标签:简单的 layer 概率 社交 rop 依赖 smi 本质 strong
一. 研究背景
药物研发领域,利用已知药物和靶标蛋白的相互作用关系建模。针对特定疾病的蛋白质可以找到与之作用的高亲和力的药物。传统方法考虑分子结构之间的相互对接,这依赖于药物分子和蛋白质的化学作用。
本项目基于深度学习,挖掘药物分子和蛋白质之间的相互作用关系,通过特征提取和组和来完成。
二. 数据集及其描述
本项目完成关于药物分子和靶蛋白之间的亲和力预测。属于一个(二分类问题),使用的数据集来源于BinDing DB。它提供了药物分子的结构(一种SMILES字符串),靶蛋白提供其氨基酸序列(字符串)以及两者之间的亲和力度量标准IC50,该数据集包含33777个正例、27493个负例。根据IC50的大小讲例子进行标签,>10000标记为0,其余为1.
数据处理:
1、原始药物分子的数据为SMILES字符串,本项目中,利用图卷积网络对其进行输入空间的映射。即完成原始数据到原始向量的映射
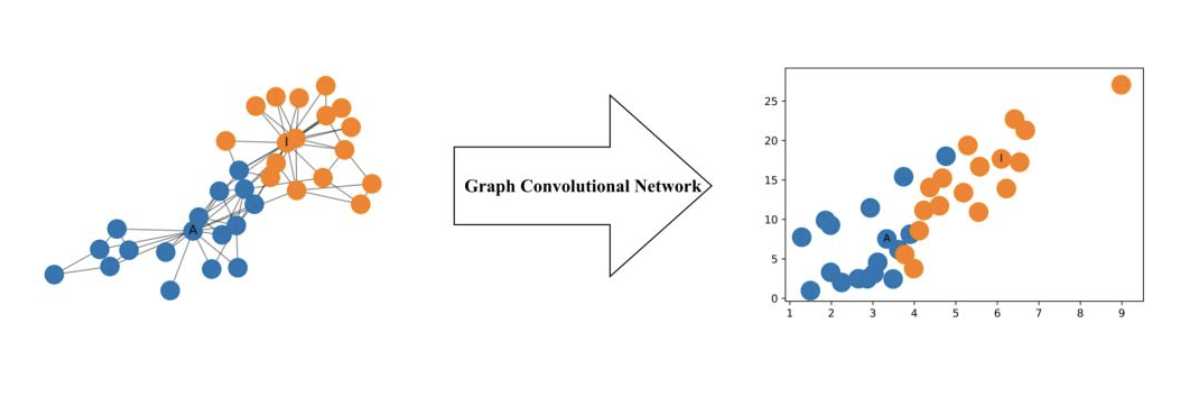
1. 图卷积模型
CNN处理具有欧几里得结构的图像具有很好的效果,而对于图数据,考虑其节点和边都包含了信息,因而其用CNN网络处理不是十分合适,而图卷积网络就是处理这一问题:
更形式化地说,图卷积网络(GCN)是一个对图数据进行操作的神经网络。给定图 G = (V, E),GCN 的输入为:
一个输入维度为 N × F? 的特征矩阵 X,其中 N 是图网络中的节点数而 F? 是每个节点的输入特征数。
一个图结构的维度为 N × N 的矩阵表征,例如图 G 的邻接矩阵 A。
f(H?, A) = σ(AH?W?)
而其中的A作为每一次传播的共享权值。
考虑到分子结构中,节点之间如果有连接,那么应该是相互作用的,因而将其作为无向图处理。进而考虑分子大小,因为药物分子大小不一,对其进行子图选取,即对每一张药物分子图选取100个节点,因而输入时100个节点的特征矩阵:[100 * 7],矩阵A[100 *100],
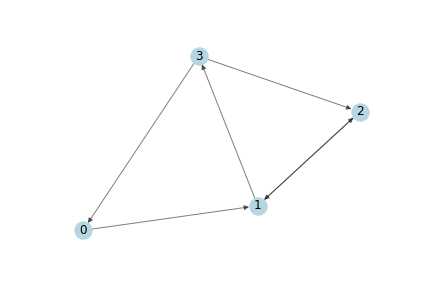
2. 节点处理举例
图卷积思考点:
1、在初期,考虑到图卷积网络的输入的为自生成的结点描述,考虑到这种这种特征描述可能不够准确,因而在组合网络中,没有对图卷积网络设置自生成的特征作为输出来生出此部分的loss function而直接在模型中进行训练。考虑到在利用空手道俱乐部训练集做GCN的测试时,一层的网络就将该社交网络处理的很好,因而初步考虑使用两层的网络层应该就很很好地完成原始图到输入空间的映射。输出层维度为400
2、经过初步试验,考虑到初期没有考虑图卷积网络那一块单独的loss function,在后期,加入其损失函数(均方误差),此时网络层变成3层,取中间网络层的维度400作为实例的输入空间向量。此处理使得准确率有了一定的提高。
但是为什么呢?(佛系炼丹)
2、靶蛋白氨基酸序列到输入向量的处理,在这一部分,由于对这一部分没有太深的了解,又考虑到已经有了专门的处理软件,因而使用Moreau-Briti Autocorrelation Descriptor,一种被称为拓扑结构自相关描述子的软件提取氨基酸序列特征,其维度为240.
考虑到,药物分子和靶细胞之间的作用,其本质是物理拓扑结构和之间各种物理力之间的作用(虽然我不太清楚是啥力),这也就是意味着对于400维度的药物输入、240维的靶蛋白输入。
思虑至此,考虑到可以直接搭建网络层进行训练了,又考虑到两层的网络层就可以拟合任何的函数,所以觉得网络层应该不用太深。
补充说明:为什么神经网络理论上可以拟合任何函数?
从一个很简单的方向解释:
一、逻辑函数:
1,直观理解:
1个感知机可模拟与或非3种运算,3个感知机组成包含1个隐层的感知机网络(姑且称其为网络吧)可以模拟异或运算。因此,理论上,神经网络可模拟任意组合的逻辑函数。
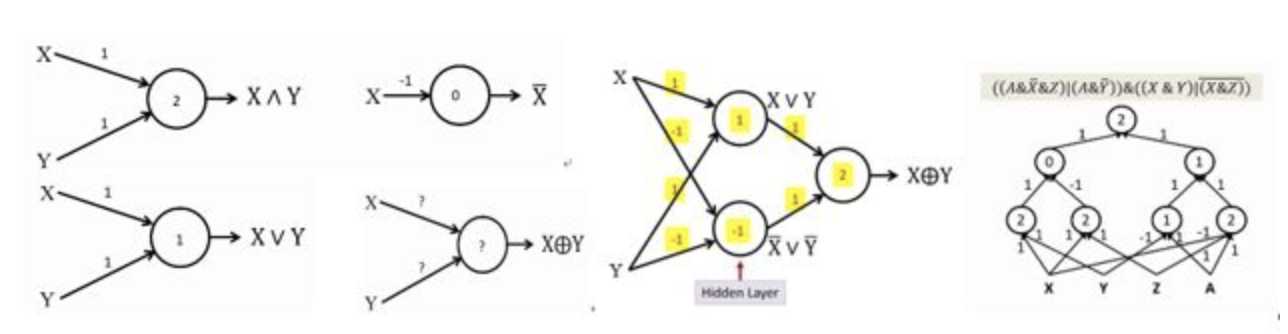
2,浅显理论:
“真值表+DNF公式”:“任意布尔运算均可通过真值表穷举,真值表每一行对应DNF公式的每一项,DNF公式的每一项对应网络隐含层的每一个节点”。因此,理论上,一层感知机网络,即可表示通用布尔运算函数。
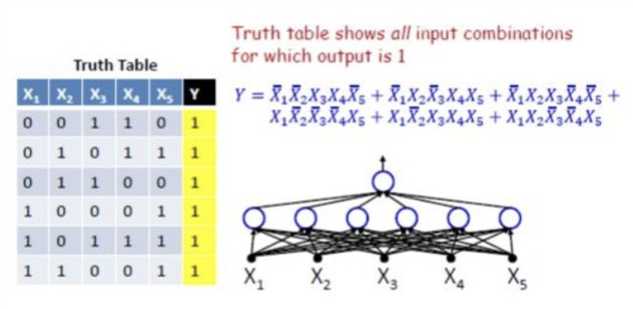
解释完毕(还有更多的解释)
根据上述思想,开始设计网络框架,输入层为药物分子的400维,氨基酸序列240维,即每个样例输入为640维。三层全连接层,一个输出层,(输出类别1被描述为0.99,输出类别0被描述为0.01)。三层维度分别为1000、500、250,损失函数采用均方误差,使用L2正则化、十折交叉验证防止过拟合,在此操作下次,ACC在0.74波动。在此基础上,对网络层进行了加深、加宽等一系列操作,但是效果都不明显。考虑到在物理学中功 = FS,即两者的内积,对其进行对比,药物分子和药靶蛋白的结合,除了双方结构的互补,更重要的是其中其中的隐含的各种力之间的相互作用,因此可以利用分别训练两个网络,讲网络的最后一层做内积运算,再将其利用sigmoid函数映射到0-1的概率上,或许会取得更好的效果。至此,想到了利用一个混合模型来进行训练,在此基础上,效果显而易见,提高到了ACC0.86波动,之后,考虑到输入层维度过大、又需要提取其中的隐变量(各种未知的物理、化学力)
既然想到降维,又对隐变量的提取,自然而然就想到了自编码器。
Auto encoder:
1、对药物分子,使用5层的hidden layer,将400维的输入空间向量降维到100维,(1000*500*100*500*1000)
2、对氨基酸序列,使用5层的hidden layer,将240位的输入空间向量降维到50维(并提取其中特征1000*500*50*500*1000)
至此,整个神经网络框架搭建完毕:
使用图卷积网络对药物分子处理获取输入空间向量,为获取其隐变量,利用自编码器分别对药物分子和氨基酸序列降维,之后分别建立两个网络对其进行特征处理,分别获得25维的输出,对其进行内积计算,将其结果进行sigmoid,整个网络框架为混合网络,loss function为图卷积网络、自编码器、分类器的loss叠加,再加上L2正则化防止过拟合,最后获得ACC 0.92的成果,其AUC更是达到0.96.
PS:使用dropout
标签:简单的 layer 概率 社交 rop 依赖 smi 本质 strong
原文地址:https://www.cnblogs.com/rzw8023/p/10572101.html