标签:style blog http color os java strong sp 文件
视频地址:http://pan.baidu.com/s/1dDEgKwD
着重介绍了HDFS
运行了示例程序wordcount,自己也试了一遍(用的伪分布式)
1.建立数据(和讲师的操作有些不一样,不过我相信自己)
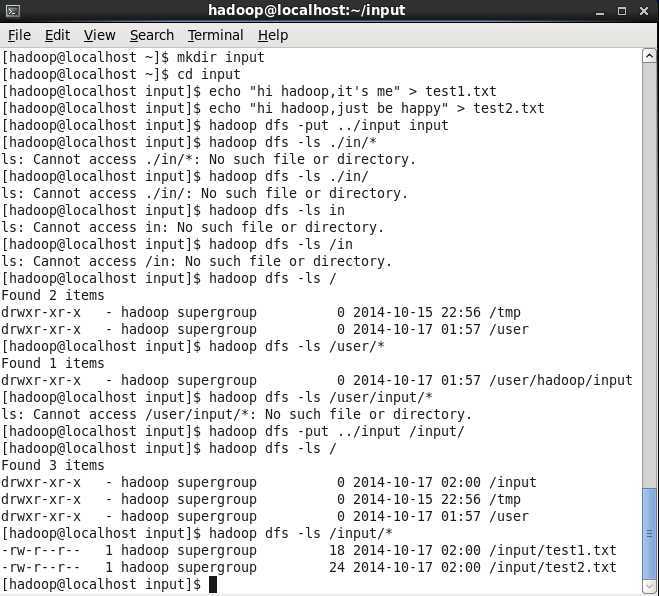
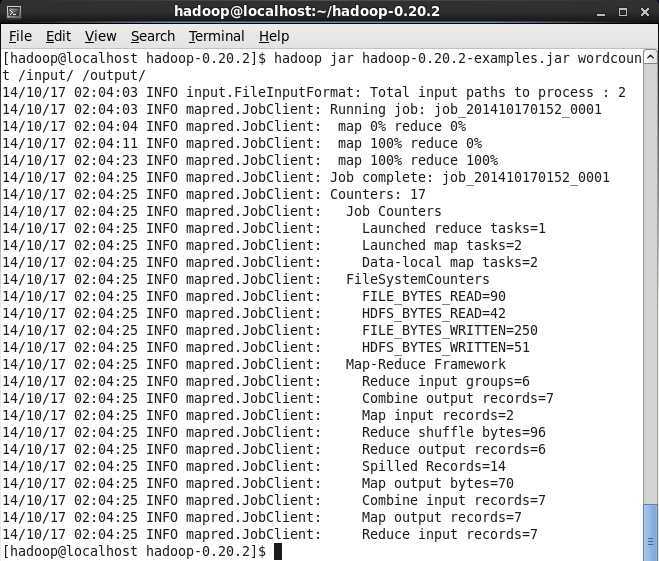
2.运行wordcount程序
3.查看结果
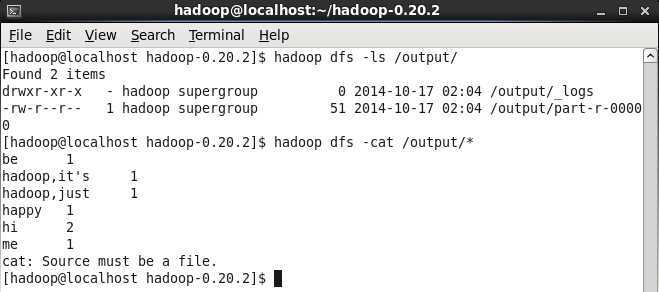
(可以看出来,只要没空格,它都看作是一个单词)
接下来介绍了50030和50070查看任务和HDFS状态
......
其中如果想看日志的话除了命令行也可以直接输入
查看堆栈信息

关闭,再也不能修改,说的很绝对,但是是正确的,因为之后的修改是删除重写

其中机架策略看着比较神奇,我知道机架感知的结果,但是不知道以什么策略感知的,或许是上下文、带宽,讲师也不知道,留着后面探索
回收站,跟windows的机理一样,删除了的文件不会马上完全删除。当到一定的容量的时候会自动删除
快照机制,讲师说0.20.2还没实现,以后会实现,也没讲。
介绍了HDFS文件操作包括命令行和API(API是给如Java代码用的)
几个命令行命令
... ...
查看统计信息 hadoop dfsadmin -report
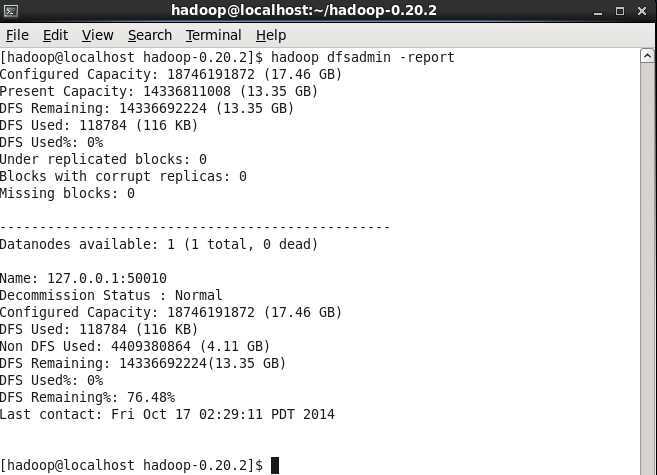
接下来讲了添加新节点方式,不过我觉得他讲的不对或者不全,我查了一下网上,随后详细实验一把再写出来
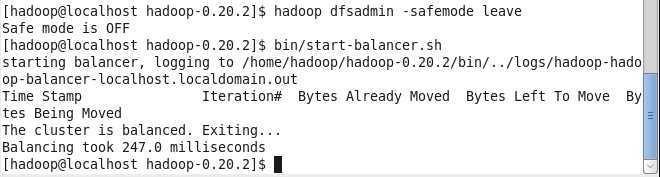
负载均衡(hdfs存储)
讲师给的截图有点忽悠人

他是在没运行hadoop的情况下运行的这个脚本,真实的情况应该是这样的
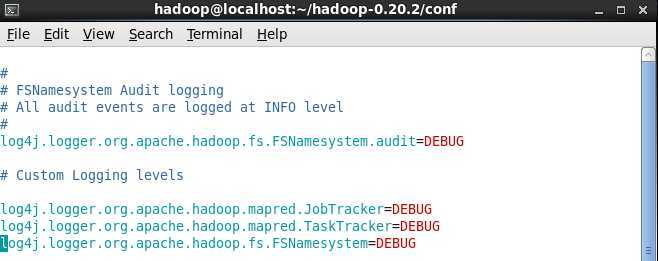
刚开始的时候可以把Log4J的日志级别降到Info或者DEBUG,这样显示的信息更多
为什么日志成了hadoop项目中最多的一种?
一次写入,不再改变,只能用于分析
Linux下统计目录下有多少文件命令
ls|wc -l
shuffle过程的作用
1.压缩文件,提高文件传输效率;
2.分担了reduce的一部分工作。
像split、sort这样的工作很多MR程序都要做,所以hadoop把他们分离出来,封装成了一个组件
不必在每个MR程序中自己编写
MR程序的提交或者说任务的提交可以在任何一台集群机器上,不是非得在namenode上
就是说client端可以是datanode、namenode。
启动JVM很浪费时间和资源,所以有了JVM重用
为什么namenode需要格式?
格式化不同于磁盘文件系统的格式化。是初始化元文件系统信息,在相应目录建立current等目录等
hadoop的数据不修改那还要in_use.lock干什么?
给目录上锁,防止目录中内容的并发写冲突
标签:style blog http color os java strong sp 文件
原文地址:http://www.cnblogs.com/admln/p/dataguru3.html