标签:方式 sorted for ops 输出 das 计数 lambda 文件
1.列表,元组,字典,集合分别如何增删改查及遍历。
列表_增加 list = [‘a‘, ‘b‘, 5564, ‘c‘] print ("原始列表 : ", list) list.append(‘3658‘) print ("增加元素 : ", list)

列表_删除: list = [‘a‘, ‘b‘, 5564, ‘c‘] print ("原始列表 : ", list) del list[2] print ("删除第三个元素 : ", list)

列表_修改 list = [‘a‘, ‘b‘, 5564, ‘c‘] print ("原始列表 : ", list) list[2] = ‘d‘ print ("修改第三个元素 : ", list)
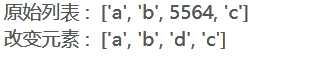
列表_查询 list = [‘a‘, ‘b‘, 5564, ‘c‘] print ("原始列表 : ", list) print ("第三个元素为 : ", list[2])

元组_增加 list1 = (‘a‘, ‘b‘, 5564, ‘c‘) list2 = (‘d‘, ‘e‘) print ("原始列表 : ", list1) list1 += list2 print ("增加后列表 : ", list1)

元组_删除 del list1; 会将整个元组删除。。
元组_修改
元组中的元素值是不允许修改的
元组_查询 list = (‘a‘, ‘b‘, 5564, ‘c‘,‘d‘, ‘e‘) print ("原始列表 : ", list) print ("查询第三个元素 : ", list[2]) print ("查询倒数第三个元素 : ", list[-2]) print ("查询第三个到第五个元素 : ", list[2:4])

字典_增加 dict1 = {‘a‘: ‘b‘, ‘c‘: 5564} dict2 = {‘d‘: ‘e‘ } dict1.update(dict2) print ("将字典 dict2 加入字典 dict1 : ", dict1)
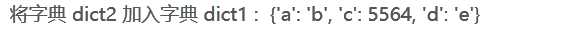
字典_删除 dict = {‘a‘: ‘b‘, ‘c‘: 5564} print ("原始字典 dict : ", dict) del dict[‘a‘] # 删除键 ‘a‘ print ("删除字典 dict 键 ‘a‘ : ", dict) dict.clear() # 清空字典 del dict # 删除字典

字典_修改 dict = {‘a‘: ‘b‘, ‘c‘: 5564} print ("原始字典 dict : ", dict) dict[‘a‘] = 1 print ("修改字典 dict 键 ‘a‘ 的值: ", dict)
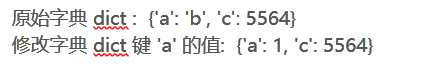
字典_查询 dict = {‘a‘: ‘b‘, ‘c‘: 5564} print ("原始字典 dict : ", dict) print ("查询字典 dict 键 ‘a‘ 的值: ", dict[‘a‘])
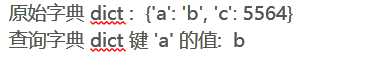
集合_增加 JH = {‘a‘, ‘b‘, ‘c‘, 5564} print ("原始集合 JH : ", JH) JH.add(‘d‘) print ("添加‘d’: ", JH)
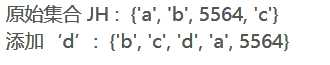

集合_查询 JH = {‘a‘, ‘b‘, ‘c‘, 5564} print ("原始集合 JH : ", JH) print ("查询‘b’: ", ‘b‘ in JH)

2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
列表:方括号,有序,可变,可重复,通过下标查找
元组:小括号,有序,不可变,可重复,通过下标查找
字典:花括号,无序,可变,不可重复,通过key查找
集合:花括号,无序,可变,可重复,可用in查找元素是否在集合内
3.词频统计
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
8.输出TOP(20)
排序好的单词列表word保存成csv文件
import pandas as pd
pd.DataFrame(data=word).to_csv(‘big.csv‘,encoding=‘utf-8‘)
线上工具生成词云:
https://wordart.com/create
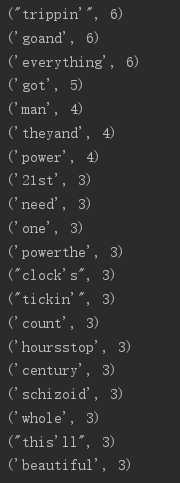
XinXi = open(r"..\bd\venv\GeCi\geci.txt",‘r‘,encoding="utf8") Stop = open(r"..\bd\stops.txt",‘r‘) stops = Stop.read() GeCi= XinXi.read() XinXi.close() Stop.close() GeCi_ist = GeCi.replace(‘\n‘, ‘‘).replace(‘,‘, ‘‘).replace(‘(‘, ‘‘).replace(‘)‘, ‘‘).lower().split() stops1 = stops.replace(‘\n‘, ‘‘).replace(‘,‘, ‘‘).replace(‘"‘, ‘‘).lower().split() stops2 = stops.replace(‘\n‘, ‘‘).replace(‘,‘, ‘‘).replace(‘"‘, ‘‘).replace("‘", ‘‘).lower().split() ZiDian = {} for str in GeCi_ist: if str in ZiDian.keys(): ZiDian[str] = ZiDian[str] + 1 else: ZiDian[str] = 1 del ZiDian["\ufeffi‘m"] for x in stops2: ZiDian.pop(x,"") for x in stops1: ZiDian.pop(x,"") ZiDian = sorted(ZiDian.items(),key=lambda x:x[1],reverse=True) for i in ZiDian[0:20]: print(i) import pandas as pd pd.DataFrame(data=ZiDian).to_csv(r‘C:\Users\14537\Desktop\1234.csv‘, encoding=‘utf-8‘)
top20:
词云:

标签:方式 sorted for ops 输出 das 计数 lambda 文件
原文地址:https://www.cnblogs.com/qiannuohan/p/10562058.html