标签:eve manager mysql hive its nta response employee against
presto 0.217

官方:http://prestodb.github.io/
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Presto was designed and written from the ground up for interactive analytics and approaches the speed of commercial data warehouses while scaling to the size of organizations like Facebook.
presto是一个开源的分布式sql查询引擎,用于大规模(从GB到PB)数据源的交互式分析查询,并且达到商业数据仓库的查询速度;
Presto allows querying data where it lives, including Hive, Cassandra, relational databases or even proprietary data stores. A single Presto query can combine data from multiple sources, allowing for analytics across your entire organization.
Presto is targeted at analysts who expect response times ranging from sub-second to minutes. Presto breaks the false choice between having fast analytics using an expensive commercial solution or using a slow "free" solution that requires excessive hardware.
presto允许直接查询外部数据,包括hive、cassandra、rdbms以及文件系统比如hdfs;一个presto查询中可以同时使用多个数据源的数据来得到结果;presto在‘昂贵且快的商业解决方案’和‘免费且慢的开源解决方案’之间提供了一个新的选择;
Facebook uses Presto for interactive queries against several internal data stores, including their 300PB data warehouse. Over 1,000 Facebook employees use Presto daily to run more than 30,000 queries that in total scan over a petabyte each per day.
facebook使用presto来进行多个内部数据源的交互式查询,包括300PB的数据仓库;每天有超过1000个facebook员工在PB级数据上使用presto运行超过30000个查询;
Leading internet companies including Airbnb and Dropbox are using Presto.
业界领先的互联网公司包括airbnb和dropbox都在使用presto,下面是airbnb的评价:
Presto is amazing. Lead engineer Andy Kramolisch got it into production in just a few days. It‘s an order of magnitude faster than Hive in most our use cases. It reads directly from HDFS, so unlike Redshift, there isn‘t a lot of ETL before you can use it. It just works.
--Christopher Gutierrez, Manager of Online Analytics, Airbnb
Presto is a distributed system that runs on a cluster of machines. A full installation includes a coordinator and multiple workers. Queries are submitted from a client such as the Presto CLI to the coordinator. The coordinator parses, analyzes and plans the query execution, then distributes the processing to the workers.
presto是一个运行在集群上的分布式系统,包括一个coordinator和多个worker,client(比如presto cli)提交查询到coordinator,然后coordinator解析、分析和计划查询如何执行,然后将任务分配给worker;
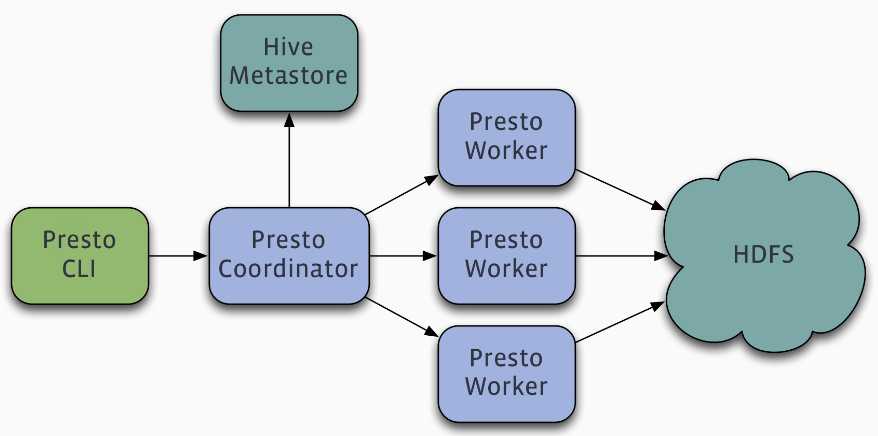
Presto supports pluggable connectors that provide data for queries. The requirements vary by connector.
presto提供插件化的connector来支持外部数据查询,原生支持hive、cassandra、elasticsearch、kafka、kudu、mongodb、mysql、redis等众多外部数据源;
详细参考:https://prestodb.github.io/docs/current/connector.html
# wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.217/presto-server-0.217.tar.gz
# tar xvf presto-server-0.217.tar.gz
# cd presto-server-0.217
Presto needs a data directory for storing logs, etc. We recommend creating a data directory outside of the installation directory, which allows it to be easily preserved when upgrading Presto.
Create an etc directory inside the installation directory. This will hold the following configuration:
# mkdir etc # cat etc/node.properties node.environment=production node.id=ffffffff-ffff-ffff-ffff-ffffffffffff node.data-dir=/var/presto/data # cat etc/jvm.config -server -Xmx16G -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:+ExitOnOutOfMemoryError # cat etc/config.properties # coordinator coordinator=true node-scheduler.include-coordinator=false http-server.http.port=8080 query.max-memory=50GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery-server.enabled=true discovery.uri=http://example.net:8080 # worker coordinator=false http-server.http.port=8080 query.max-memory=50GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery.uri=http://example.net:8080 # cat etc/log.properties com.facebook.presto=INFO
注意:
1)coordinator和worker的config.properties不同,主要是coordinator上会开启discovery服务
discovery-server.enabled: Presto uses the Discovery service to find all the nodes in the cluster. Every Presto instance will register itself with the Discovery service on startup. In order to simplify deployment and avoid running an additional service, the Presto coordinator can run an embedded version of the Discovery service. It shares the HTTP server with Presto and thus uses the same port.
2)如果coordinator和worker位于不同机器,则设置
node-scheduler.include-coordinator=false
如果coordinator和worker位于相同机器,则设置
node-scheduler.include-coordinator=true
node-scheduler.include-coordinator: Allow scheduling work on the coordinator. For larger clusters, processing work on the coordinator can impact query performance because the machine’s resources are not available for the critical task of scheduling, managing and monitoring query execution.
Presto accesses data via connectors, which are mounted in catalogs. The connector provides all of the schemas and tables inside of the catalog. For example, the Hive connector maps each Hive database to a schema, so if the Hive connector is mounted as the hive catalog, and Hive contains a table clicks in database web, that table would be accessed in Presto as hive.web.clicks.
以hive为例
# mkdir etc/catalog # cat etc/catalog/hive.properties connector.name=hive-hadoop2 hive.metastore.uri=thrift://example.net:9083 #hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml
详细参考:https://prestodb.github.io/docs/current/connector.html
# bin/launcher run --verbose
Presto requires Java 8u151+ (found 1.8.0_141)
需要jdk1.8.151以上
# bin/launcher start
# wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.217/presto-cli-0.217-executable.jar # mv presto-cli-0.217-executable.jar presto # chmod +x presto # ./presto --server localhost:8080 --catalog hive --schema default
# wget https://repo1.maven.org/maven2/com/facebook/presto/presto-jdbc/0.217/presto-jdbc-0.217.jar # export HIVE_AUX_JARS_PATH=/path/to/presto-jdbc-0.217.jar # beeline -u jdbc:presto://example.net:8080/hive/sales
参考:https://prestodb.github.io/overview.html
标签:eve manager mysql hive its nta response employee against
原文地址:https://www.cnblogs.com/barneywill/p/10478959.html