标签:blog http ar sp 文件 数据 2014 on 问题
王老师的现代信息索引讲的很精彩,但是三节联排的课程总让我的注意力没办法太集中。在这里记录一下知识,也但是回顾了。
支持布尔查询的索引办法,在给定一个查询的情况下,可能匹配到的结果非常的多,那么对匹配结果(文档)进行评分或者相关权重分析,就显得尤为重要。
一、 参数化索引和域索引
通常的文档都有额外的结构(title,author,content,etc.) ,这些也称为元数据。对于这些检索系统可以进行参数化索引,从而完成参数化搜索,类似
“查询由William Shakespeare 于 1601 年撰写、其中包含短语alas poor 的文档” , 通常用到专业领域索引,如百度学术。
例:考虑一个文档集,每篇都有三个域 :author,title,body,如果查询“Shakespeare“,对于其中的每个域,出现为1,不出现为0,三个域对应三个权重系数,g1,g2,g3
如果g1 = 0.2;g2=0.3;g3=0.5,表示,三个域中,body中出现更加重要,如果此时某文档的title和body都出现了该词,那么这个文档的得分就是0.8。
看完这个例子就比较好理解了,但是有一个问题就是,如何才能确定各个字段的权重。通常都是从人工标注好的训练集中进行权重的训练,让程序自动确定更加准确的字段。
训练集样本大概是这样子:
如果文件有title,和body,那么St(d,q) 代表查询和文档的title域是否可以匹配
样本:$1 文档ID:37 查询:linux St:1 Sb:1 相关性判断:相关
将类似的样本集交给公式训练可以得到满足误差范围内的g,从而得到字段的权重,计算过程不再多说。
二、此项频率和权重计算。
这个中有个比较重要的概念:向量空间模型。
书上的公式是在不太好理解,在文库中看到一个文章不错,我转一下。
下面我们考虑一个固定的查询和文档集,包含一个查询Q和三篇文档组成的文档集:
Q:"gold silver truck"
D1:"Shipment of gold damaged in a fire"
D2:"Delivery of silver arrived in a silver truck"
D3:"Shipment of gold arrived in a truck"
在这个文档集中,有三篇文档,所以d = 3。如果一个词项仅在三篇文档中的一篇中出现,那么该词项的IDF就是lg(d/dfi) = lg(3/1) = 0.477。类似地,如果一个词项在三篇文档中的两篇中出现,那么该词项的IDF就是lg(d/dfi) = lg(3/2) = 0.176。如果一个词项在三篇文档中都出现了,那么该词项的IDF就是lg(d/dfi) = lg(3/3) = 0。
三篇文档的每个词项的IDF值如下所示:
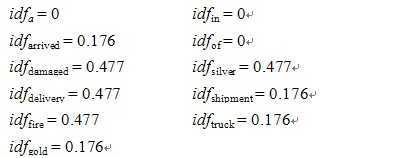
IDF(inverse document frequency),因为文档频率很高的词语,相反不是很重要的。比如一些停用词,所以引入了这个概念。
现在就可以构造文档向量了。因为文档集中出现了11个词项,所以我们构造一个11维的文档向量。我们可以用上文给出的按字母顺序排列的词项来构建文档向量,所以t1对应第一个词项"a",t2对应"arrived",依次类推。向量j中词项i的权重计算方式为idfi×tfij。文档向量如表2-1所示。
|
docid |
a |
arrived |
damaged |
delivery |
fire |
gold |
in |
of |
shipment |
silver |
truck |
|
D1 |
0 |
0 |
0.477 |
0 |
0.477 |
0.176 |
0 |
0 |
0.176 |
0 |
0 |
|
D2 |
0 |
0.176 |
0 |
0.477 |
0 |
0 |
0 |
0 |
0 |
0.954 |
0.176 |
|
D3 |
0 |
0.176 |
0 |
0 |
0 |
0.176 |
0 |
0 |
0.176 |
0 |
0.176 |
|
Q |
0 |
0 |
0 |
0 |
0 |
0.176 |
0 |
0 |
0 |
0.477 |
0.176 |
那么计算权重:
便是计算Q与各个文档的向量的内积,这个也能代表相似度
sim(Q,d1) = 0x0 + 0x0.477 + 0x0 + 0x0.477 + 0.176x0.176 + 0x0 + 0x0 + 0x0.176 + 0.477x0 + 0x0.176 = 0.031
相应的计算其他的,便可得出排序。
这是比较原始的模型。未完待续。
标签:blog http ar sp 文件 数据 2014 on 问题
原文地址:http://www.cnblogs.com/hi-net/p/4033515.html