标签:就是 类别 blog 技术 相关 直接 增加 依据 src
参考资料
学习贝叶斯分类之前,我们必须了解贝叶斯定理等相关的概率公式与含义。
设A,B是两个事件,且P(B)>0,则在事件B发生的条件下,事件A发生的条件概率:
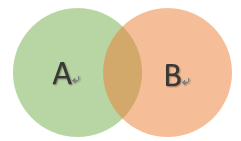
\[{\rm{P}}(A|B) = \frac{{P(AB)}}{{P(B)}}\]
由条件概率公式可得,事件A与事件B的联合概率为:
\[P(AB) = P(A|B) \cdot P(B) = P(B|A) \cdot P(A)\]
乘法公式的推广:对于任何正整数n≥2,当P(A1A2...An-1) > 0 时,有:
\[P\left( {{A_1}{A_2} \cdots {A_n}} \right) = P\left( {{A_1}} \right) \cdot P({A_2}|{A_1}) \cdot P({A_3}|{A_1}{A_2}) \cdots P({A_n}|{A_1}{A_2} \cdots {A_n})\]
以n=3作图举例: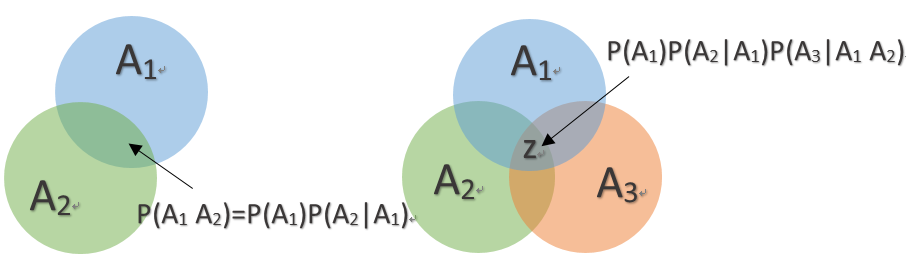
\[P\left( {\rm{z}} \right) = P\left( {{A_1}} \right) \cdot P({A_2}|{A_1}) \cdot P({A_3}|{A_1}{A_2})\]
如果事件组\(B_1\)\(,B_2\),.... 满足
\(B_1\),\(B_2\)....两两互斥,即 \(B_i?∩ B_j?= ? ,i≠j , i,j=1,2,....,\)且\(P(B_i)>0,i=1,2,....\);
\(B_1∪B_2\)∪....=Ω ,则称事件组 \(B_1,B_2,...\)是样本空间Ω的一个划分
设?\(B_1,B_2,...\)是样本空间Ω的一个划分,\(A?\)为任意事件,则:
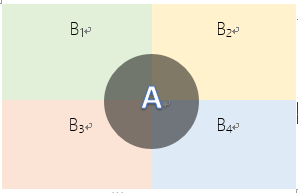
\[P\left( {\rm{A}} \right) = \;\mathop \sum \limits_{i = 1}^m P\left( {{B_i}} \right) \cdot P(A|{B_i})\]
整点有趣的:
? 假如你是一个女生, 你在你的老公书包里发现了一个别的女人的内裤那么他出轨的概率是多少?稍微熟悉这个问题的人对会知道做这个题目你要先考察基率,你要把这个问题分解为几步考虑:
在这里1其实就是先验概率 P(A),而2是条件概率/似然 P(B|A), 最终得到3是后验概率 P(A|B)这三种即是贝叶斯统计的三要素,P(B)是证据因子。
先验概率:P(原因)
后验概率:P(原因|结果)
\[P\left( {{\rm{A|B}}} \right) = \frac{{P(AB)}}{{P\left( B \right)}}=\frac{{P(B|A)P\left( A \right)}}{{P\left( B \right)}}\]
? 杂谈:有一个非常有趣的现象是如果我们的先验概率审定为1或0(即肯定或否定某件事发生), 那么无论我们如何增加证据你也依然得到同样的条件概率(此时 P(A)=0 或 1 , P(A|B)= 0或1) 这告诉我们的第一个经验就是不要过早的下论断, 下了论断你的预测也就无法进化了, 或者可以称之为信仰。
根据已有的经验和知识推断一个先验概率, 然后在新证据不断积累的情况下调整这个概率。整个通过积累证据来得到一个事件发生概率的过程我们称为贝叶斯分析。
贝叶斯分析可以瞬间理解一些常用的理论, 如幸存者偏差,你发现一些没读过书的人很有钱,事实上是你发现就已经是幸存者了(对应上图中小红圈), 而死了的人(红圈外的大部分面积)你都没见到啊。还有阴谋论, 阴谋论的特点是条件很多很复杂, 但是条件一旦成立,结论几乎成立, ?你一旦考虑了先验,这些条件成立本身即很困难, 阴谋论不攻自克。
? 贝叶斯学派很古老,但是从诞生到一百年前一直不是主流。主流是频率学派。频率学派的权威皮尔逊和费歇尔都对贝叶斯学派不屑一顾,但是贝叶斯学派硬是凭借在现代特定领域的出色应用表现为自己赢得了半壁江山。
? 贝叶斯学派的思想可以概括为先验概率+数据=后验概率。也就是说我们在实际问题中需要得到的后验概率,可以通过先验概率和数据一起综合得到。数据大家好理解,被频率学派攻击的是先验概率,一般来说先验概率就是我们对于数据所在领域的历史经验,但是这个经验常常难以量化或者模型化,于是贝叶斯学派大胆的假设先验分布的模型,比如正态分布,beta分布等。这个假设一般没有特定的依据,因此一直被频率学派认为很荒谬。虽然难以从严密的数学逻辑里推出贝叶斯学派的逻辑,但是在很多实际应用中,贝叶斯理论很好用,比如垃圾邮件分类,文本分类。
? 在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同。对于大多数的分类算法,比如决策树,KNN,逻辑回归,支持向量机等,他们都是判别方法,也就是直接学习出特征输出\(Y\)和特征\(X\)之间的关系,要么是决策函数\(Y=f(X)\),要么是条件分布\(P(Y|X)\)。
但是朴素贝叶斯却是生成方法,
也就是直接找出特征输出Y和特征X的联合分布\(P(X,Y)\),
然后用\[P\left( {{\rm{Y|X}}} \right) = \frac{{P(Y,X)}}{{P\left( X\right)}}=\frac{{P(X|Y)P\left( Y \right)}}{{P\left( X \right)}}\]得出属于各个类别的概率。
从统计学知识回到我们的数据分析。假如我们的分类模型样本是:
\[
(x_1^{(1)}, x_2^{(1)}, ...x_n^{(1)}, y_1), (x_1^{(2)}, x_2^{(2)}, ...x_n^{(2)},y_2), ... (x_1^{(m)}, x_2^{(m)}, ...x_n^{(m)}, y_n)
\]
即我们有\(m\)个样本,每个样本有\(n\)个特征,特征输出有\(K\)个类别,定义为\(C_1,C_2,...,C_K\)
1.从样本可以学习得到朴素贝叶斯的先验分布\(P(Y=C_k)(k=1,2,...K)\),通过最大似然法求出,得到的\(P(Y=C_k)\)就是类别\(C_k\)在训练集里面出现的频数 。
2.接着学习到条件概率分布\(P(X=x|Y=C_k) = P(X_1=x_1, X_2=x_2,...X_n=x_n|Y=C_k)\)
3.然后我们就可以用贝叶斯公式得到X和Y的联合分布\((X,Y)\)
\[ \begin{align} P(X,Y=C_k) &= P(Y=C_k)P(X=x|Y=C_k) \\&= P(Y=C_k)P(X_1=x_1, X_2=x_2,...X_n=x_n|Y=C_k) \end{align} \]
4.\(P(X_1=x_1, X_2=x_2,...X_n=x_n|Y=C_k)\)很难求出,这是一个超级复杂的有\(n\)个维度的条件分布。
5.最后的的\(P(X=x)\) ,一样通过最大似然法求出,就是训练集里面出现的频数(实际是省略的)。
问题出现,为了解决第四步中的 \(n\)维度分布 这个问题,所使用的办法才使得“朴素”两字出现。
朴素贝叶斯模型在这里做了一个大胆的假设,即\(X\)的\(n\)个维度之间相互独立,这样就可以得出:
\[
P(X_1=x_1, X_2=x_2,...X_n=x_n|Y=C_k) = P(X_1=x_1|Y=C_k)P(X_2=x_2|Y=C_k)\\...P(X_n=x_n|Y=C_k)
\]
从上式可以看出,这个很难的条件分布大大的简化了,但是这也可能带来预测的不准确性。你会说如果我的特征之间非常不独立怎么办?如果真是非常不独立的话,那就尽量不要使用朴素贝叶斯模型了,考虑使用其他的分类方法比较好。但是一般情况下,样本的特征之间独立这个条件的确是弱成立的,尤其是数据量非常大的时候。虽然我们牺牲了准确性,但是得到的好处是模型的条件分布的计算大大简化了,这就是贝叶斯模型的选择
? 最后回到我们要解决的问题,我们的问题是给定测试集的一个新样本特征,我们如何判断它属于哪个类型?
既然是贝叶斯模型,当然是后验概率最大化来判断分类了。我们只要计算出所有的K个条件概率\(P(Y=C_k|X=X^{(test)})\),然后找出最大的条件概率对应的类别,这就是朴素贝叶斯的预测了
标签:就是 类别 blog 技术 相关 直接 增加 依据 src
原文地址:https://www.cnblogs.com/stream886/p/10506810.html