标签:elb htm hold bin code describe scribe 特征 相关性
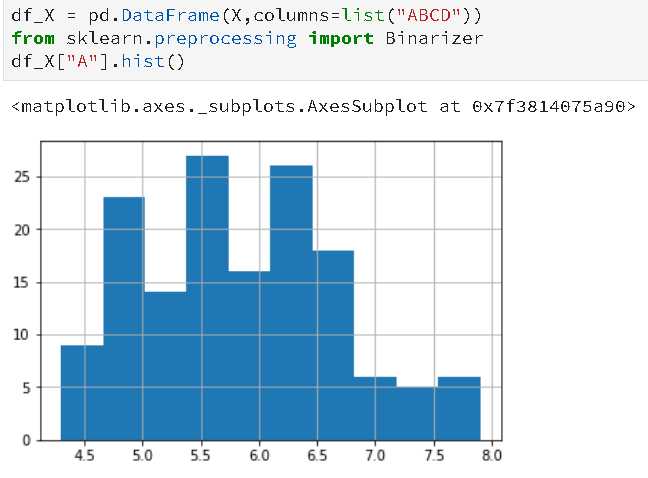
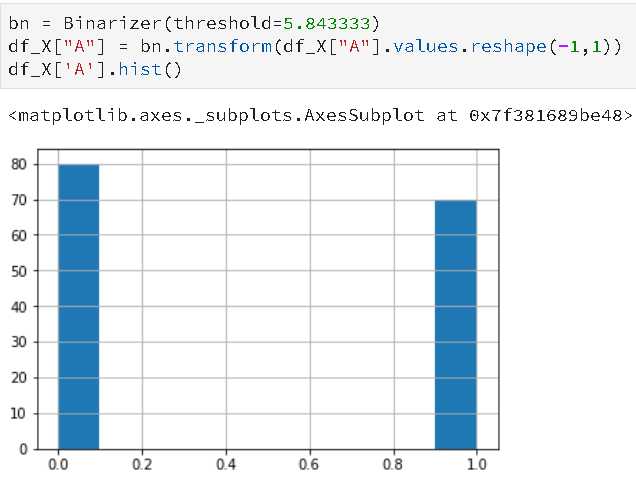
这个就是根据阈值将数值型转变为二进制型,阈值可以进行设定,另外只能对数值型数据进行处理,且传入的参数必须为2D数组,也就是不能是Series这种类型,shape为(m,n)而不是(n,)类型的数组,下面看下例子:
from sklearn.datasets import load_iris import pandas as pd X,y = load_iris(return_X_y=True) df_X = pd.DataFrame(X,columns=list("ABCD")) from sklearn.preprocessing import Binarizer df_X["A"].describe() bn = Binarizer(threshold=5.843333) df_X["A"] = bn.transform(df_X["A"].values.reshape(-1,1))
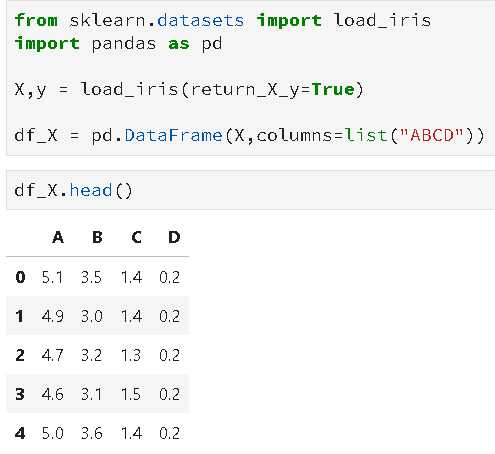
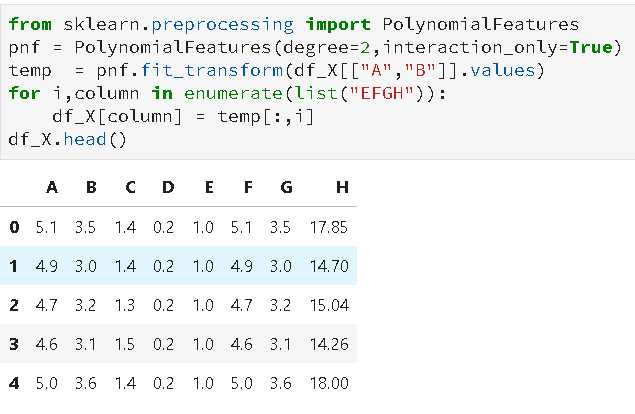
捕获特征之间的相关性, 使用sklearn.preprocessing.PolynomialFeatures来进行特征的构造。
它是使用多项式的方法来进行的,如果有a,b两个特征,那么它的2次多项式为(1,a,b,a^2,ab, b^2),这个多项式的形式是使用poly的效果。
from sklearn.datasets import load_iris import pandas as pd X,y = load_iris(return_X_y=True) df_X = pd.DataFrame(X,columns=list("ABCD")) from sklearn.preprocessing import PolynomialFeatures pnf = PolynomialFeatures(degree=2,interaction_only=True) temp = pnf.fit_transform(df_X[["A","B"]].values) for i,column in enumerate(list("EFGH")): df_X[column] = temp[:,i]
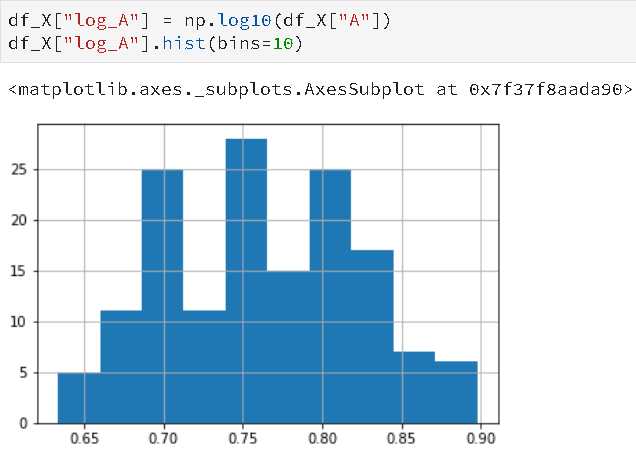
log变化:log变化倾向于拉高那些落在较低的幅度范围内自变量的取值,压缩那些落在较高的幅度范围内自变量的取值,log变化能够稳定数据的方差,使数据的分布接近于正太分布并使得数据与分布的均值无关。Box_Cox变换也有相似的效果,出现负数,使用常数进行偏移。
from sklearn.datasets import load_iris import pandas as pd import numpy as np X,y = load_iris(return_X_y=True) df_X = pd.DataFrame(X,columns=list("ABCD")) df_X["A"].hist(bins=10) df_X["log_A"] = np.log10(df_X["A"]) df_X["log_A"].hist(bins=10)
参考文献:
【1】连续数值变量的一些特征工程方法:二值化、多项式、数据倾斜处理
【2】使用sklearn进行数据预处理之Binarizer,LabelEncoder,LabelBinarizer,OneHotEncoder
连续数值变量的一些特征工程方法:二值化、多项式、数据倾斜处理
标签:elb htm hold bin code describe scribe 特征 相关性
原文地址:https://www.cnblogs.com/nxf-rabbit75/p/10485771.html