标签:空间 虚拟内存 www creating 完成 天都 vfork ref 传递
因为生活的复杂,这是一个并行的世界,在同一时刻,会发生很多奇妙的事情,北方下雪,南方下雨,这里在吃饭,那边在睡觉,有人在学习,有人在运动,所以这时一个多彩多姿的世界,每天都发生着很多事情,所以要想很好的表现这个世界,协调完成一件事儿,就得用到多进程或者多线程。所以进程是程序猿一定会接触到的一个东西,他能使我们的程序效率提高,高效的完成多任务,并行执行。下面主要看看产生进程或线程的三个函数。
fork,vfork,clone都是linux的系统调用,这三个函数分别调用了sys_fork、sys_vfork、sys_clone,最终都调用了do_fork函数,差别在于参数的传递和一些基本的准备工作不同,主要用来linux创建新的子进程或线程(vfork创造出来的是线程)。
进程的四要素:
(1)有一段程序供其执行(不一定是一个进程所专有的),就像一场戏必须有自己的剧本。
(2)有自己的专用系统堆栈空间(私有财产)
(3)有进程控制块(task_struct)(“有身份证,PID”)
(4)有独立的存储空间。
缺少第四条的称为线程,如果完全没有用户空间称为内核线程,共享用户空间的称为用户线程。
一、fork()
fork()函数调用成功:返回两个值; 父进程:返回子进程的PID;子进程:返回0;
失败:返回-1;
fork 创造的子进程复制了父亲进程的资源(写时复制技术),包括内存的内容task_struct内容(2个进程的pid不同)。这里是资源的复制不是指针的复制。
说到fork(),就不得不说一个技术:(Copy-On-Write)写时复制技术。
盗用一张图,感觉描述的确实挺到位:
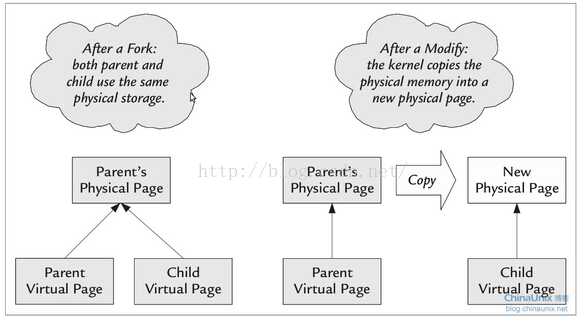
我们都知道fork创建进程的时候,并没有真正的copy内存(听着好像矛盾了,资源的赋值为什么有没有真正的赋值呢?),因为我们知道,对于fork来讲,有一个很讨厌的东西叫exec系列的系统调用,它会勾引子进程另起炉灶。如果创建子进程就要内存拷贝的的话,一执行exec,辛辛苦苦拷贝的内存又被完全放弃了。由于fork()后会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,处于效率考虑,linux中引入了“写时复制技术-Copy-On-Write”。
换言之,在fork()之后exec之前两个进程用的是相同的物理空间(内存区),先把页表映射关系建立起来,并不真正将内存拷贝。子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。当父进程中有更改相应段的行为发生时,如进程写访问,再为子进程相应的段分配物理空间,如果不是因为exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。fork时子进程获得父进程数据空间、堆和栈的复制所以变量的地址(当然是虚拟地址)是一样的。
具体过程是这样的:
fork子进程完全复制父进程的栈空间,也复制了页表,但没有复制物理页面,所以这时虚拟地址相同,物理地址也相同,但是会把父子共享的页面标记为“只读”,如果父子进程一直对这个页面是同一个页面,直到其中任何一个进程要对共享的页面“写操作”,这时内核会复制一个物理页面给这个进程使用,同时修改页表。而把原来的只读页面标记为“可写”,留给另外一个进程使用。这就是所谓的“写时复制”。
在理解上:可以认为fork后,这两个相同的虚拟地址指向的是不同的物理地址,这样方便理解父进程之间的独立性。
但实际上,linux为了提高fork的效率,采用了copy-on-write技术,fork后,这两个虚拟地址实际上指向相同的物理地址。(内存页),只有任何一个进程试图修改这个虚拟地址里的内容前,两个虚拟地址才会指向不同的物理地址。新的物理地址的内容从源物理地址中复制得到。
问题:fork采用了这种写时复制的机制,那么fork出来子进程后,理论上子进程和父进程那个先调度呢(理论效率分析,个人觉得有一定的道理)?
fork之后内核一般会通过将子进程放在队列的前面,以让子进程先执行,因为很多情况下子进程要马上执行exec,会清空栈、堆,这些和父进程共享的空间,加载新的代码段。。这就避免了父进程“写时复制”拷贝共享页面的机会。如果父进程先调度很可能写共享页面,而子进程什么也没做,会产生“写时复制”的无用功。所以,一般子进程先调度。避免因无意义的复制而造成效率的下降。
下面来看一个例子:
#include"stdio.h"
int main()
{
int count = 1;
int child;
if(0== fork()) //子进程成功返回0;
{ //开始创建子进程
printf("This is son, his count is: %d. and his pid is: %d\n", ++count, getpid());//子进程的内容
}
else
{
printf("This is father, his count is: %d, his pid is: %d\n", count, getpid());
}
}
运行结果:
从结果可以看出子进程和父进程的PID不同,内存资源count是值得复制,子进程改变了count的值,而父进程中的count没有被改变。有人认为这样大批量的复制会导致执行效率过低。其实在复制过程中,子进程复制了父进程的task_struct,系统堆栈空间和页面表,这意味着上面的程序,我们没有执行count++前,其实子进程和父进程的count指向的是同一块内存。而当子进程改变了父进程的变量时候,会通过copy_on_write的手段为所涉及的页面建立一个新的副本。所以当我们执行++count后,这时候子进程才新建了一个页面复制原来页面的内容,基本资源的复制是必须的,而且是高效的。整体看上去就像是父进程的独立存储空间也复制了一遍。这将和下面的vfork有一定的区别。
其次,我们看到子进程和父进程直接没有互相干扰,明显2者资源都独立了。我们看下面程序
#include"stdio.h"
int main() {
int count = 1;
int child;
int i;
if(!(child = fork()))
{
for(i = 0; i <20; i++)
{
printf("This is son, his count is: %d. and his pid is: %d\n", i, getpid());
}
}
else
{
for(i=0;i<20;i++)
printf("This is father, his count is: %d, his pid is: %d\n", count, getpid());
}
}
运行结果:
从运行的结果可以看出父子2个进程是同步运行的,其实不分先后。
二、vfork()
vfork是一个过时的应用,vfork也是创建一个子进程,但是子进程共享父进程的空间。在vfork创建子进程之后,父进程阻塞,直到子进程执行了exec()或者exit()。vfork最初是因为fork没有实现COW机制,而很多情况下fork之后会紧接着exec,而exec的执行相当于之前fork复制的空间全部变成了无用功,所以设计了vfork。而现在fork使用了COW机制,唯一的代价仅仅是复制父进程页表的代价,所以vfork不应该出现在新的代码之中。
vfork创建出来的不是真正意义上的进程,而是一个线程,因为它缺少经常要素(4),独立的内存资源,看下面的程序:
#include "stdio.h"
int main() {
int count = 1;
int child;
printf("Before create son, the father‘s count is:%d\n", count);
if(!(child = vfork()))
{
printf("This is son, his pid is: %d and the count is: %d\n", getpid(), ++count);
exit(1);
}
else
{
printf("After son, This is father, his pid is: %d and the count is: %d, and the child is: %d\n", getpid(), count, child);
}
}
运行结果:
从运行结果可以看到vfork创建出的子进程(线程)共享了父进程的count变量,这一次是指针复制,2者的指针指向了同一个内存,所以子进程修改了count变量,父进程的 count变量同样受到了影响。
另外由vfork创建的子进程要先于父进程执行,子进程执行时,父进程处于挂起状态,子进程执行完,唤醒父进程。除非子进程exit或者execve才会唤起父进程,看下面程序:
#include "stdio.h"
int main()
{
int count = 1;
int child;
printf("Before create son, the father‘s count is:%d\n", count);
if(!(child = vfork()))
{
int i;
for(i = 0; i < 100; i++)
{
printf("This is son, The i is: %d\n", i);
count++;
if(i == 20)
{
printf("This is son, his pid is: %d and the count is: %d\n", getpid(), ++count);
exit(1);
}
}
}
else
{
printf("After son, This is father, his pid is: %d and the count is: %d, and the child is: %d\n", getpid(), count, child);
}
}
运行结果:
从运行的结果可以看到父进程总是等子进程执行完毕后才开始继续执行。
3.clone
clone是Linux为创建线程设计的(虽然也可以用clone创建进程)。所以可以说clone是fork的升级版本,不仅可以创建进程或者线程,还可以指定创建新的命名空间(namespace)、有选择的继承父进程的内存、甚至可以将创建出来的进程变成父进程的兄弟进程等等。
clone函数功能强大,带了众多参数,它提供了一个非常灵活自由的常见进程的方法。因此由他创建的进程要比前面2种方法要复杂。clone可以让你有选择性的继承父进程的资源,你可以选择想vfork一样和父进程共享一个虚存空间,从而使创造的是线程,你也可以不和父进程共享,你甚至可以选择创造出来的进程和父进程不再是父子关系,而是兄弟关系。先有必要说下这个函数的结构:
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);
fn为函数指针,此指针指向一个函数体,即想要创建进程的静态程序(我们知道进程的4要素,这个就是指向程序的指针,就是所谓的“剧本", );
child_stack为给子进程分配系统堆栈的指针(在linux下系统堆栈空间是2页面,就是8K的内存,其中在这块内存中,低地址上放入了值,这个值就是进程控制块task_struct的值);
arg就是传给子进程的参数一般为(0);
flags为要复制资源的标志,描述你需要从父进程继承那些资源(是资源复制还是共享,在这里设置参数:
下面是flags可以取的值
标志 含义
CLONE_PARENT 创建的子进程的父进程是调用者的父进程,新进程与创建它的进程成了“兄弟”而不是“父子”
CLONE_FS 子进程与父进程共享相同的文件系统,包括root、当前目录、umask
CLONE_FILES 子进程与父进程共享相同的文件描述符(file descriptor)表
CLONE_NEWNS 在新的namespace启动子进程,namespace描述了进程的文件hierarchy
CLONE_SIGHAND 子进程与父进程共享相同的信号处理(signal handler)表
CLONE_PTRACE 若父进程被trace,子进程也被trace
CLONE_VFORK 父进程被挂起,直至子进程释放虚拟内存资源
CLONE_VM 子进程与父进程运行于相同的内存空间
CLONE_PID 子进程在创建时PID与父进程一致
CLONE_THREAD Linux 2.4中增加以支持POSIX线程标准,子进程与父进程共享相同的线程群
下面的例子是创建一个线程(子进程共享了父进程虚存空间,没有自己独立的虚存空间不能称其为进程)。父进程被挂起当子线程释放虚存资源后再继续执行。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <sched.h>
#define FIBER_STACK 8192
int a;
void * stack;
int do_something(){
a=10;
printf("This is son, the pid is:%d, the a is: %d\n", getpid(), a);
free(stack);
exit(1);
}
int main() {
void * stack;
a = 1;
stack = malloc(FIBER_STACK);//为子进程申请系统堆栈
if(!stack) {
printf("The stack failed\n");
exit(0);
}
printf("creating son thread!!!\n");
clone(&do_something, (char *)stack + FIBER_STACK, CLONE_VM|CLONE_VFORK, 0);//创建子线程
printf("This is father, my pid is: %d, the a is: %d\n", getpid(), a);
exit(1);
}
运行的结果:
son的PID:10692;
father的PID:10691;
parent和son中的a都为10;所以证明他们公用了一份变量a,是指针的复制,而不是值的复制。
问题:clone和fork的区别:
(1) clone和fork的调用方式很不相同,clone调用需要传入一个函数,该函数在子进程中执行。
(2)clone和fork最大不同在于clone不再复制父进程的栈空间,而是自己创建一个新的。 (void *child_stack,)也就是第二个参数,需要分配栈指针的空间大小,所以它不再是继承或者复制,而是全新的创造。
博客资料参考:
http://blog.csdn.net/xy010902100449/article/details/44851453
http://www.cnblogs.com/blankqdb/archive/2012/08/23/2652386.html
http://blog.chinaunix.net/uid-24774106-id-3361500.html
http://www.linuxidc.com/Linux/2015-03/114888.htm
http://igaozh.iteye.com/blog/1677969
http://blog.chinaunix.net/uid-24410388-id-195503.html
http://blog.chinaunix.net/uid-18921523-id-265538.html
http://blog.csdn.net/wdjhzw/article/details/25614969
感谢各位博主的分享!
---------------------
作者:尘虚緣_KY
来源:CSDN
原文:https://blog.csdn.net/gogokongyin/article/details/51178257
版权声明:本文为博主原创文章,转载请附上博文链接!
标签:空间 虚拟内存 www creating 完成 天都 vfork ref 传递
原文地址:https://www.cnblogs.com/guxuanqing/p/10556759.html