标签:class cte stat 开始 statistic 使用 字母 首字母 大于
ROC曲线是Receiver operating characteristic curve的简称,中文名为“受试者工作特征曲线”。ROC曲线源于军事领域,横坐标为假阳性率(False positive rate,FPR),纵坐标为真阳性率(True positive rate,TPR).
假阳性率 FPR = FP/N ---N个负样本中被判断为正样本的个数占真实的负样本的个数
真阳性率 TPR = TP/P ---P个正样本中被预测为正样本的个数占真实的正样本的个数
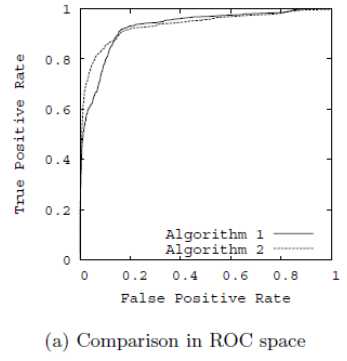
ROC曲线是通过不断移动分类器的“截断点”来生成曲线上的一组关键点的,“截断点”指的就是区分正负预测结果的阈值。
通过动态地调整截断点,从最高的得分开始,逐渐调整到最低得分,每一个截断点都会对应一个FPR和TPR,在ROC图上绘制出每个截断点对应的位置,再连接所有点就得到最终的ROC曲线。
AUC是一个模型评价指标,只能用于二分类模型的评价,对于二分类模型,还有很多其他评价指标,比如logloss,accuracy,precision。为什么AUC和logloss比accuracy更常用呢?因为很多机器学习的模型对分类问题的预测结果都是概率,如果要计算accuracy,需要先把概率转化成类别,这就需要手动设置一个阈值,如果一个样本的预测概率高于这个预测,就把这个样本放进一个类别里面,低于这个阈值,放进另一个类别里面。所以这个阈值很大程度上影响了accuracy的计算,使用AUC或logloss可以避免把预测概率转换成类别。
AUC是Area under curve的首字母缩写,从字面上理解,就是ROC曲线下的面积大小,该值能够量化地反映基于ROC曲线衡量出的模型性能。由于ROC曲线一般都处于y=x这条直线的上方(如果不是的话,只要把模型预测的概率反转成1-p就可以得到一个更好的分类器),所以AUC的取值一般在0.5-1之间。AUC越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。
举例:5个样本,真实的类别(标签)是
| y | 1 | 1 | 0 | 0 | 1 |
| p | 0.5 | 0.6 | 0.55 | 0.4 | 0.7 |
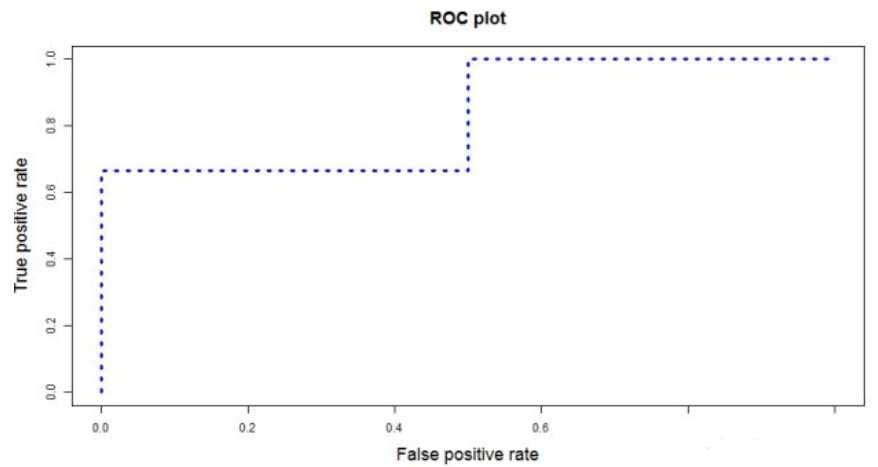
如文章一开始多说,我们需要选定阈值才能把概率转化为类别,选定不同的阈值会得到不同的结果。如果我们选定的阈值为0.1,那5个样本被分进1的类别,如果选定0.3,结果仍然一样。如果选了0.45作为阈值,那么只有样本4被分进0,其余都进入1类。一旦得到了类别,我们就可以计算相应的真、伪阳性率,当我们把所有计算得到的不同真、伪阳性率连起来,就画出了ROC曲线。
python代码如下:
from sklearn import metrics
def aucfun(act,pred):
fpr,tpr,thresholds = metrics.roc_curve(act,pred,pos_label=1)
return metrics.auc(fpr,tpr)
从Mann-Whitney U statistic的角度来解释,AUC就是从所有1样本中随机选取一个样本,从所有0样本中随机选取一个样本,然后根据你的分类器对两个随机样本进行预测,把1样本预测为1的概率为p1,把0样本预测为1的概率为p0,p1>p0的概率就等于AUC。所以,AUC反应的是分类器对样本的排序能力。根据这个解释,如果我们完全随机的对样本进行分类,那么AUC应该接近0.5,另外,AUC对样本类别是否均衡并不敏感,这也是不均衡样本通常用AUC评价分类器性能的一个原因。
AUC是指随机给定一个正样本和一个负样本,分类器输出该正样本为正的概率值比分类器输出该负样本为正的概率值要大的可能性。
详细解释如下: 随机抽取一个样本,对应每一潜在可能值X都对应有一个判定位正样本的概率P。
对一批已知正负的样本集合进行分类。
按概率从高到矮排序,对于正样本中概率最高的,排序为rank_1,比它概率小的有M-1个正样本(M为正样本个数),(rank_1-M)个负样本。
正样本概率第二高的,排序为rank_2,比它概率小的有M-2个正样本,(rank_2-M+1)个负样本。
以此类推,正样本中概率最小的,排序为rank_M,比它概率小的有0个正样本,rank_M-1个负样本。
总共有M*N个正负样本对(N为负样本个数)。把所有比较中,正样本概率大于负样本概率的例子都算上,得到公式(rank_1-M+rank_2-M+1...+rank_M-1)/(M*N)就是正样本概率大于负样本概率的可能性了。化简后得:【离散情况下】
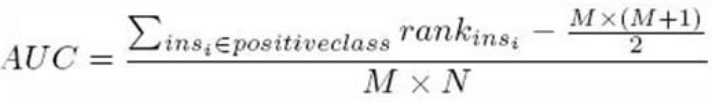
这只是用于理解,具体计算时需要考虑rank平列的情况。
当正负样本的分布发生变化时,ROC曲线的形状能够基本保持不变,而P-R曲线的形状一般会发生较剧烈的变化。ROC能够尽量降低不同测试集带来的干扰,更加客观的衡量模型本身的性能。如果研究者希望更多地看到模型在特定数据集上的表现,P-R曲线能够更直观地反映其性能。
标签:class cte stat 开始 statistic 使用 字母 首字母 大于
原文地址:https://www.cnblogs.com/nxf-rabbit75/p/10586643.html