标签:生成 reverse encoding 文本 tin 文本文件 ever open pre
!pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba
import jieba
str="在神兽白泽的陪同下,游览大千世界,揭秘诸神奥妙。从凯尔特的神话世界出发,北欧、埃及、希腊、希伯来、印度、九州……无尽神话历史,无数神魔鬼怪,无穷世界隐秘,为您呈现……"
for v in jieba.cut(str):
print(v)
中文词频统计
1.下载一长篇中文小说。
2.从文件读取待分析文本。
3. 安装并使用jieba进行中文分词。
pip install jieba
import jieba
ljieba.lcut(text)
4. 更新词库,加入所分析对象的专业词汇。
jieba.add_word(‘天罡北斗阵‘) #逐个添加
jieba.load_userdict(word_dict) #词库文本文件
5. 生成词频统计
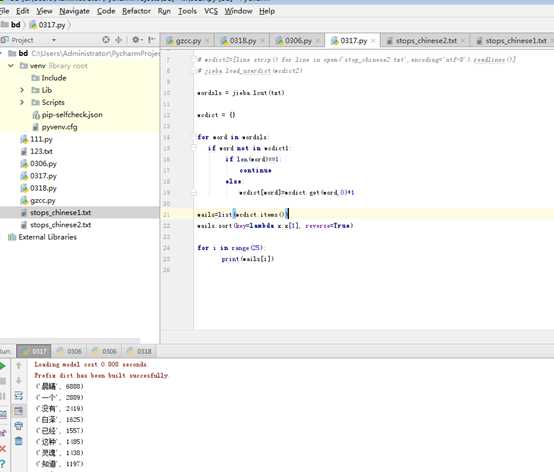
import jieba
txt=open(r‘stops_chinese1.txt‘,‘r‘,encoding=‘utf-8‘).read()
wcdict1=[line.strip() for line in open(‘stops_chinese2.txt‘,encoding=‘utf-8‘).readlines()]
jieba.load_userdict(wcdict1)
# wcdict2=[line.strip() for line in open(‘stop_chinese2.txt‘,encoding=‘utf-8‘).readlines()]
# jieba.load_userdict(wcdict2)
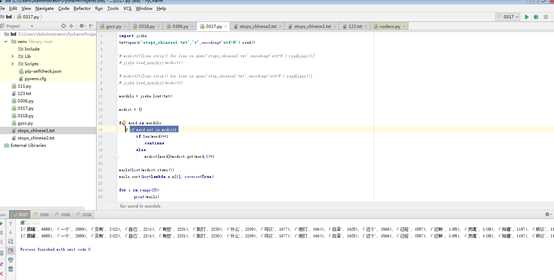
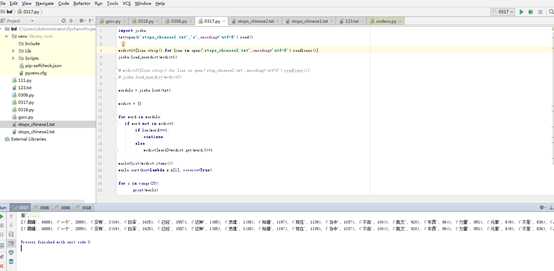
wordsls = jieba.lcut(txt)
wcdict = {}
for word in wordsls:
if word not in wcdict1:
if len(word)==1:
continue
else:
wcdict[word]=wcdict.get(word,0)+1
wails=list(wcdict.items())
wails.sort(key=lambda x:x[1], reverse=True)
for i in range(25):
print(wails)
6. 排序
7. 排除语法型词汇,代词、冠词、连词
8. 输出词频最大TOP25,把结果存放到文件里
9. 生成词云。
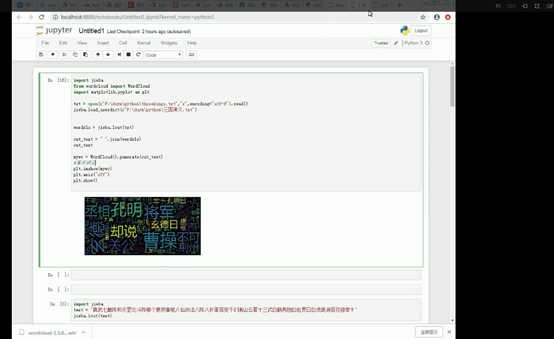
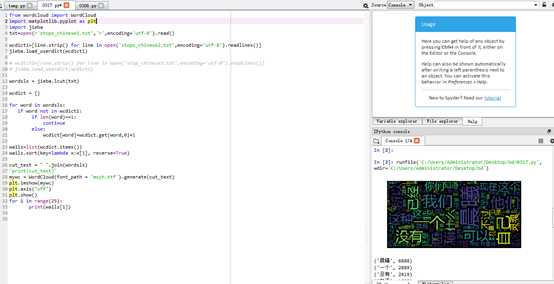
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
txt=open(r‘stops_chinese1.txt‘,‘r‘,encoding=‘utf-8‘).read()
wcdict1=[line.strip() for line in open(‘stops_chinese2.txt‘,encoding=‘utf-8‘).readlines()]
jieba.load_userdict(wcdict1)
# wcdict2=[line.strip() for line in open(‘stop_chinese2.txt‘,encoding=‘utf-8‘).readlines()]
# jieba.load_userdict(wcdict2)
wordsls = jieba.lcut(txt)
wcdict = {}
for word in wordsls:
if word not in wcdict1:
if len(word)==1:
continue
else:
wcdict[word]=wcdict.get(word,0)+1
wails=list(wcdict.items())
wails.sort(key=lambda x:x[1], reverse=True)
cut_text = " ".join(wordsls)
‘print(cut_text)‘
mywc = WordCloud(font_path = ‘msyh.ttf‘).generate(cut_text)
plt.imshow(mywc)
plt.axis("off")
plt.show()
for i in range(25):
print(wails[i])
附:
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
text_from_file_with_apath = open(‘/Users/hecom/23tips.txt‘).read()
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all = True)
wl_space_split = " ".join(wordlist_after_jieba)
my_wordcloud = WordCloud().generate(wl_space_split)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
标签:生成 reverse encoding 文本 tin 文本文件 ever open pre
原文地址:https://www.cnblogs.com/lijiajie/p/10553704.html