标签:input 图片 mapr 定义 throw 代码 产生 void percent


package com.gec.demo; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class WcCombiner extends Reducer<Text, IntWritable,Text,IntWritable> { private IntWritable sum=new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count=0; for (IntWritable value : values) { count+=value.get(); } sum.set(count); context.write(key,sum); } }
在job类中声明如下:
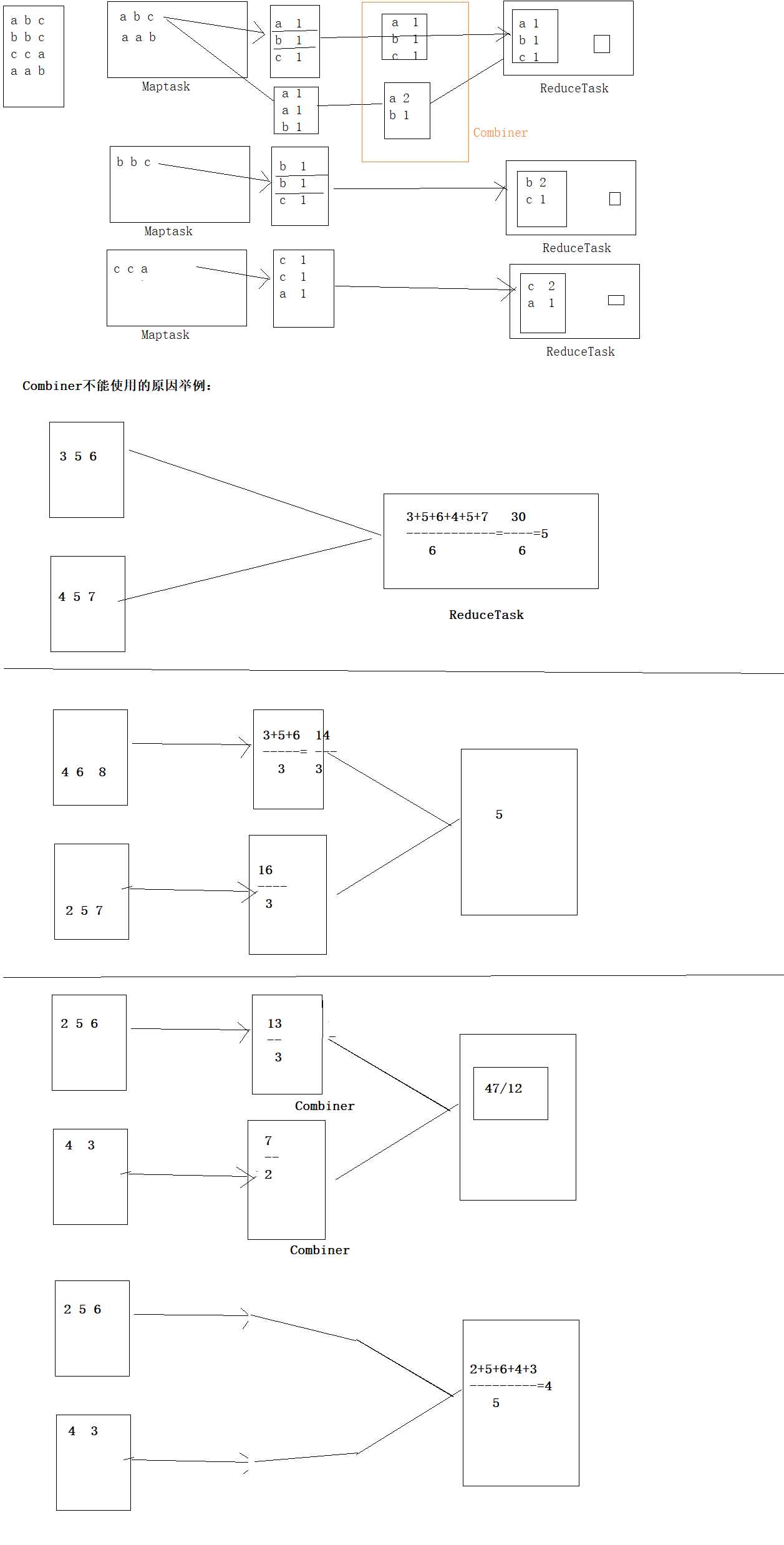

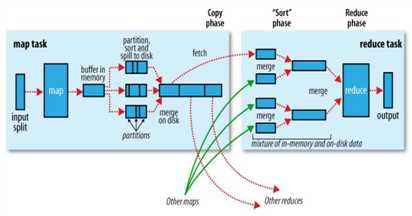
在这一头存储key和value,key和value依次排列,而那一头存储索引,向中间出发,当储存的空间占比百分之八十的时候,则溢出,两者的方向改变,分别开始从另外一头开始存储
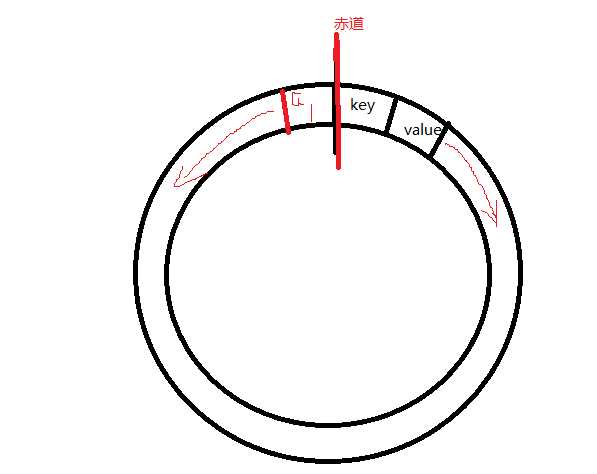
如上图,从赤道分别向不同方向出发
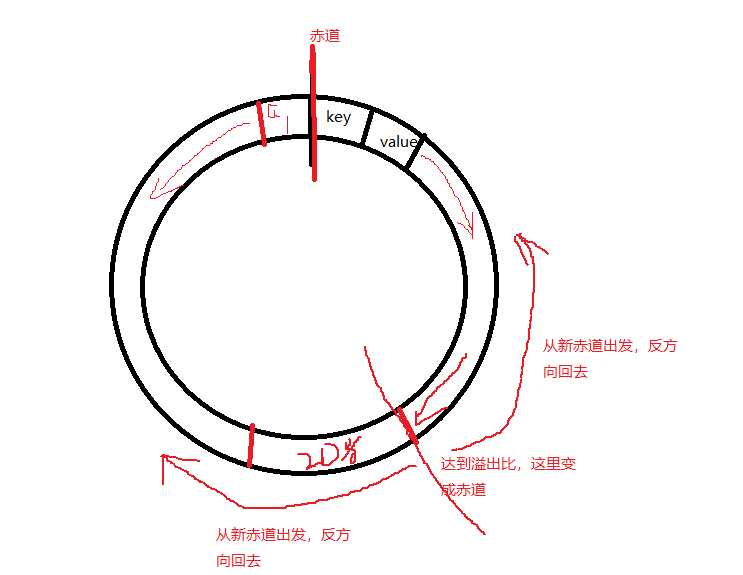
如上图,到达溢出时,产生新赤道,又分别从新赤道往回走
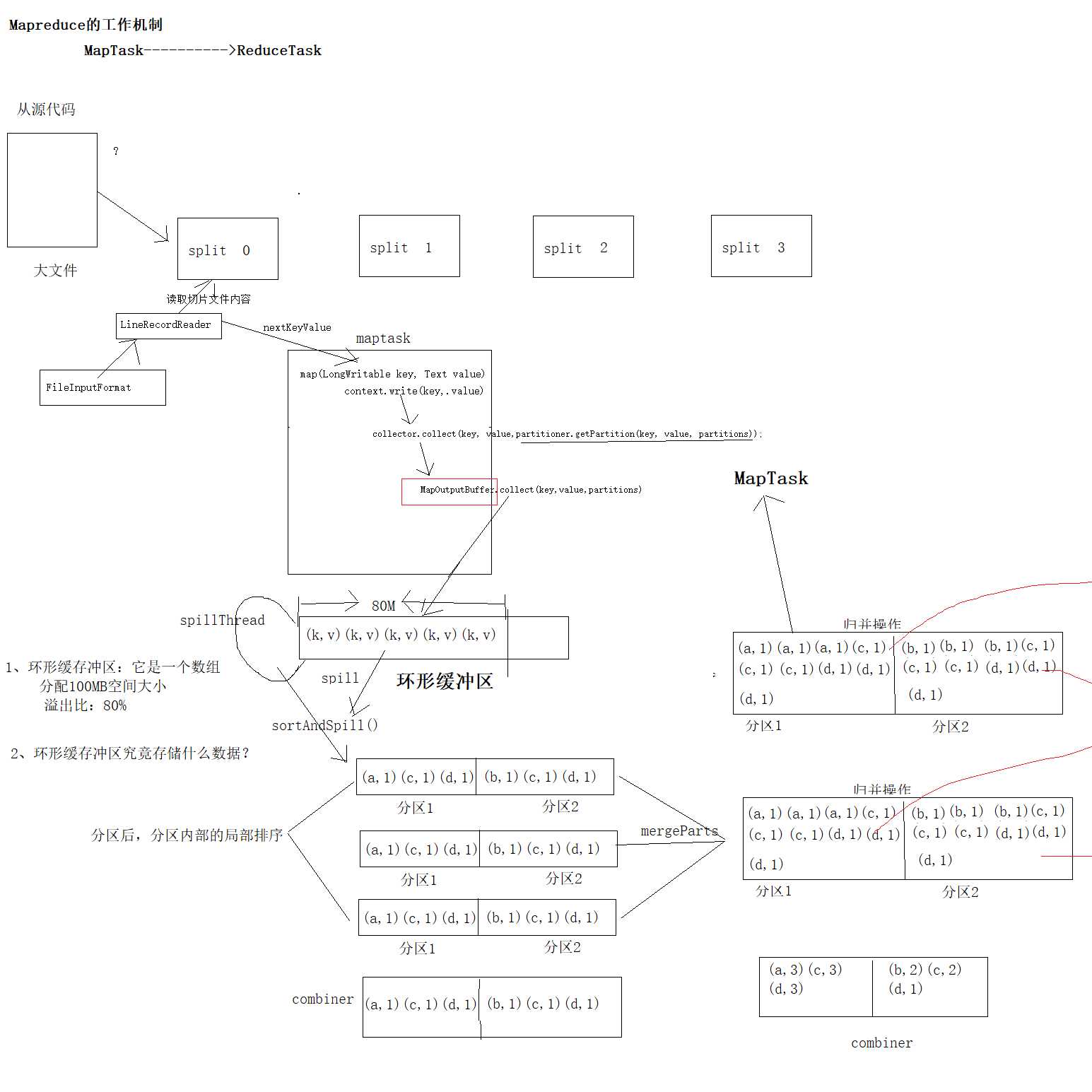
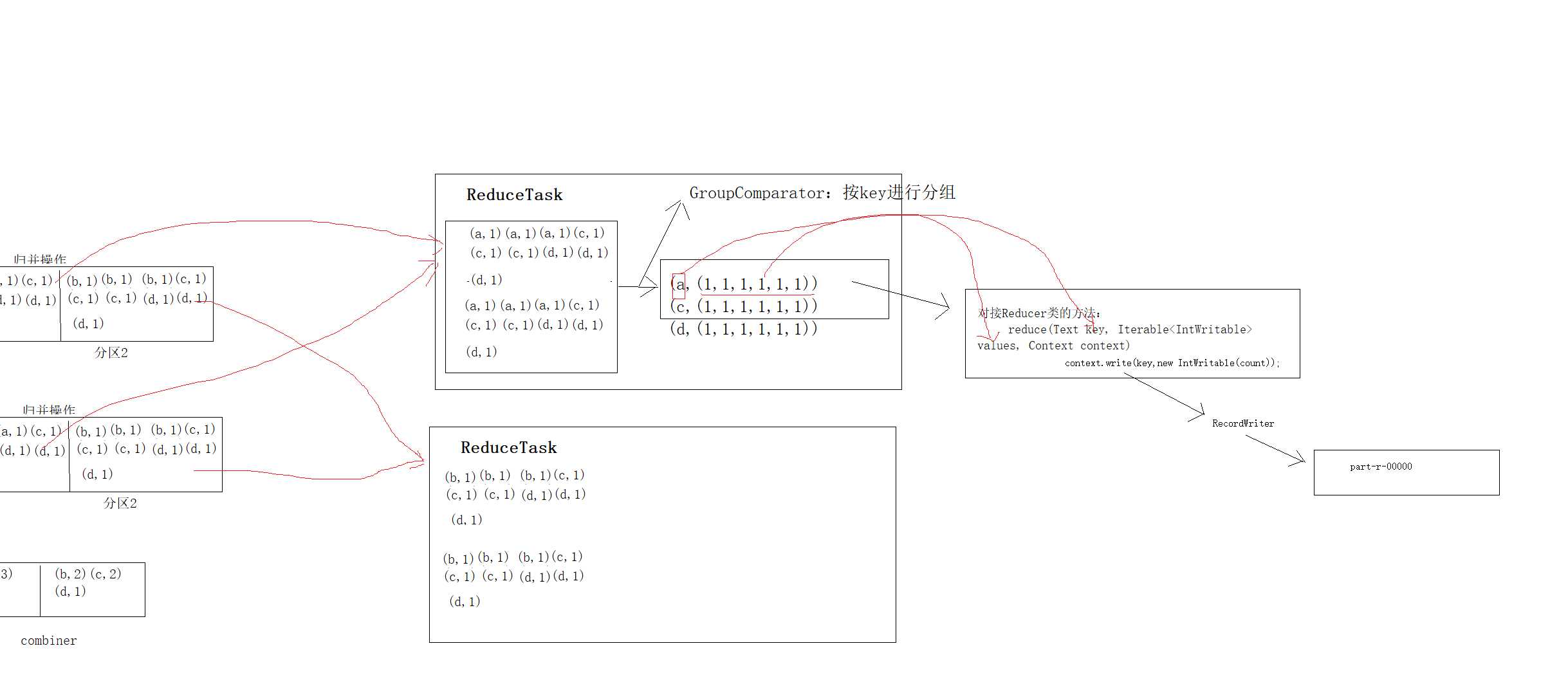
ReduceTask工作机制
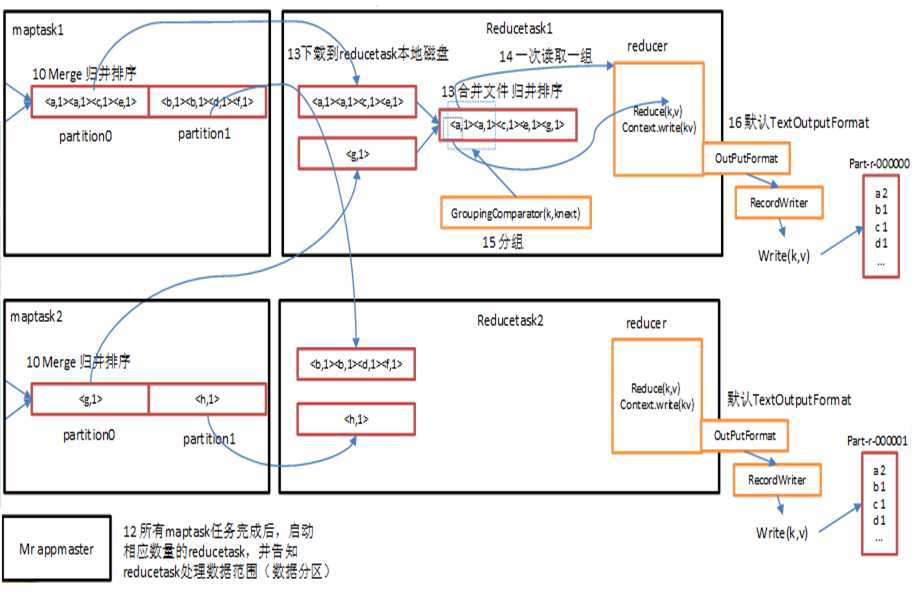
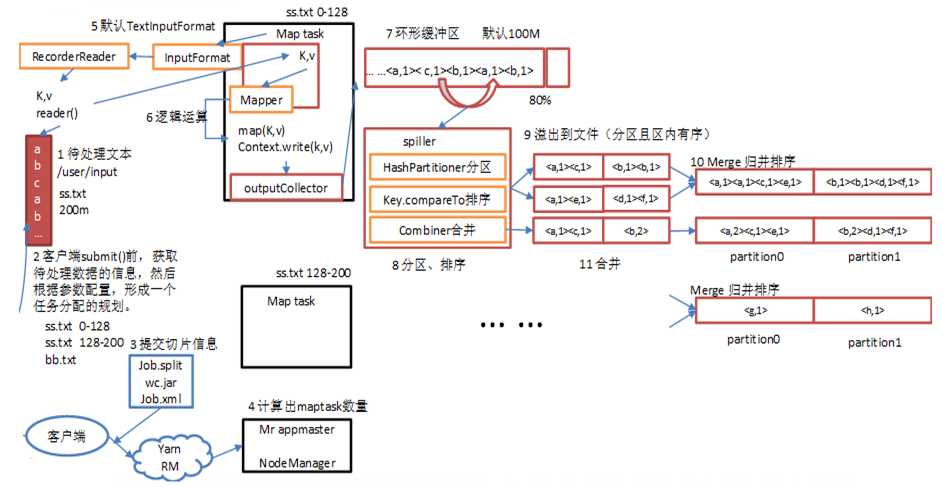
shuffer缓存流程

标签:input 图片 mapr 定义 throw 代码 产生 void percent
原文地址:https://www.cnblogs.com/Transkai/p/10508165.html