标签:.com 一个 前言 聚类 检测方法 蓝色 一点 选择 http
论文链接:https://arxiv.org/abs/1612.04402
这篇论文收录在CVPR2017,距今已经两年多了,今天上英语课发现带了这篇论文就看了起来,觉得还挺有意思就仔细看了一下,网上翻译总结较少,推荐知乎大佬对这篇文章的总结(调侃)链接。
作者公开了他们的代码,是用matlab语言写的,看了一下实在不知道写了什么(自己太渣)。还好有另一位大佬用pytorch复现了一版,代码写得很整洁,复现得比较完整。撸了一遍代码,已经开始训练,最后看测试结果与原文相差多少。
tiny-face pytorch 实现:https://github.com/varunagrawal/tiny-faces-pytorch
作者没有给使用说明,但是代码就是最好的doc,一看就懂。
论文咋看非常高深,但整体实现却非常简单,给我的感觉这篇文章更像一个 tech report,然后在公开数据集上表现效果很好就中了。
但是文章对于小尺度图像检测问题的分析还是做得非常好的。看了后可以对小尺度目标检测问题有更好得认识。
好的论文,一图胜万言。

图 1
第一张图,没什么好说的,秀就完事。

图 2
第二张,介绍了几种解决多尺度的方式,左边糊的脸代表模板(其实就是prior box 或者 anchor box),右边是图像金子塔,经典的多尺度解决方法。本文采用的是(d)多个尺度的模板加图像金子塔,(d) 就是foveal descriptor展示,后面图细说。
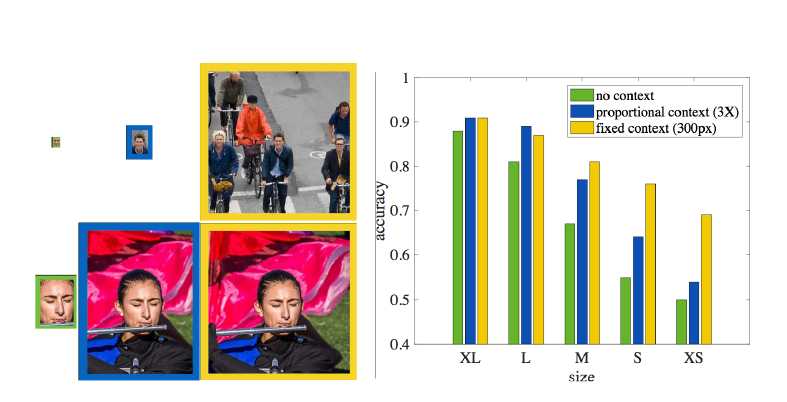
图 3
第三张,左边图像说明的是人要检测出小的脸需要额外的context信息,而大的脸不用,中间列是成比例方法(context框是跟人脸大小成比列的,这里3倍),第三列是固定的context框。最后一个是统计人对于不同情况的识别准确率。可以看到固定尺寸的context框对识别小目标更好。
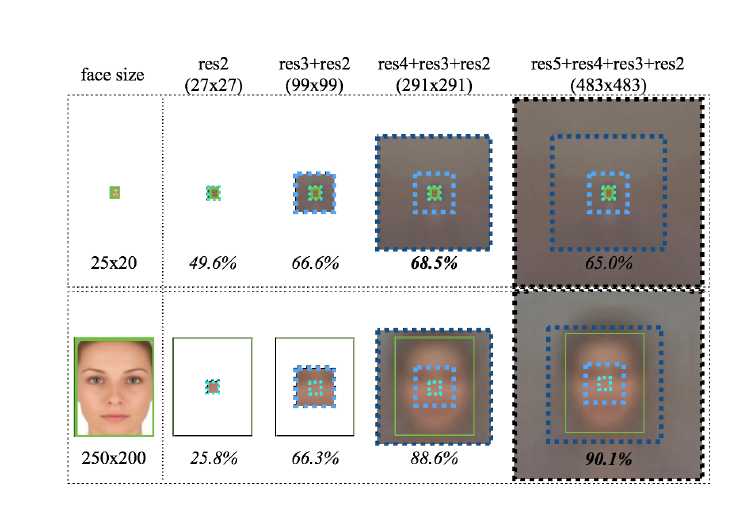
图 4
第四张,可以说明两个点,第一,特征融合,res2+res3+res4+res5, 浅层特征特征更多小目标和细节信息,融合后对检测小目标有益; 第二, 顺便把context也获得了,context其实就是大的感受野如这里的291*291, 服气。
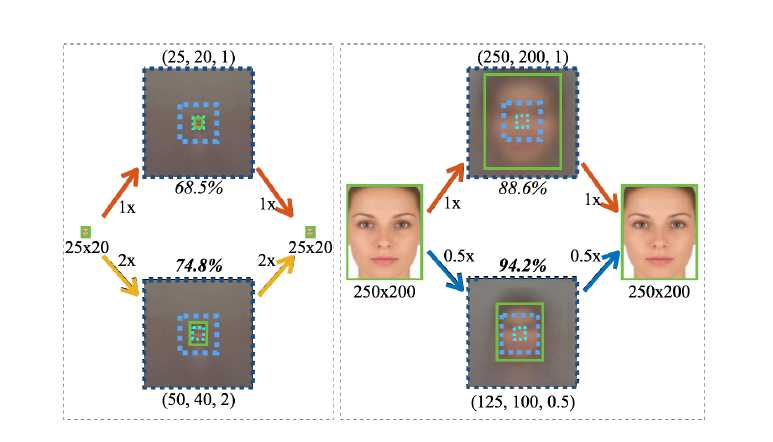
图 5
第五张,是两张图的尺度处理方法,可以看出小的目标,将原图放大两倍后用大模板检测率更高(74.8% 比68.5%),而对于大目标缩小后用小模板检测的目标检测率更高(94.2%比88.6%)。下面这张图统计了ImageNet上的表现情况。
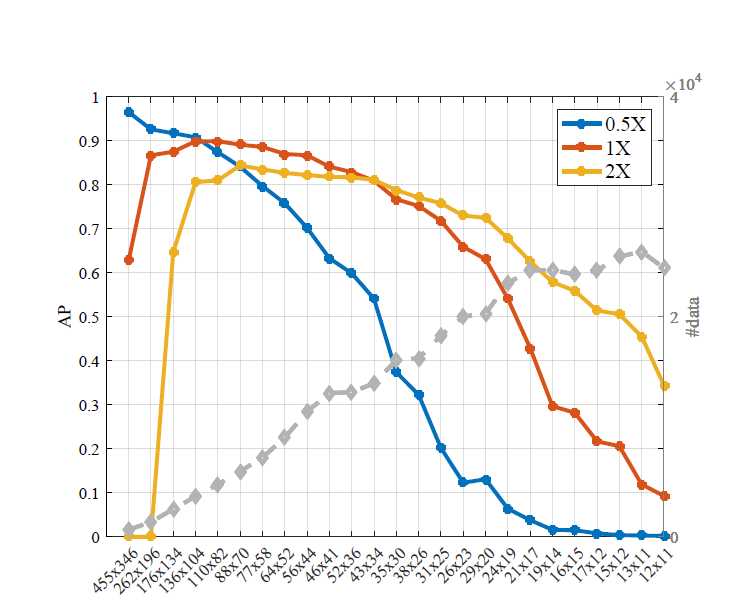
图 6.
第六张,横坐标是经过聚类得到的25个尺度,纵坐标是用这个些尺度做为模板尺度在不同的输入scale下进行预测的精度。
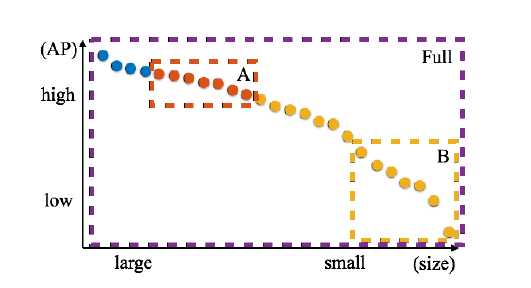
图 7 模板去冗余方法
由于图6 中的模板存在冗余,作者给出了一种去除冗余的方法,去除后效果还提升了。图7 所示,横纵坐标的定义依然如图6, 即做出了图6的外包曲线(每个阶段AP最大的段),蓝色代表0.5X、橙色代表1X、黄色代表2X,分别位于large、medium、small 尺度区。去冗余的方法是:取出A段的模板和B段的模板,图像使用特征金子塔(0.5,1,2),则可以大概覆盖整个尺度范围。但是这一点在pytorch实现中似乎没有做。
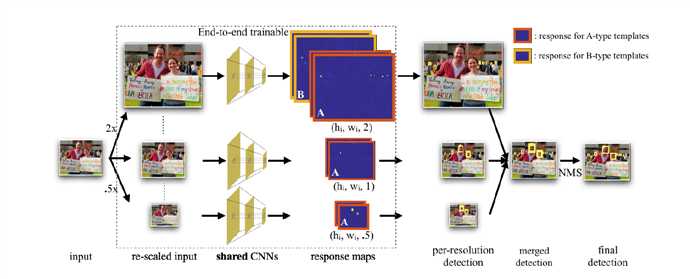 图 8
图 8
这张图真的不是很好,会有点误导人。最开始我以为是同时输入一个图像金子塔进行预测和训练,后来看了源码和论文的附录后才知道,其实使用多尺度的方式训练,分别以三分之一的概率进行三个尺度的变化,送进网络进行训练,预测的时候可以选择使用多尺度(浪费性能)或者不适用多尺度(小目标检测肯定会差)。
整体的框架设计与yolov2和RPN(faster-rcn中的region proposal network)类似,是one-stage的检测方法,不同的是加入了一些scale specific的设计(anchor box的选择)和多尺度特征的融合,再辅以图像金子塔,最后对小目标检测效果显著。具体的实现细节都是常规的object detection 那一套。
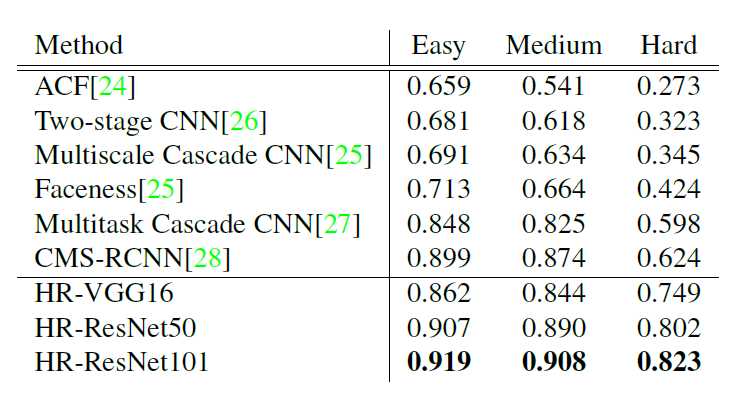
可以看到文章的主要贡献在hard部分也就是小目标检测。这也与文章所要解决的问题。
标签:.com 一个 前言 聚类 检测方法 蓝色 一点 选择 http
原文地址:https://www.cnblogs.com/walter-xh/p/10479913.html