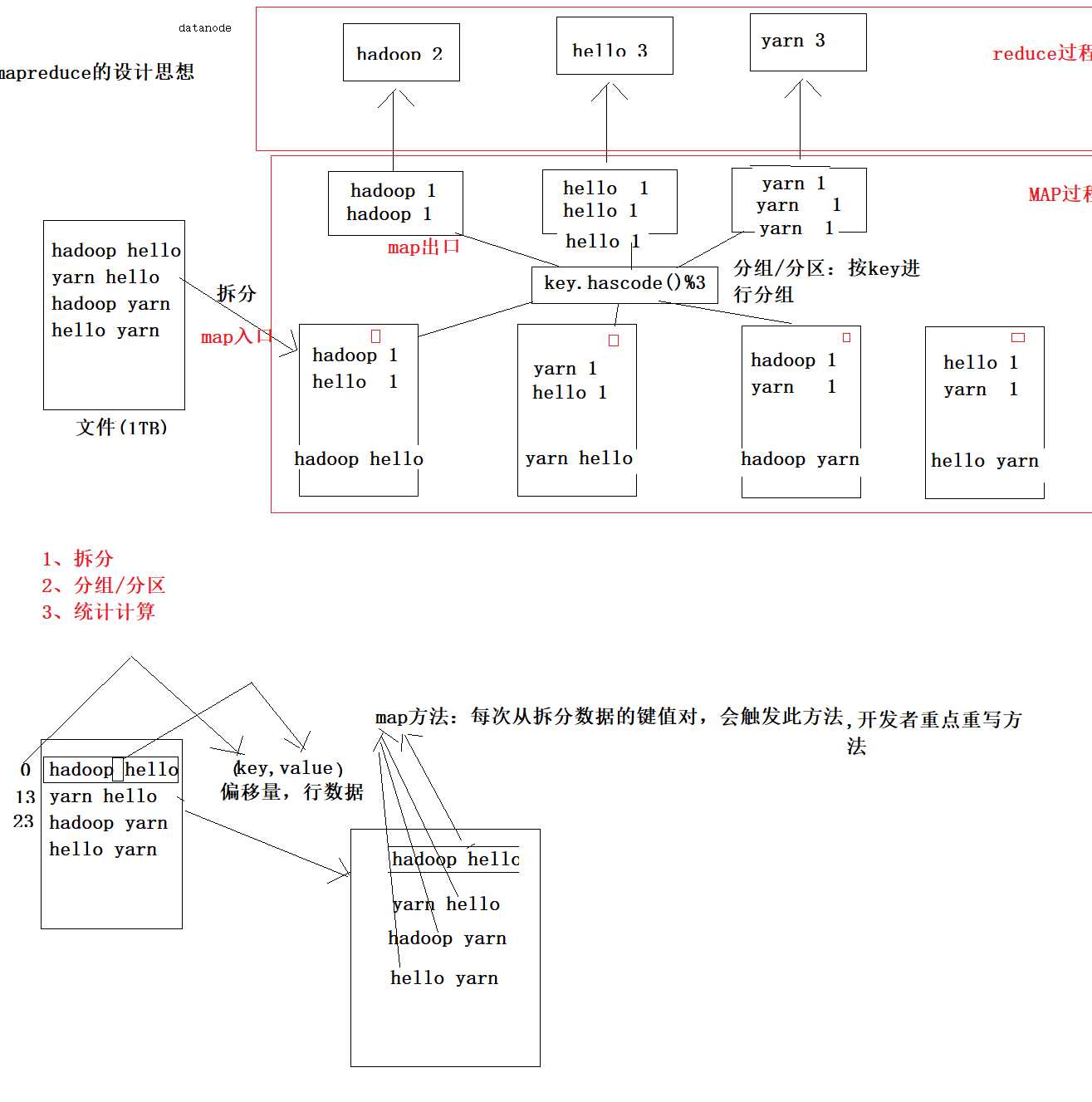
概念:
它是一个分布式并行计算的应用框架
它提供相应简单的api模型,我们只需按照这些模型规则编写程序,
即可实现"分布式并行计算"的功能。
package com.gec.demo; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /* * 作用:体现mapreduce的map阶段的实现 * KEYIN:输入参数key的数据类型 * VALUEIN:输入参数value的数据类型 * KEYOUT,输出key的数据类型 * VALUEOUT:输出value的数据类型 * * 输入: * map(key,value)=偏移量,行内容 * * 输出: * map(key,value)=单词,1 * * 数据类型: * java数据类型: * int-------------->IntWritable * long------------->LongWritable * String----------->Text * 它都实现序列化处理 * * */ public class WcMapTask extends Mapper<LongWritable, Text,Text, IntWritable> { /* *根据拆分输入数据的键值对,调用此方法,有多少个键,就触发多少次map方法 * 参数一:输入数据的键值:行的偏移量 * 参数二:输入数据的键对应的value值:偏移量对应行内容 * */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line=value.toString(); String words[]=line.split(" "); for (String word : words) { context.write(new Text(word),new IntWritable(1)); } } }
以下为reduce方法
package com.gec.demo; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /* * 此类:处理reducer阶段 * 汇总单词次数 * KEYIN:输入数据key的数据类型 * VALUEIN:输入数据value的数据类型 * KEYOUT:输出数据key的数据类型 * VALUEOUT:输出数据value的数据类型 * * * */ public class WcReduceTask extends Reducer<Text, IntWritable,Text,IntWritable> { /* * 第一个参数:单词数据 * 第二个参数:集合数据类型汇总:单词的次数 * * */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count=0; for (IntWritable value : values) { count+=value.get(); } context.write(key,new IntWritable(count)); } }
最后是主类
package com.gec.demo; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /* * 指明运行map task的类 * 指明运行reducer task类 * 指明输入文件io流类型 * 指明输出文件路径 * * */ public class WcMrJob { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration=new Configuration(); Job job=Job.getInstance(configuration); //设置Driver类 job.setJarByClass(WcMrJob.class); //设置运行那个map task job.setMapperClass(WcMapTask.class); //设置运行那个reducer task job.setReducerClass(WcReduceTask.class); //设置map task的输出key的数据类型 job.setMapOutputKeyClass(Text.class); //设置map task的输出value的数据类型 job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //指定要处理的数据所在的位置 FileInputFormat.setInputPaths(job, "hdfs://hadoop-001:9000/wordcount/input/big.txt"); //指定处理完成之后的结果所保存的位置 FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-001:9000/wordcount/output/")); //向yarn集群提交这个job boolean res = job.waitForCompletion(true); System.exit(res?0:1); } }
双击package,可以生成mapreducewordcount-1.0-SNAPSHOT.jar这个jar包,将该jar包发送到hadoop-oo1
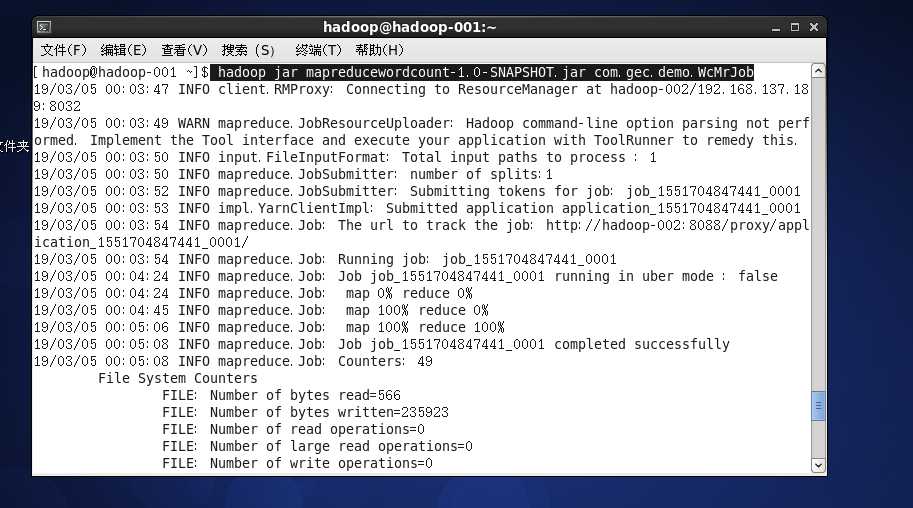
指令如下: hadoop jar mapreducewordcount-1.0-SNAPSHOT.jar com.gec.demo.WcMrJob
即可运行word count程序
在浏览器上查看yarn
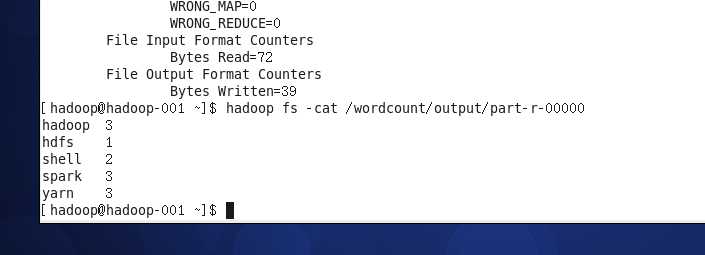
查看结果指令如下:
hadoop fs -cat /wordcount/output/part-r-00000
标签:demo prot tput 分布 .text over color 参数 err
原文地址:https://www.cnblogs.com/Transkai/p/10474308.html