标签:pathinfo rfc 内容类型 val 收件人 xml语法 doctype reset 发送请求
1.字符编码的原由
1.1 request和response的默认编码是?
如果未指定字符编码,则Servlet规范要求使用ISO-8859-1的编码。 HTTP消息正文(请求或响应)的字符编码在Content-Type头字段中指定。 如Content-Type:text / html; charset = ISO-8859-1明确声明正在使用默认值(ISO-8859-1)。见HTTP 1.1 Specification, Section 3.7.1最后一段。
JSP规范进一步指定了JSP页面的行为。 请求字符编码处理是相同的,但响应字符编码的行为略有不同。 请参阅“JSP.4.2响应字符编码”一章。 对于标准语法中的JSP页面,默认响应字符集是通常的ISO-8859-1,但对于XML语法中的字符串,它是UTF-8。
1.2 request和response的默认编码为什么是它们?
从容器角度:
先说请求编码,目前许多浏览器不会随着Content-Type发送字符编码,即Content-Type没有"charset=utf-8"这样的字段。因此,怎么对请求进行解码,Servlet 3.1和Servlet 4.0都对此进行了说明。
Servlet 3.1
在没有charset限定符的情况下,容器对请求的解码将使用ISO-8859-1字符集进行解码。为了显示Content-Type没有指定charset,request.getCharaterEncoding()将返回null;
Servlet4.0
在没有charset限定符的情况下,如果Content-Type是application / x-www-form-urlencoded,则容器用于创建请求阅读器和解析POST数据的默认编码必须是US-ASCII,任何%nn编码值必须解码为ISO-8859-1。
如何Content-Type是任何其他类型,如果客户端请求,Web应用程序(在web.xml中没有指定)或容器供应商特定配置(对于容器中的所有Web应用程序)都没有指定,则默认编码为请求容器用于创建请求读取器和解析POST数据必须是ISO-8859-1。
从上述的两个规范看出,如客户端没有设置字符编码,servlet无法知道编码,如果请求数据使用与上述默认编码不同的编码进行编码,则可能发生破坏。
——————————————————————————————————————————————————————————
从浏览器角度:
GET的默认编码:
HTTP查询字符串的编码规范(即GET请求的参数 )RFC 3986 在2.1和2.2节有说明。字符集定义为US-ASCII。任何未映射到US-ASCII的字符都必须以某种方式(也就是说没有指定)进行编码。 URI语法规范的2.1节说明US-ASCII之外的字符必须使用%转义序列进行编码:每个字符编码为文字%,后跟两个十六进制代码,表示其字符代码。因此,(字符”中“)等同于%E4%B8%AD。虽然URI规范没有强制要求URI的默认编码,但它建议使用UTF-8,特别是对于新的URI方案,并且大多数现代用户代理已经确定UTF-8用于编码URI字符。
注意:1. ISO-8859-1和ASCII兼容字符代码0x20至0x7E,因此它们通常可互换使用。
2. 使用UTF-8编码URI的现代浏览器。某些浏览器似乎使用当前页面的编码来编码链接的URI,Chrome使用UTF-8。
3. HTML 4.0建议使用UTF-8对查询字符串进行编码。
POST的默认编码:
较早版本的HTTP / 1.1规范(例如RFC 2616)表明,如果没有指示字符集,ISO-8859-1是基于文本的HTTP请求和响应主体的默认字符集。尽管RFC 7231删除了此缺省值,但servlet规范仍然适用。因此,servlet规范指示如果POST请求不指示编码,则必须将其处理为ISO-8859-1,但application / x-www-form-urlencoded除外,默认情况下应将其解释为US-ASCII(因为它根据定义应该只包含ASCII范围内的字符开头)。
关于POST请求的字符编码的一些注意事项:
RFC 2616第3.4.1节规定,如果请求有"charset=charsetName",HTTP消息的接收者必须遵守Content-Type头中发件人指定的字符编码。丢失的字符允许收件人“猜测”适当的编码。
今天的大多数Web浏览器都没有指定请求的字符集,即使它不是ISO-8859-1。这似乎违反了HTTP规范。大多数Web浏览器似乎使用用页面的编码来发送请求正文(例如,<form>元提交的参数编码是根据页面的编码来编码的)。
ContentType为application / x-www-form-urlencoded的URI编码:
HTML 4.01规范指出应该使用US-ASCII字节序列执行application / x-www-form-urlencoded(HTML表单提交的默认内容类型)的任何非字母数字字符的百分比编码。但是HTML 5将其更改为使用UTF-8字节序列,匹配URL的现代URI编码。因此,现代浏览器在使用application / x-www-form-urlencoded提交表单时用UTF-8对其进行编码。
但是,servlet规范要求servlet容器将ContentType为application / x-www-form-urlencoded的请求正文用ISO-8859-1解码,在默认配置中,由于字符集不匹配,将导致内容损坏。请参阅下文,了解如何在Tomcat中重新配置它。
HTTP Header的编码。
ARPA Internet文本消息规范的第3.1节规定Header始终采用US-ASCII编码。除此之外的任何东西都需要编码,参阅上面有关URI中查询字符串的部分。
1.3 URIEncoding&useBodyEncodingForURI是什么?
两者都是Http connector的属性。见apache-tomcat-9.0.16-src\java\org\apache\catalina\connector\Connector.java中的源码。
URIEncoding:
指定用于解码URI所用的字符集。 如果未指定,Tomat 9.0将使用UTF-8,除非org.apache.catalina.STRICT_SERVLET_COMPLIANCE系统属性设置为true,在这种情况下将使用ISO-8859-1。
useBodyEncodingForURI
这指定了contentType中指定的编码是否应该用于URI查询参数,而不是使用URIEncoding。 此设置用于与Tomcat 4.1.x兼容,其中在contentType中指定的编码或使用Request.setCharacterEncoding方法显式设置的编码也用于URL中的参数。 默认值为false。
注意:1)此设置仅应用于请求的查询字符串。 与URIEncoding不同,它不会影响请求URI的路径部分。 2)如果请求字符编码未知(由浏览器提供并且未由SetCharacterEncodingFilter或使用Request.setCharacterEncoding方法的类似过滤器设置),则默认编码始终为“ISO-8859-1”。 URIEncoding设置对此默认设置没有影响。
怎么处理字符编码问题
2.1 怎样改变GET参数的解码?
Tomcat将使用ISO-8859-1作为整个URL的默认字符编码,包括查询字符串(“GET参数”)。
有两种方法可以指定如何解释GET参数:
1. 将server.xml中<Connector>元素上的URIEncoding属性设置为特定的(例如URIEncoding =“UTF-8”)。
2. 将server.xml中<Connector>元素的useBodyEncodingForURI属性设置为true。 这将导致Connector使用请求正文的GET参数编码。
从Tomat 8开始,<Connector>元素上的URIEncoding属性的默认值取决于“strict servlet compliance”设置。 URIEncoding的默认值是UTF-8(strict servlet compliance=false)。 如果启用了“strict servlet compliance=true”,则默认值为ISO-8859-1。
2.2 怎样改变POST参数的解码?
POST请求应指定它们发送的参数和值的编码。由于许多客户端没有显式编码,因此当ContentType为application-x-www-form-urlencoded时,使用US-ASCII解码POST请求,当ContentType为其它类型时,使用ISO-8859-1解码POST请求。
然而,servlet规范要求,ContentType 为application / x-www-form-urlencoded的请求,URI默认解释为ISO-8859-1。但是,HTML 5 推荐使用UTF-8对URI进行编码,并且很多的浏览器都是用UTF-8对URI进行编码的。可见,servlet规范与实际的实现存在冲突。
尽管如此,servlet规范要求servlet容器对ContentType为application / x-www-form-urlencoded的URI的解释遵循任何已配置的字符编码。因此,通过将请求字符编码设置为UTF-8,可以实现对application / x-www-form-urlencoded字节序列的适当解释(见Servlet 4.0 3.12节)。
即在应用程序中的web.xml中设置 <request-character-encoding>UTF-8<request-character-encoding>
或设置一个charsetEncoding 的filter,指定request的解码方式。也可以在Tomcat安装配置文件conf / web.xml中定义这样的过滤器,该文件将在所有Web应用程序中设置请求字符编码,而无需任何web.xml修改。事实上,最新的Tomcat版本附带了conf / web.xml中的部分,这些部分已经配置了一个过滤器,用于将请求字符编码设置为UTF-8。只需编辑conf / web.xml并取消注释名为setCharacterEncodingFilter的过滤器的定义和映射。
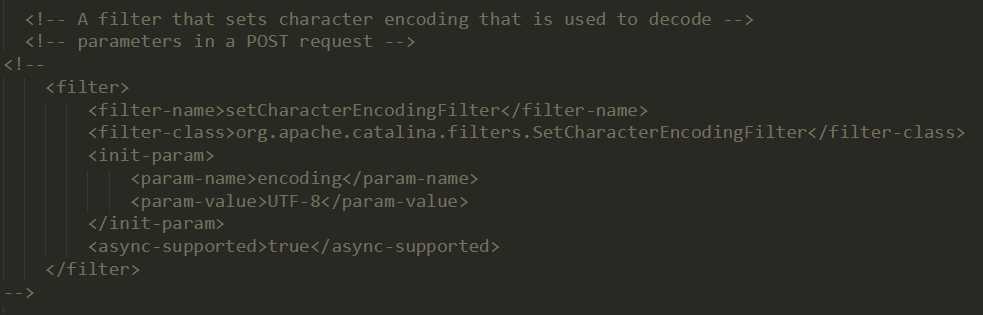
tips: setCharacterEncodingFilter.java源码在apache-tomcat-9.0.16-src\java\org\apache\catalina\filters。
注意:request编码设置仅在解析参数之前完成时才有效。一旦解析发生,就没有办法回来了。参数解析由请求参数名称或值的第一个方法触发。确保过滤器位于要求请求参数的任何其他过滤器之前。定位取决于WEB-INF / web.xml文件中过滤器映射声明的顺序,但是由于Servlet 3.0规范还有其他选项来控制顺序。要检查实际的顺序,可以从页面中抛出异常并检查其堆栈跟踪以获取过滤器名称。
2.3 如何在任何地方使用UTF-8。
使用UTF-8作为一切的字符编码是一个安全的选择。 这应该适用于几乎所有情况。
1. 在server.xml中的<Connector>上设置URIEncoding =“UTF-8”。
2. 在Tomcat conf / web.xml文件或web app web.xml文件中设置默认请求字符编码;通过设置<request-character-encoding>或使用字符编码过滤器。
3. 更改所有JSP以在其contentType中包含charset名称。例如,对于通常的JSP页面使用<%@ page contentType =“text / html; charset = UTF-8”%>,使用<jsp:directive.page contentType =“text / html; charset = UTF-8”/>对于XML语法中的页面。
4. 更改所有servlet以设置响应的内容类型,并在内容类型中包含charset name为UTF-8。使用response.setContentType(“text / html; charset = UTF-8”)或response.setCharacterEncoding(“UTF-8”)。
5. 更改您使用的任何内容生成库(Velocity,Freemarker等)以使用UTF-8并在其生成的响应的内容类型中指定UTF-8。
6. 在字符编码过滤器或jsp页面有机会将编码设置为UTF-8之前,禁用可能读取请求参数的任何Valves或filter。
2.4 怎样测试配置是否正常工作?
<%@ page contentType="text/html; charset=UTF-8" %>
<!-- 表单的数据编码与页面的编码相同, 对于这个JSP,是UTF-8-->
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>Character encoding test page</title>
</head>
<body>
<p>Data posted to this form was:
<%
/* 在解码参数前,设置用什么字符集解码参数 */
request.setCharacterEncoding("UTF-8");
/* 解码数据 */
out.print(request.getParameter("mydata"));
%>
</p>
<form method="POST" action="testEncoding.jsp">
<input type="text" name="mydata">
<input type="submit" value="Submit" />
<input type="reset" value="Reset" />
</form>
</body>
</html>
URI编码总结 ========================== 在URI中有两种情况使用非US-ASCII字符: - GET方法中的查询字符串 - Servlet的路径 URI的标准编码在 (https://en.wikipedia.org/wiki/Percent-encoding#Percent-encoding_in_a_URI) ,
但是这个标准并不是所有客户端一贯遵循的,因此导致很多问题。
Tomcat提供五一些功能解决这种不太理想的情况 1. Coyote HTTP/1.1连接器具有useBodyEncodingForURI属性,如果设置为true,则使用请求主体编码来解码URI查询参数。
-Tomat9.0.16的默认值为false;
2. Coyote HTTP/1.1 connector 有一个URIEncoding属性,默认值是UTF-8。
3. 关于请求的类(o.a.t.u.http.Parameters)有一个queryStringEncoding 属性,默认值是UTF-8的值。
必须在解码参数前设置此字段方可生效。
servlet API中需要注意的问题:
1. HttpServletRequest.setCharacterEncoding()只能应用于request的实体正文request body)而不是URI。
2. HttpServletRequest.getPathInfo() 由Web容器解码。
3. HttpServletRequest.getRequestURI() 不是由容器解码。
tips:
1. 在表单中使用POST提交参数,这样参数就会是请求正文的一部分标签:pathinfo rfc 内容类型 val 收件人 xml语法 doctype reset 发送请求
原文地址:https://www.cnblogs.com/yvkm/p/10551484.html