标签:use key arc 分布式 rcfile strong not 重构 snap
这几天研究hive表的存储方式和压缩模式。在这里做一个简单的总结
hive表的存储
样例 : 我的表:rp_person_house_loan_info
数据总量:1933776
textfile:
(1)hive数据表的默认格式,存储方式:行存储 。
(2) 可使用Gzip,Bzip2等压缩算法压缩,压缩后的文件不支持split
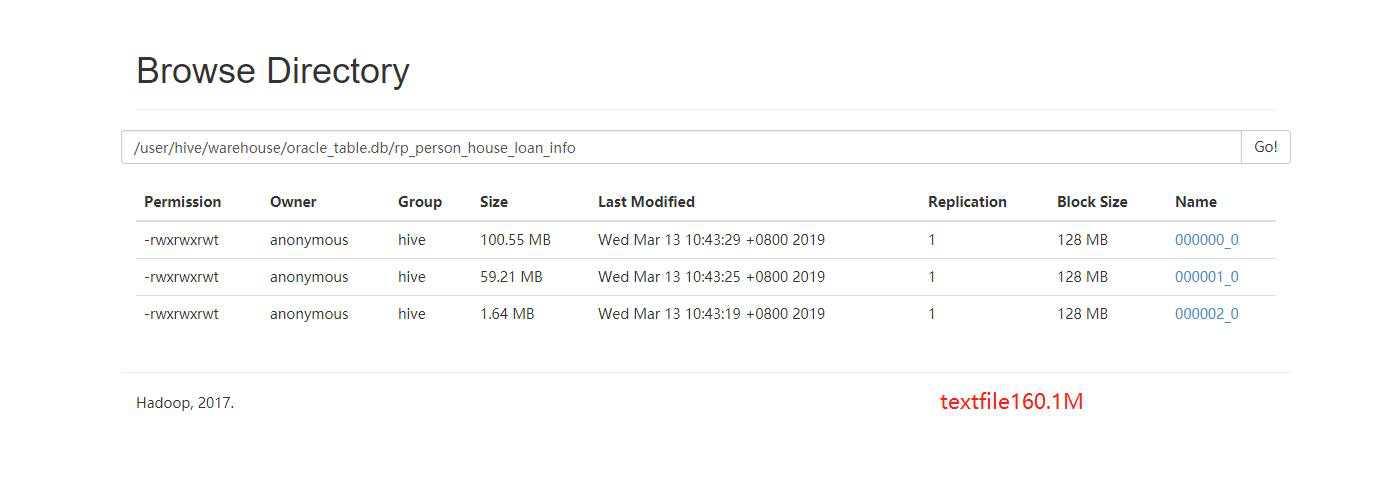
上面的数据存储格式为textfile,文件没有压缩总的文件大小为160.1M。
SequenceFile
(1)Hadoop API提供的一种二进制文件,以<key,value>的形式序列化到文件中。存储方式:行存储。
(2)支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
(3)优势是文件和hadoop api中的MapFile是相互兼容的
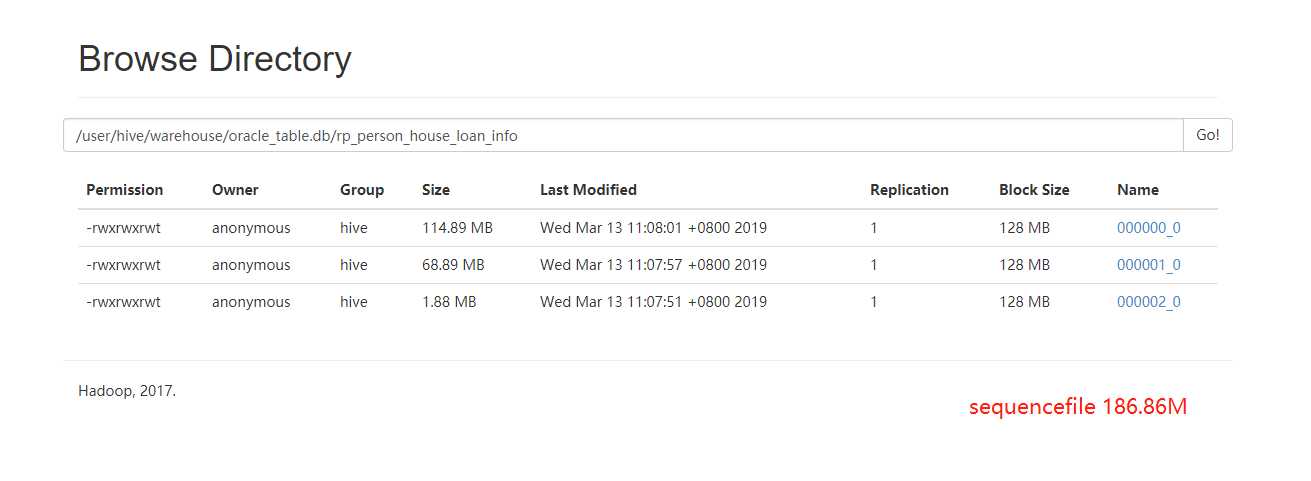
上面数据的存储模式为sequencefile,总的文件大小为186.86M
RCFile
(1)存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:
(2)首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低
(3)其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取
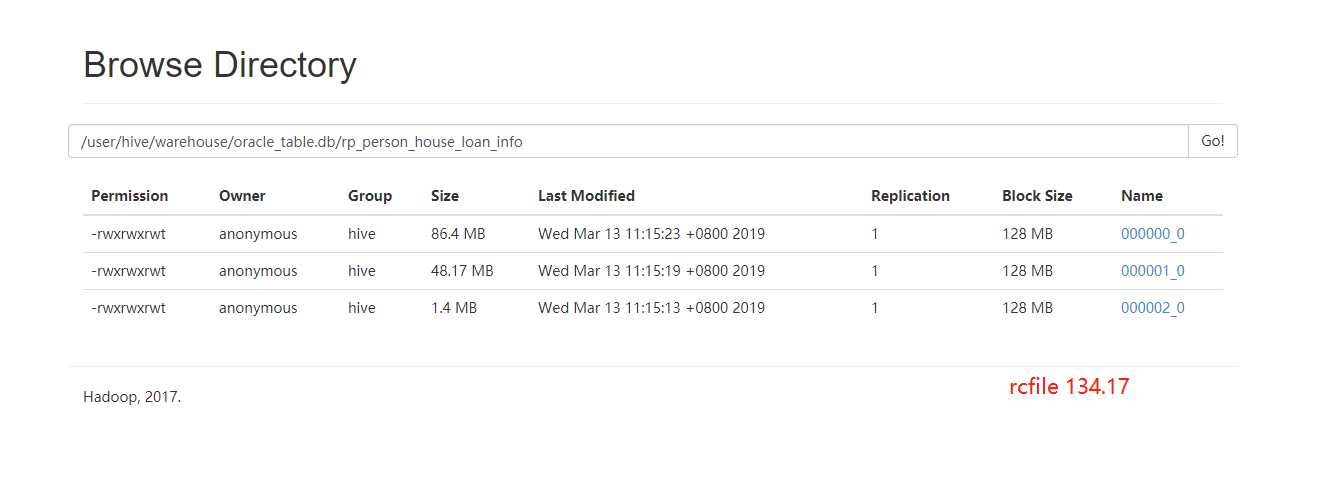
上面数据的存储模式为RCFile,总的文件大小为134.17M
ORCFile
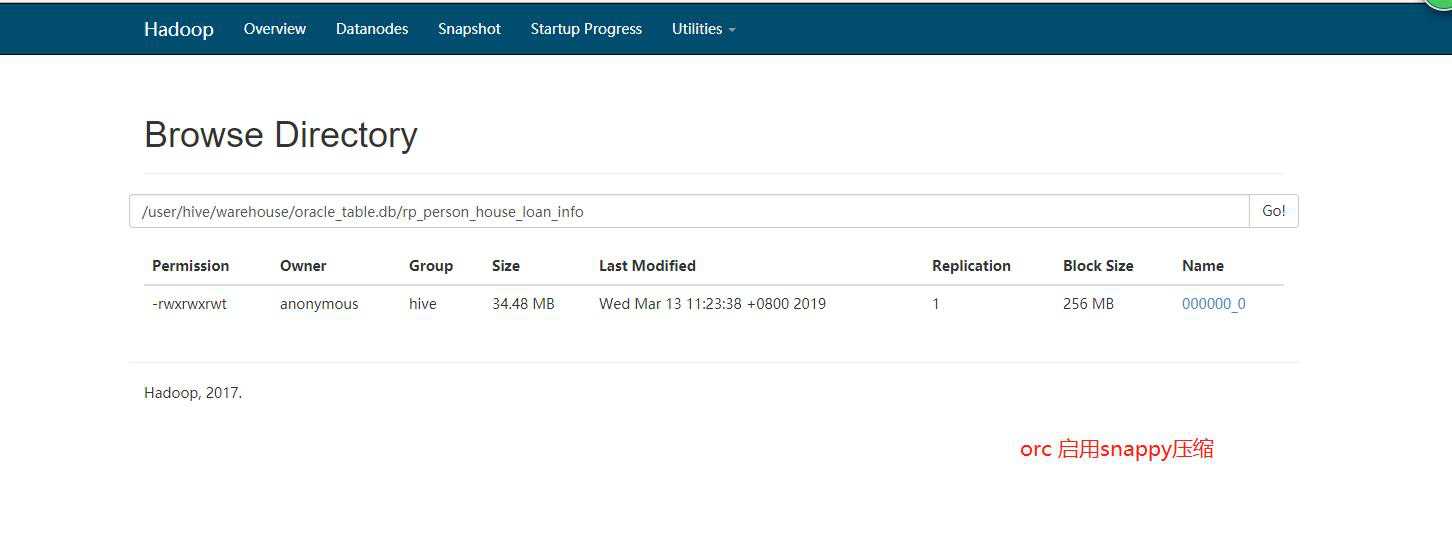
上面数据的存储模式为orc模式,同时启动了snappy的压缩模式,总的文件大小为34.48M 下面是orc 的snappy压缩的表结构:
总结:
我们再建设数据仓库的时候,通常都是一次写入,多次读取
存储文件的大小的关系:
SequenceFile > TextFile > RCfile
TextFile 默认格式,加载速度最快,可以采用Gzip、bzip2等进行压缩,压缩后的文件无法split,即并行处理
SequenceFile 压缩率最低,查询速度一般,三种压缩格式NONE,RECORD,BLOCK
RCfile 压缩率最高,查询速度最快,数据加载最慢。
orc (snappy压缩模式) 查询速度更快
所以在数据仓库的建设过程当中尽量的使用orc的这种模式再加上压缩模式。一方面减少磁盘的使用量,一方面可以实现数据的split(分布式计算),实现查询速度加快。
建立orc的snappy压缩模式的建表语句如下:
CREATE TABLE IF NOT EXISTS rp_person_house_loan_info ( loan_no varchar(20), if_me varchar(5) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ STORED AS orc tblproperties ("orc.compress"="SNAPPY");
对于其他的模式启动压缩的方式:
在插入之前对表的压缩模式进行设定
set hive.exec.compress.output=true; set mapred.output.compress=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
标签:use key arc 分布式 rcfile strong not 重构 snap
原文地址:https://www.cnblogs.com/gxgd/p/10522112.html