标签:name 根据 姓名 扫描 数据量 形式 bre 更新 getc
---恢复内容开始---
Collection集合的特点是每次进行单个对象的保存,那么如果现在要进行一对对象的保存(偶对象)就只能使用Map集合来完成,所以Map集合中会一次性保存两个,两个对线的关系:Key=value的结构,那么这种结构最大的特点是可以通过Key找到对应value内容。观察Map接口定义:
public interface Map<K,V>
在Map接口里面有如下几个方法:
向集合中追加数据:V put(K key,V value)
根据key取得对应的value如果没有key返回null:V get(Object key)
取得所有key的信息,key不能重复:Set<K> keySet()
取得所有的value 不关注内容是否重复:Collection<V> values()、
将我们的Map集合变为Set集合:Set<Map.Entry<K,V>> entrySet()
Map本身是一个接口,要使用Map必须通过子类来进行实例化对象,而子类有:HashMap,Hashtable,TreeMap,ConcurrentHashMap四个常用子类
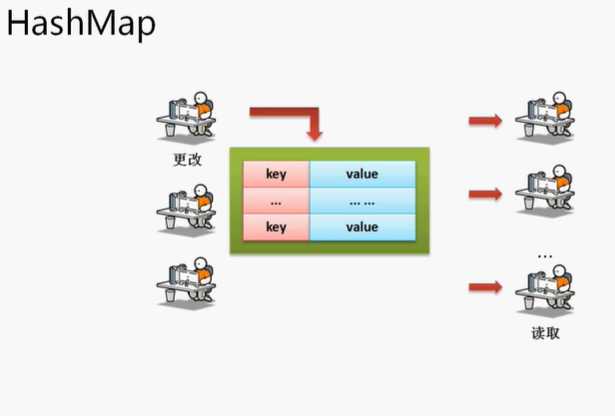
HashMap是在使用Map集合里面最为常用的一个子类了,下面先通过HashMap进行一个Map的使用操作
范例:Map的基本处理
1 package cn.Tony.demo; 2 3 import java.util.HashMap; 4 import java.util.Map; 5 6 public class TestDemo{ 7 public static void main(String[] args) throws Exception { 8 Map<Integer,String> map=new HashMap<Integer,String>(); 9 map.put(1, "Hello"); 10 map.put(1, "World");//key重复了 11 map.put(2, "Tony"); 12 System.out.println(map); 13 System.out.println(map.get(1)); 14 System.out.println(map.get(99)); 15 16 } 17 }
范例:取得Map中的所有key的信息
1 package cn.Tony.demo; 2 import java.util.HashMap; 3 import java.util.Iterator; 4 import java.util.Map; 5 import java.util.Set; 6 public class TestDemo{ 7 public static void main(String[] args) throws Exception { 8 Map<Integer,String> map=new HashMap<Integer,String>(); 9 map.put(1, "Hello"); 10 map.put(1, "World");//key重复了 11 map.put(2, "Tony"); 12 Set<Integer> set=map.keySet();//取得所有key 13 Iterator<Integer> iter=set.iterator(); 14 while(iter.hasNext()) { 15 Integer key=iter.next(); 16 System.out.println(key+"="+map.get(key)); 17 } 18 } 19 }
此种操作没有任何实际意义,只是为了功能使用的说明,因为这样的输出处理复杂度太高。
面试题:请解释HashMap的原理
在数据量小的时候HashMap是按照链表的模式存储的。将数据量变大之后为了进行快速的查找,那么会将这个链表变为一个红黑树(均衡二叉树),用hash码作为数据的定位来保存的。
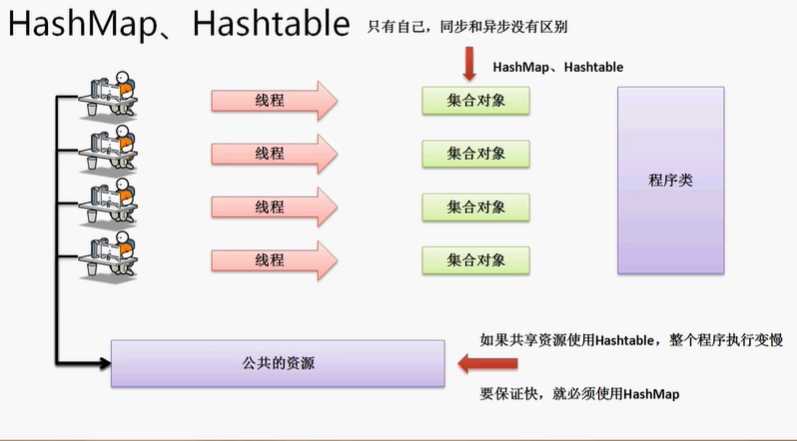
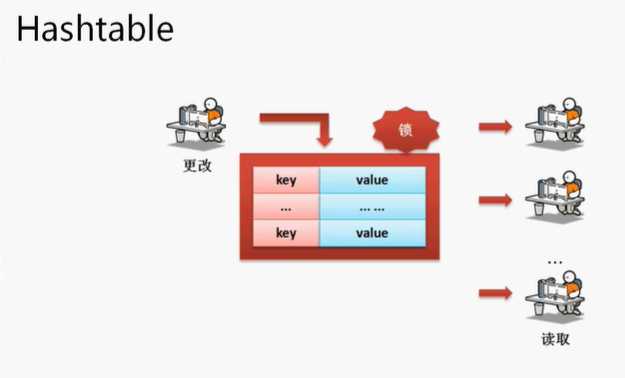
Hashtable子类(1%)
JDK1.0提供有三大主要类:Vector,Enumeration,Hashtable。Hashtable是最早实现这种二元偶对象数据结构,后期设计的时候也让其Vector一样多实现了Map接口而已
范例:观察Hashtable
1 package cn.Tony.demo; 2 import java.util.Hashtable; 3 import java.util.Map; 4 public class TestDemo{ 5 public static void main(String[] args) throws Exception { 6 Map<Integer,String> map=new Hashtable<Integer,String>(); 7 map.put(1, "Hello"); 8 map.put(1, "World");//key重复了 9 map.put(2, "Tony"); 10 System.out.println(map); 11 } 12 }
面试题:请解决HashMap与Hashtable的区别?

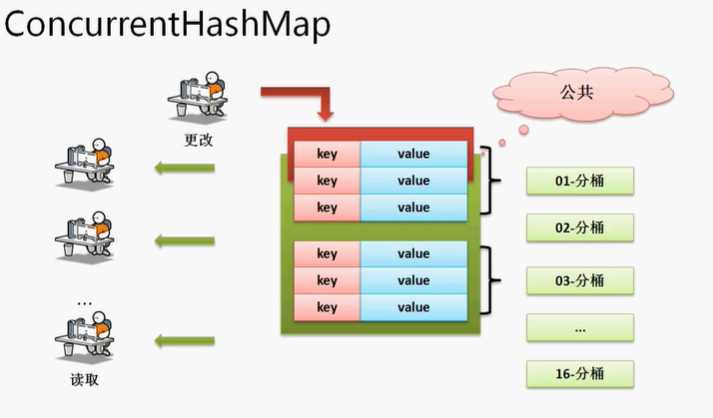
ConcurrentHashMap子类()
ConcurrentHashMap的特点=Hashtable的线程安全性+HashMap的高性能,在使用ConcurrentHashMap处理的时候既可以多个线程更新数据的同步,又可以保证高效的查询速度。
首先观察ConcurrentHashMap的子类定义:
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V> implements ConcurrentMap<K,V>, Serializable
范例:使用ConcurrentHashMap
1 package cn.Tony.demo; 2 import java.util.Map; 3 import java.util.concurrent.ConcurrentHashMap; 4 5 public class TestDemo{ 6 public static void main(String[] args) throws Exception { 7 Map<Integer,String> map=new ConcurrentHashMap<Integer,String>(); 8 map.put(1, "Hello"); 9 map.put(1, "World");//key重复了 10 map.put(2, "Tony"); 11 System.out.println(map); 12 } 13 }
于是现在就需要分析一下ConcurrentHashMap的工作原理
如果说现在采用一定的算法,将保持的大量数据平均分在不同的桶(数据区域 ),这样在进行数据查找的时候就可以避免掉这种全部的数据扫描。
范例:数据分桶
1 package cn.Tony.demo; 2 import java.util.Random; 3 4 public class TestDemo{ 5 public static void main(String[] args) throws Exception { 6 for(int x=0;x<10;x++) { 7 new Thread(() -> { 8 Random rand=new Random(); 9 int temp=rand.nextInt(9999); 10 int result=temp%3; 11 switch(result) { 12 case 0: 13 System.out.println("第【0】桶"+temp); 14 break; 15 case 1: 16 System.out.println("第【1】桶"+temp); 17 break; 18 case 2: 19 System.out.println("第【2】桶"+temp); 20 break; 21 } 22 }).start(); 23 } 24 25 } 26 }
采用了分桶之后没一个数据中必须有一个明确的分桶的标记,很明显使用hashCode()。
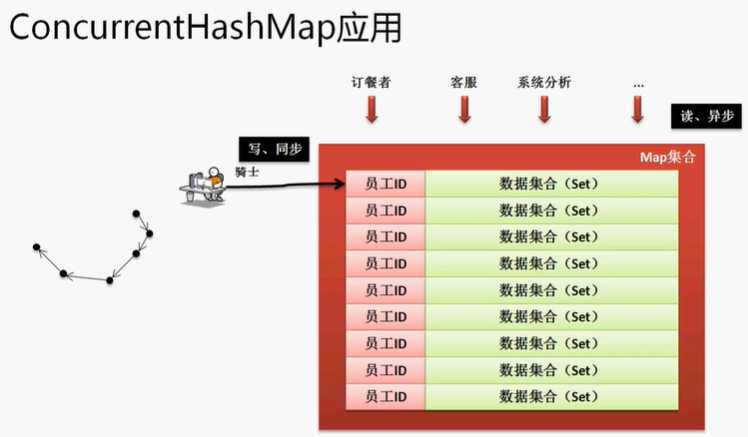
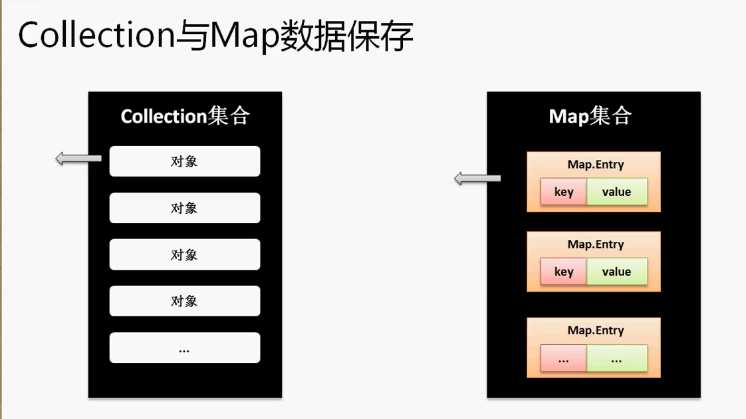
在实际开发中,如果你存储数据是为了输出,那么优先考虑的一定是Collection 使用Map的主要操作就是设置内容,而后通过get()进行查找的。使用Map迭代输出的需求会有,但是不多,不过你们必须会,如果要想观察输出首先必须明确一点,Map接口没有Iterator()方法,通过一个简答的图形来观察Collection和Map保存数据的模型。
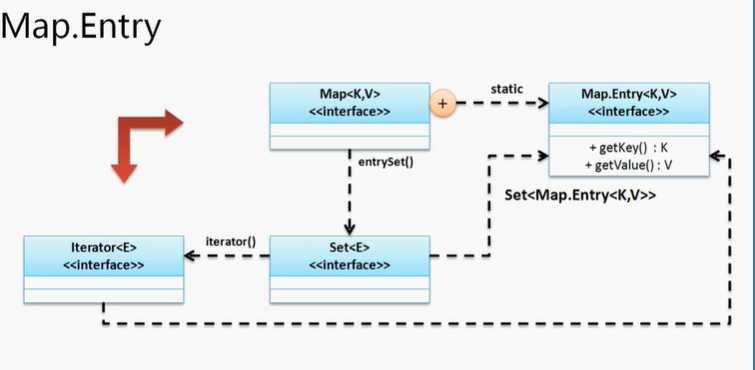
在Map接口里面有一个重要的方法,将Map集合转为Set集合:public Set<Map.Entry<K,V>>entrySet();
范例:通过Iterator输出Map集合
1 package cn.Tony.demo; 2 3 import java.util.HashMap; 4 import java.util.Iterator; 5 import java.util.Map; 6 import java.util.Map.Entry; 7 import java.util.Set; 8 9 public class TestDemo{ 10 public static void main(String[] args) throws Exception { 11 Map<Integer,String> map=new HashMap<Integer,String>(); 12 map.put(1, "Hello"); 13 map.put(2, "World"); 14 //1.将Map集合变为Set集合 15 Set<Entry<Integer,String>> set=map.entrySet(); 16 //2.实例化Iterator接口 17 Iterator<Entry<Integer,String>> iter=set.iterator(); 18 while(iter.hasNext()) {//3.迭代输出,取出每一个Map Entry对象 19 Map.Entry<Integer, String> me=iter.next();//取出Map.Entry 20 System.out.println(me.getKey()+"="+me.getValue()); 21 } 22 } 23 }
以上的形式相比较Collection(List Set)而言出现的几率不高,但是依然需要我们熟悉
Map中的key实现说明
在使用Map集合的时候之前使用的都是系统类作为了KEY(Integer),那么实际上用户也可以采用自定义的类作为Key() 这个时候一定要记得覆写Object类中的hashCode与equals方法
1 package cn.Tony.demo; 2 3 import java.util.HashMap; 4 import java.util.Map; 5 6 class Person{ 7 private String name; 8 public Person(String name) { 9 this.name=name; 10 } 11 @Override 12 public String toString() { 13 return "姓名:"+this.name; 14 } 15 @Override 16 public int hashCode() { 17 final int prime = 31; 18 int result = 1; 19 result = prime * result + ((name == null) ? 0 : name.hashCode()); 20 return result; 21 } 22 @Override 23 public boolean equals(Object obj) { 24 if (this == obj) 25 return true; 26 if (obj == null) 27 return false; 28 if (getClass() != obj.getClass()) 29 return false; 30 Person other = (Person) obj; 31 if (name == null) { 32 if (other.name != null) 33 return false; 34 } else if (!name.equals(other.name)) 35 return false; 36 return true; 37 } 38 } 39 40 public class TestDemo{ 41 public static void main(String[] args) throws Exception { 42 Map<Person,String> map=new HashMap<Person,String>(); 43 map.put(new Person("张三"), new String("zs")); 44 System.out.println(map.get(new Person("张三"))); 45 } 46 }
因为从实际的开发来讲,对于Map集合中的key的类型不是使用String就是Integer,浙西系统类都帮助用户覆写好hashCode equals方法了
TreeMap表示可以排序的Map子类,它是按照key的内容来进行排序的
范例:观察使用
1 public class TestDemo{ 2 public static void main(String[] args) throws Exception { 3 // Map<Person,String> map=new HashMap<Person,String>(); 4 // map.put(new Person("张三"), new String("zs")); 5 // System.out.println(map.get(new Person("张三"))); 6 Map<Integer,String> map=new TreeMap<Integer,String>(); 7 map.put(2, "C"); 8 map.put(0, "X"); 9 map.put(1, "B"); 10 System.out.println(map); 11 } 12 }
这个时候的排序处理依然按照的是Comparable接口完成的。
总结:
1.Collection保存数据是为了输出,Map保存输出目的是为了根据Key查找 找不到的Key返回null
2.Map使用Iterator输出(Map.Entry的作用)
3.一些类的设计原理,这些是在你面试到的,开发就使用HashMap
---恢复内容结束---
标签:name 根据 姓名 扫描 数据量 形式 bre 更新 getc
原文地址:https://www.cnblogs.com/Tony98/p/10568871.html