标签:blog http io ar 使用 strong sp 文件 数据
接上篇
3.Combiner操作
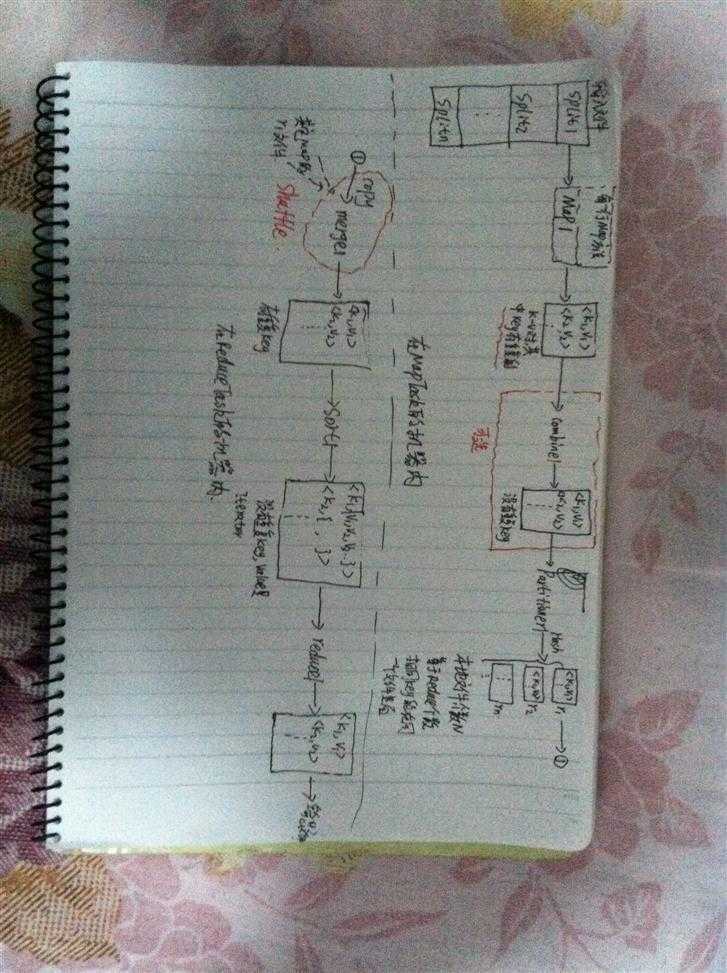
前面讲完Map操作,总结一下就是:一个大文件,分成split1~5,对应于Map1~5,每一个Map处理一个split,每一个split的每一行,会用每一个Map的map方法去处理,经过上面操作,最终输出了5个中间结果。
对于这5个中间结果的每一个来说,都有很多行,每一行是key value格式的,如hello 1,这样子,在传给Reducer之前,为了减少传输的数据量,可以增加一个Combiner过程,把每个中间结果进行化简。因为每个中间结果可能有相同的键值的行,如:hello 1,hello 1,通过combiner,就可以合并成一行:hello 2.
切记:Combiner是Mapper任务的一部分,紧随map方法之后。看起来类似Reduce的操作。
之后,就可以把Combiner的输出传入Reducer,而不是Map的输出传入Reducer。Combiner需要自己指定,当然也可以不写。
4.Reducer操作
Reduce操作分成了三个过程
(1)Shuffle
前面的Map或者Combiner的输出,一共有有5份中间结果,其中的每一份结果,按照Key值可以分成(预先定义的R份),由R个Reduce来操作(通过Partitioner接口完成)。因此R个Reduce需要向5个中间结果都取一段数据,5个中间结果的其中每一结果是由R个Reduce操作的。
简单来说:对于其中某一个个Reduce1来说,分别从Map1~Map5里面把需要的那一份copy至本地,然后再合并Merge一下,供Sort使用。
(2)Sort
对于每一个Reduce来说,进来的数据为5个中间结果的中的一段,即Shuffle的结果,里面可能有重复的key,因此作为Reduce输入之前,会有一个sort操作,把相同Key的整合一下,例如<hello,1>,<hello,1>整合成<hello,(1,1)>,作为Reduce的输入,所以Reduce的输入的value一般是Iterable的。
(3)Reduce
这里是我们编写程序的地方了,一共R个Reduce,就能产生R个中间结果了。
注意:shuffle、sort、Reduce是在Reduce节点完成的,而不是在Map节点完成,有些书籍上写的是错的!
啰啰嗦嗦竟然讲了这么多,上一个我自己随手画的图,凑合看吧。
============================
最近帮朋友弄了微信公众号,每天早上6点30分,发送一个60秒的语音,有兴趣的朋友不妨关注一下。
微信号:歪理邪说(wailixs)
二维码:

标签:blog http io ar 使用 strong sp 文件 数据
原文地址:http://www.cnblogs.com/wuguanglei/p/4034575.html