标签:com name apt-get code 新建 libs window 系统 注意事项
一、Windows安装
Twisted下载及安装
在https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载对应的Twisted的版本文件
在命令行进入到Twisted的目录 执行pip install 加Twisted文件名
执行命令 pip install scrapy
二、Ubuntu安装
下载twisted
wget https://files.pythonhosted.org/packages/90/50/4c315ce5d119f67189d1819629cae7908ca0b0a6c572980df5cc6942bc22/Twisted-18.7.0.tar.bz2
解压,并cd进去
tar -xjvf Twisted-18.7.0.tar.bz2
cd ./Twisted-18.7.0.tar.bz2
安装twisted
Ubuntu安装注意事项
不要使用 python-scrapyUbuntu提供的软件包,它们通常太旧而且速度慢,无法赶上最新的Scrapy。 要在Ubuntu(或基于Ubuntu)系统上安装scrapy,您需要安装这些依赖项: sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev 如果你想在python3上安装scrapy,你还需要Python3的开发头文件: sudo apt-get install python3-dev 在virtualenv中,你可以使用pip安装Scrapy: pip install scrapy
三、新建项目
通过scrapy命令可以很方面的新建scrapy项目。
语法格式:scrapy startproject <project_name> [project_dir]
四、编写爬虫
会在spiders文件下生成文件
语法格式:scrapy genspider 爬虫名 域名
五、运行爬虫
运行命令:scrapy crawl 爬虫名称
六、运行流程
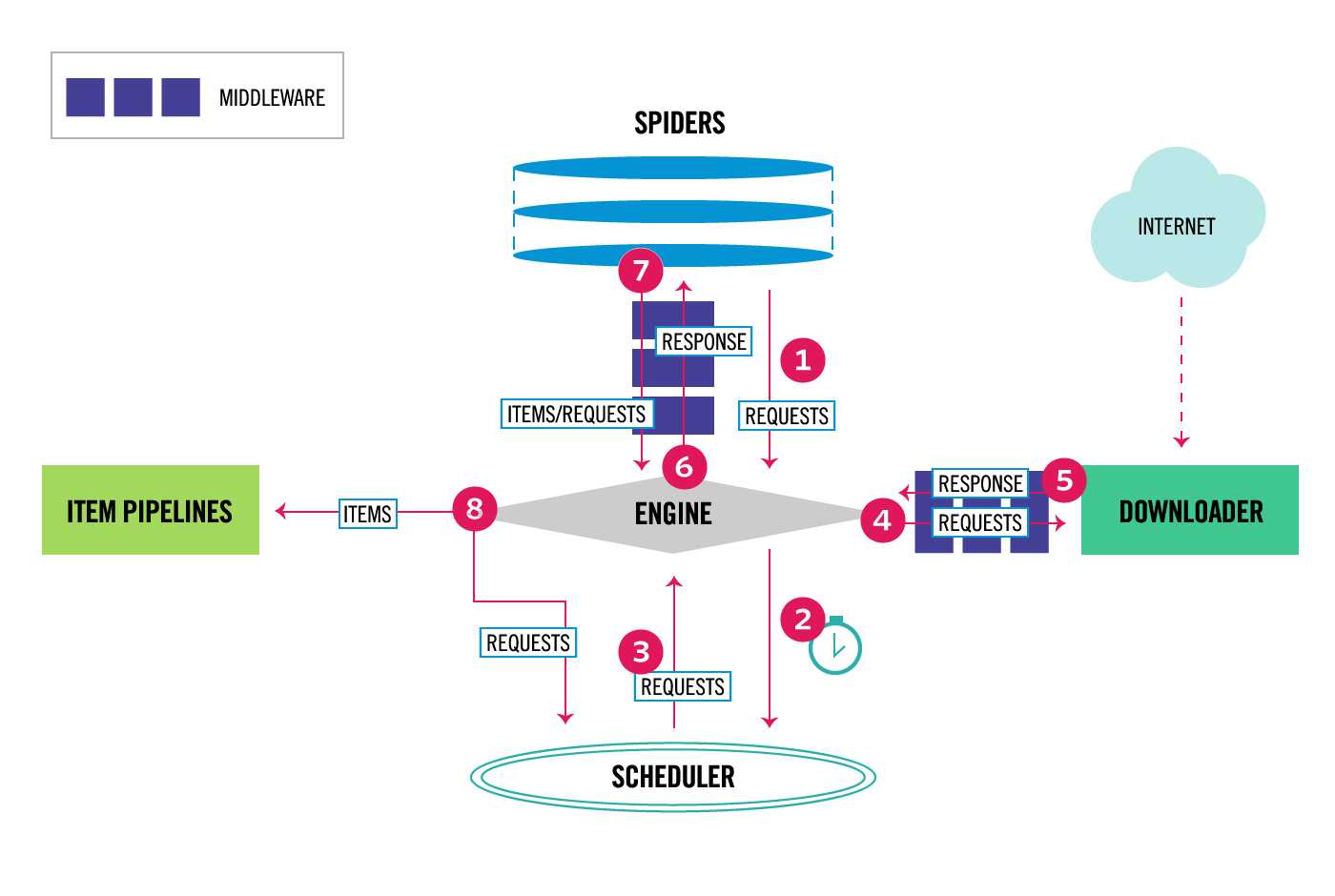
图显示了Scrapy框架的体系结构及其组件,以及系统内部发生的数据流(由红色的箭头显示。) Scrapy中的数据流由执行引擎控制,
流程如下:
首先从爬虫获取初始的请求
将请求放入调度模块,然后获取下一个需要爬取的请求
调度模块返回下一个需要爬取的请求给引擎
引擎将请求发送给下载器,依次穿过所有的下载中间件
一旦页面下载完成,下载器会返回一个响应包含了页面数据,然后再依次穿过所有的下载中间件。
引擎从下载器接收到响应,然后发送给爬虫进行解析,依次穿过所有的爬虫中间件
爬虫处理接收到的响应,然后解析出item和生成新的请求,并发送给引擎
引擎将已经处理好的item发送给管道组件,将生成好的新的请求发送给调度模块,并请求下一个请求
该过程重复,直到调度程序不再有请求为止。
标签:com name apt-get code 新建 libs window 系统 注意事项
原文地址:https://www.cnblogs.com/jun-1024/p/10549815.html